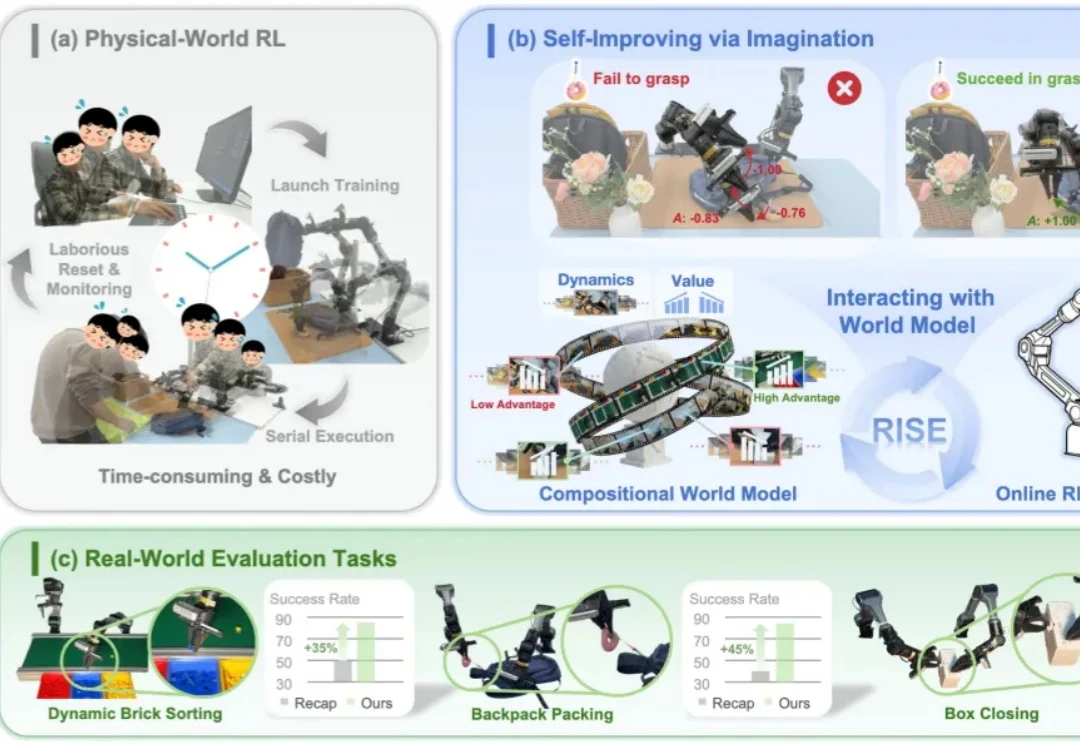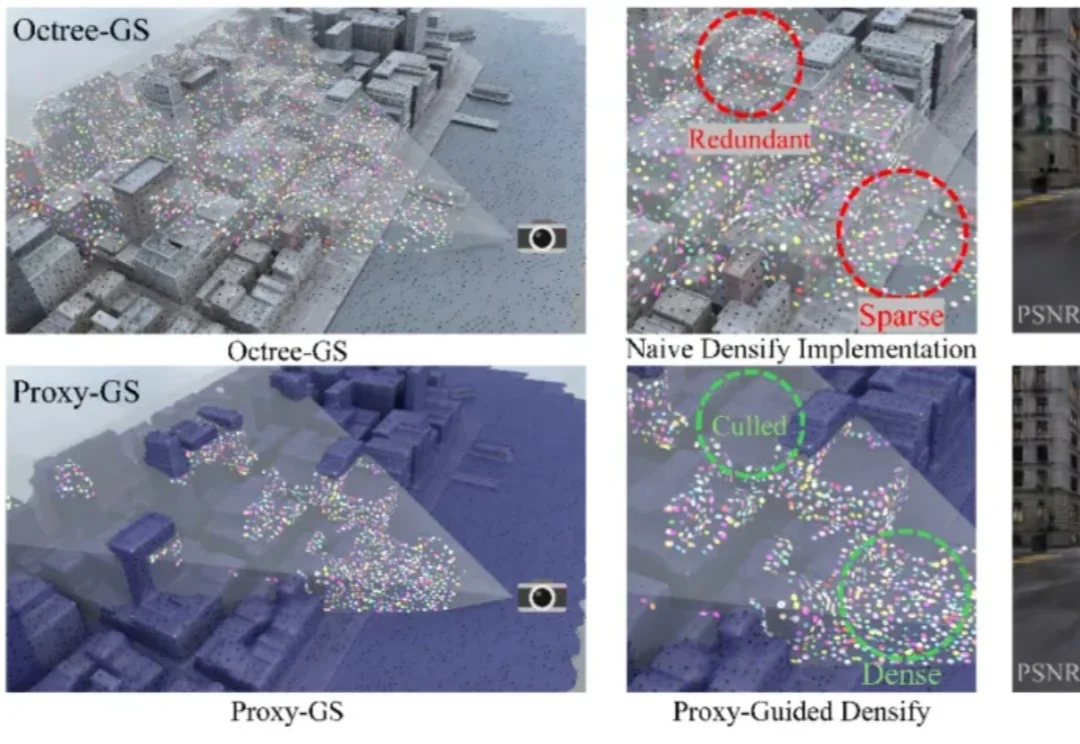
CVPR2026满分论文:Proxy-GS为结构化3D高斯溅射引入统一遮挡先验
CVPR2026满分论文:Proxy-GS为结构化3D高斯溅射引入统一遮挡先验上海交通大学钟志航团队联合上海人工智能实验室、西北工业大学、四川大学等高校在 CVPR 2026 上提出Proxy-GS(Proxy-GS: Unified Occlusion Priors for Training and Inference in Structured 3D Gaussian Splatting),面向基于 MLP 的结构化 3D 高斯溅射(3DGS),
来自主题: AI技术研报
9165 点击 2026-03-18 16:10