训练时间爆砍80%!港大快手联合打造了一个AI炼金师:专挑“有营养”数据,20%数据达成50%效果
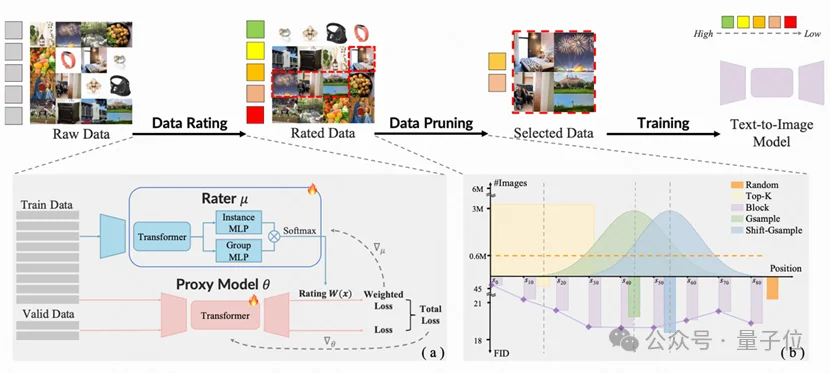
训练时间爆砍80%!港大快手联合打造了一个AI炼金师:专挑“有营养”数据,20%数据达成50%效果由香港大学丁凯欣领导,联合华南理工大学周洋以及快手科技Kling团队共同完成的这项研究,开发出了一个名为“炼金师”(Alchemist)的AI系统。它就像一位挑剔的大厨,能从海量图片数据中精准挑选出最有价值的一半。
来自主题: AI技术研报
7916 点击 2025-12-27 10:30