
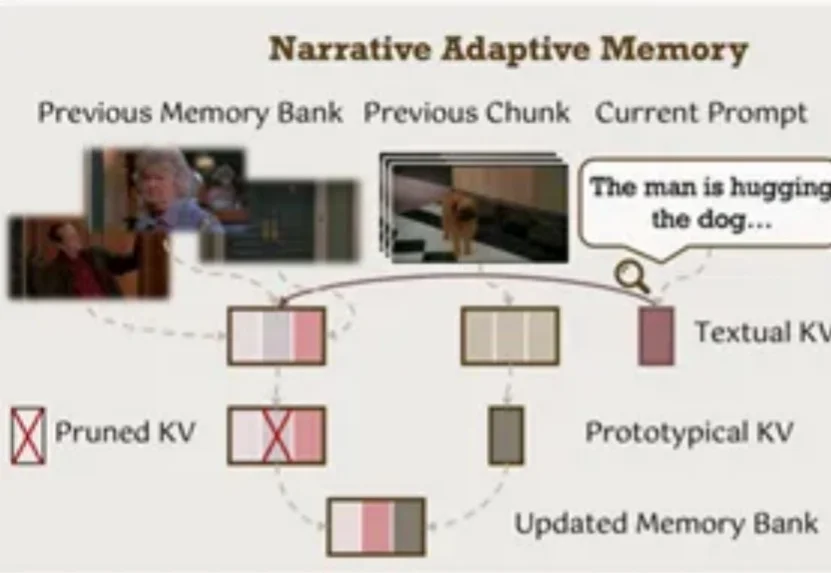
攻克长视频生成记忆难题:港大与快手可灵MemFlow设计动态自适应长期记忆,告别快速遗忘与剧情错乱
攻克长视频生成记忆难题:港大与快手可灵MemFlow设计动态自适应长期记忆,告别快速遗忘与剧情错乱你是否曾被AI视频生成的不连贯性所困扰?
来自主题: AI技术研报
7819 点击 2025-12-25 09:41
你是否曾被AI视频生成的不连贯性所困扰?
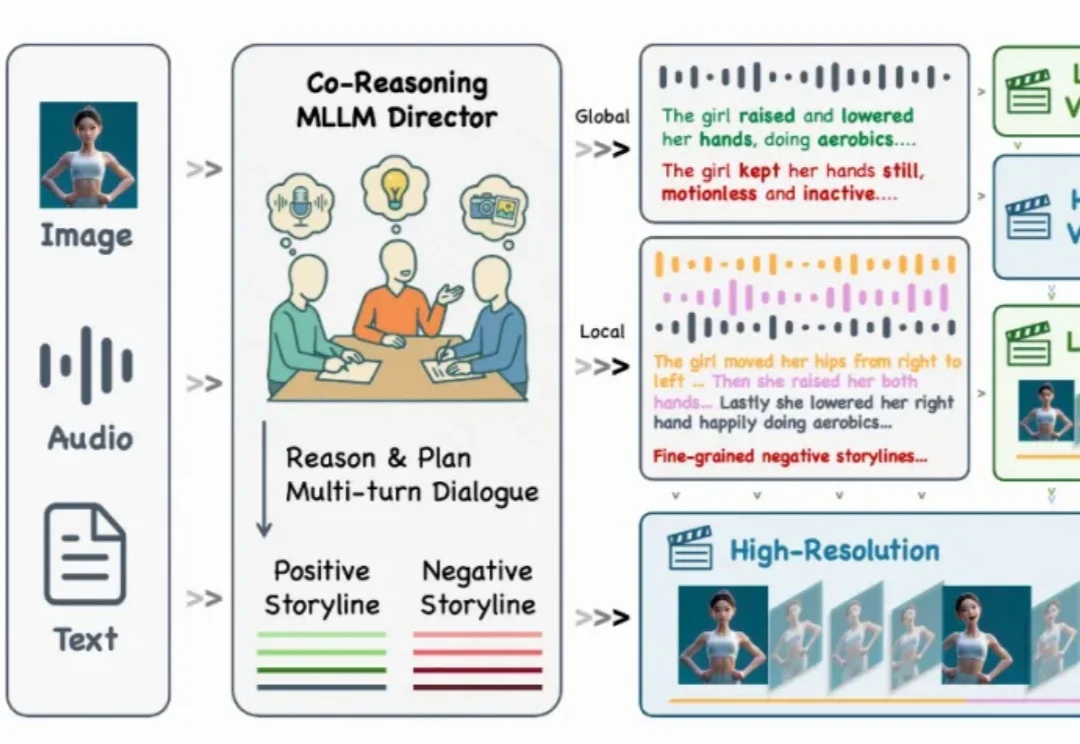
还记得几个月前那个能随着音乐节拍自然舞动的 KlingAvatar 数字人吗?现在,它迎来了史诗级进化!

今天聊一聊怎么在RAG、agent场景中实现语义高亮(Semantic Highlight)。
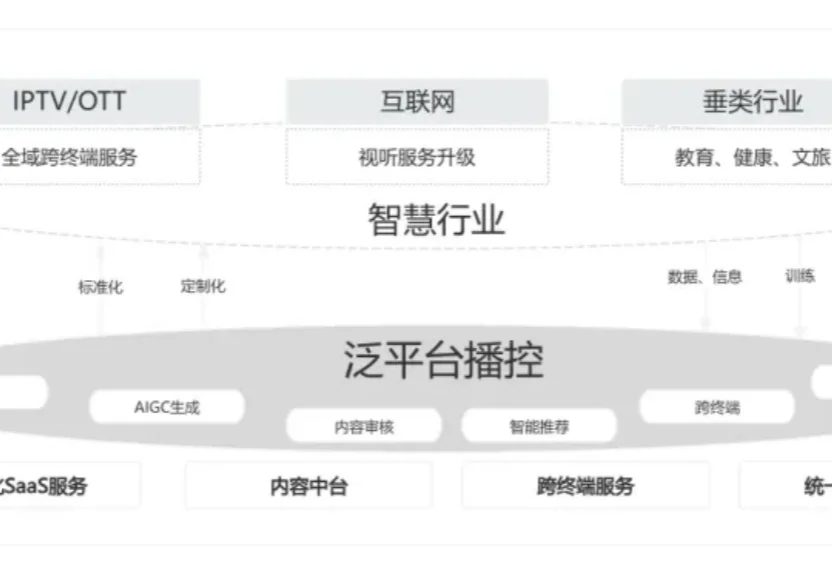
目前,传统广电行业正面临一场深刻的生存危机。外部竞争压力持续加剧,不断挤压行业原有的发展空间:家庭智能语音设备渗透率已经突破 68%,短视频平台日均占用用户时长已经高达 2.8 小时,用户注意力的结构性转移趋势已然形成。

在迈向通用人工智能的道路上,我们一直在思考一个问题:现有的 Image Editing Agent,真的「懂」修图吗?

回顾 2025 年,如果问普通人对 AI 行业最深刻的印象是什么?答案依然是激烈的“参数战争”:有 DeepSeek、Gemini 3 等大模型的集体爆发,也有文生图、文生视频能力的持续惊艳。

视频生成领域的「DeepSeek时刻」来了!清华开源TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!
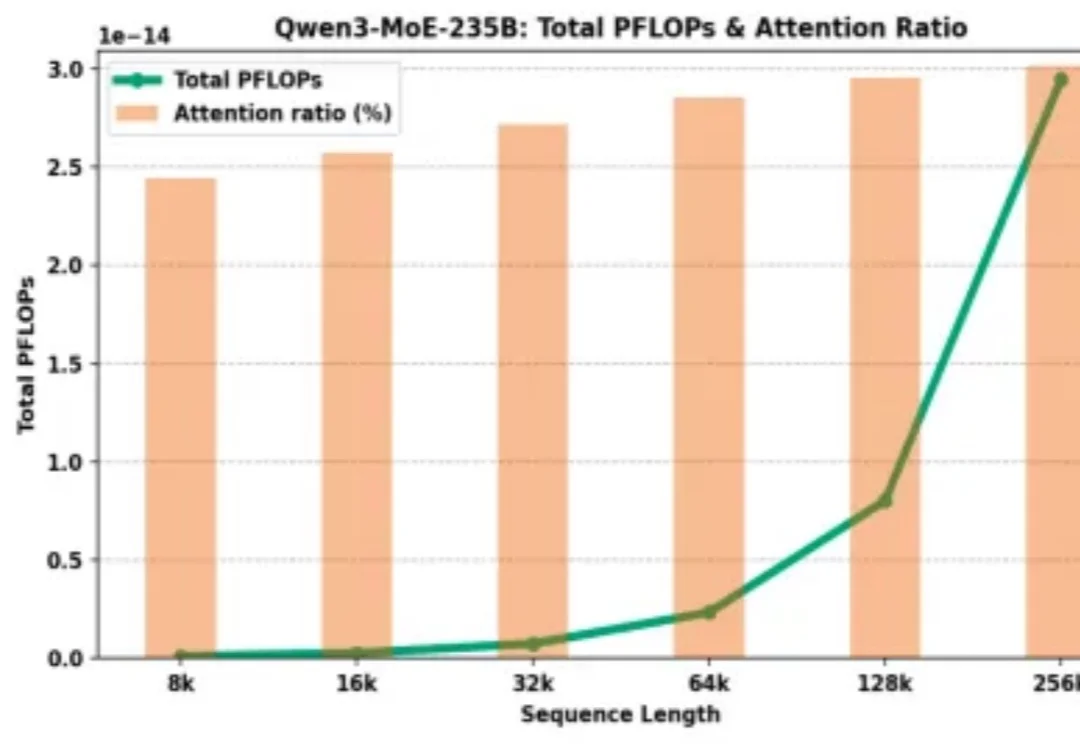
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?
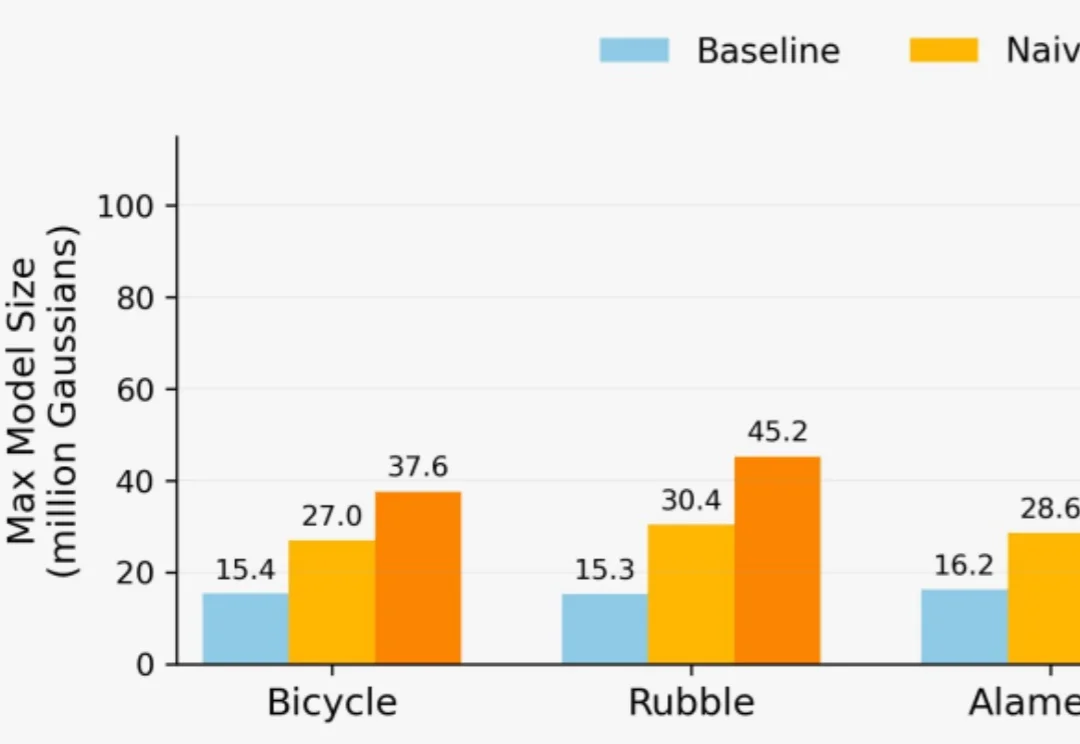
想用3D高斯泼溅(3DGS)重建一座城市?
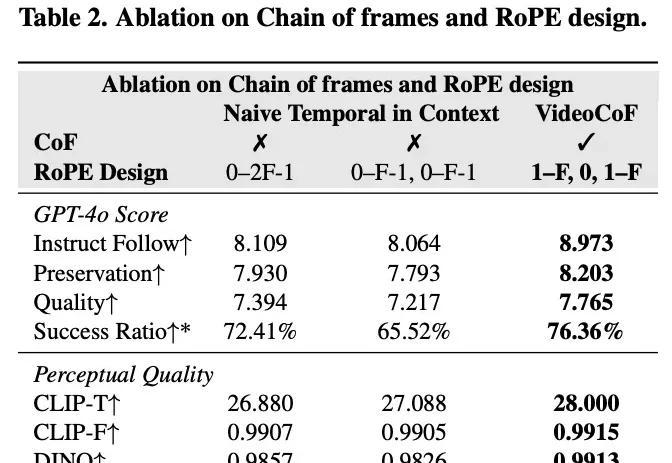
现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!