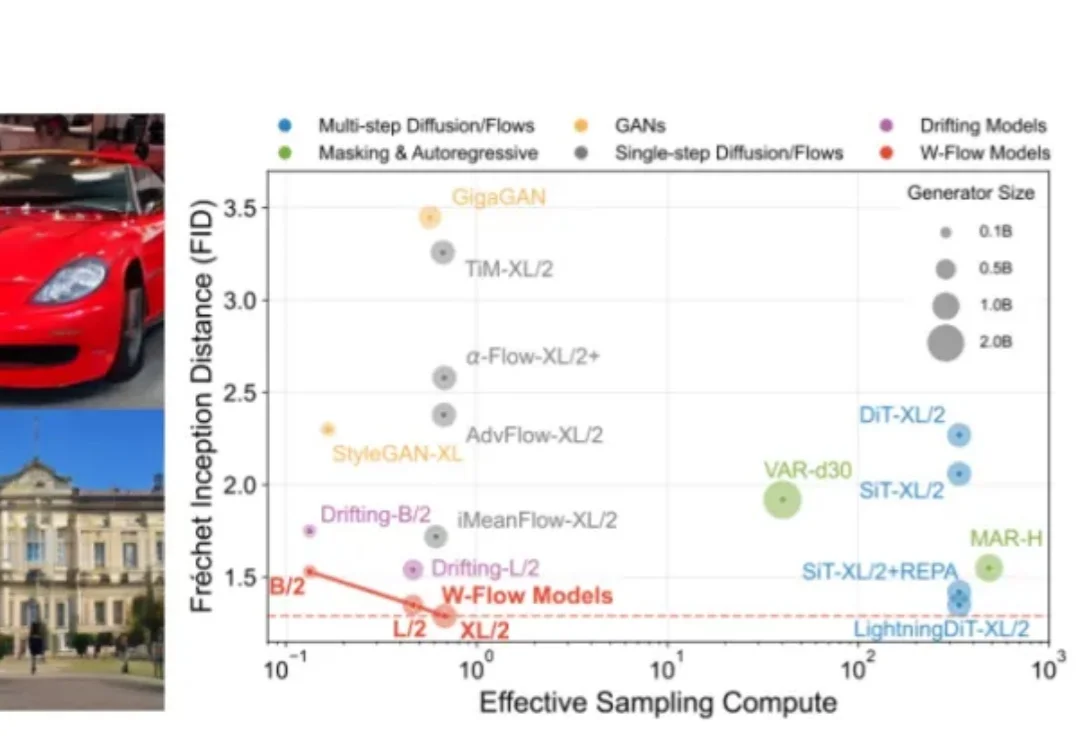
一步生成 ImageNet FID 1.29!斯坦福用 Wasserstein 梯度流重写一步生成模型
一步生成 ImageNet FID 1.29!斯坦福用 Wasserstein 梯度流重写一步生成模型训练时让分布沿最优传输的 “下山方向” 走,推理时只需一次网络前向。W-Flow 把多步演化压进静态生成器,在 ImageNet 256×256 上刷新一步生成指标。
来自主题: AI技术研报
9275 点击 2026-06-03 14:34
 搜索
搜索
训练时让分布沿最优传输的 “下山方向” 走,推理时只需一次网络前向。W-Flow 把多步演化压进静态生成器,在 ImageNet 256×256 上刷新一步生成指标。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。

如果说扩散世界模型的瓶颈,是每一步去噪都要把同一个大 Transformer 再跑一遍,那么 WorldCache 的思路就是:不要再把所有 Token、所有时间步都当成同一件事。这篇工作把 “哪些内容适合缓存”和“哪些时刻必须重算” 拆开处理,在不重新训练模型、几乎不增加额外显存的前提下,把缓存真正做成了一套更贴合世界模型结构的推理策略。
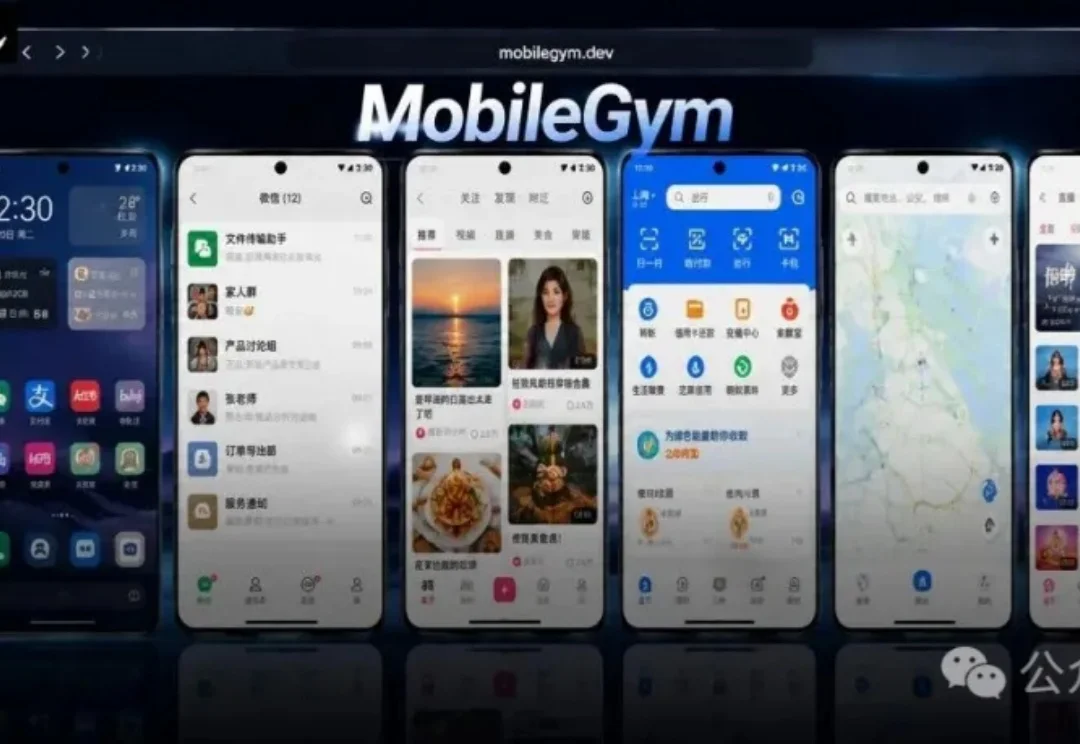
中科院自动化所模式识别实验室开源MobileGym,运行在浏览器里的高并发安卓仿真平台,完全自定义,告别模拟器风控与真机成本,一个平台搞定Mobile Agent训练与评测,甚至还能玩原神!

从 LLM 的超长文本处理、视频生成模型的以假乱真、Agent 自主规划与执行的日趋成熟,到 VLA、世界模型等开始进入物理世界,AI 正在不断拓宽其能力边界。

最近,前沿实验室 Mind Lab 密集发布了一系列关于 LoRA 与 PEFT(高效微调)的研究结果,似乎描绘出了另一条大模型「持续学习」的路径。在 Mind Lab 的视角中,PEFT 不再是对大模型全参数后训练的一种廉价平替,更是实现从 “基础模型” 向 “可持续学习智能体” 过渡的核心架构机制。

把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
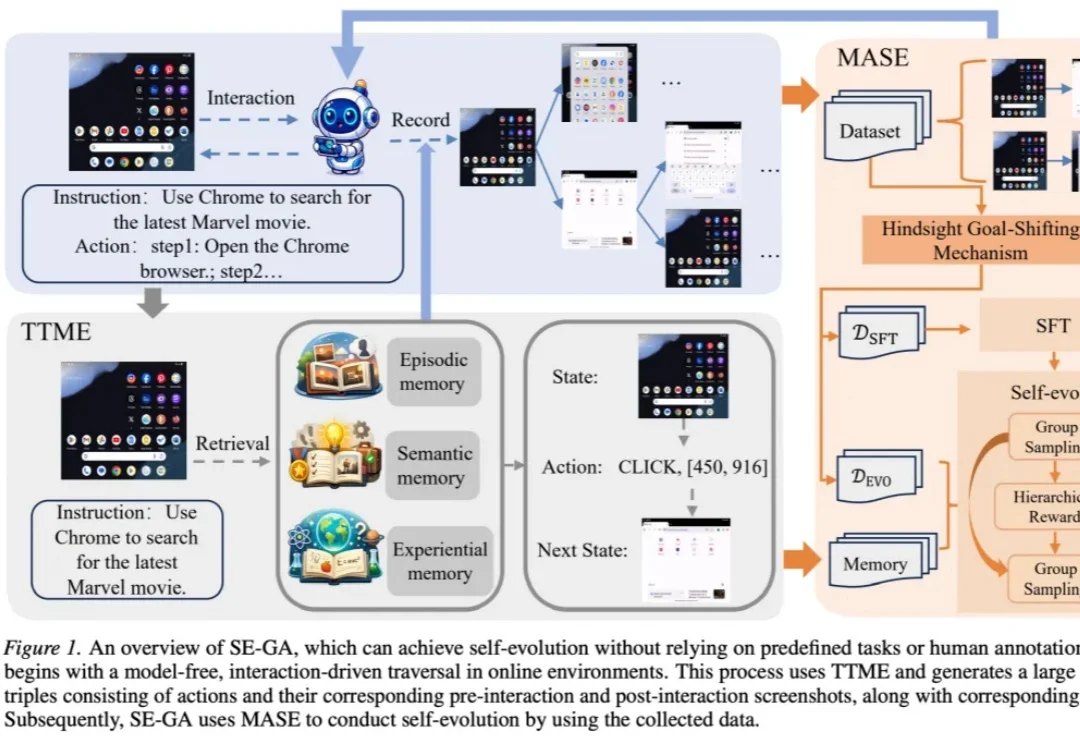
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。

紧跟DeepSeek价格战,小米掏出技术底牌!