都让让!赛博女娲蒸馏一切,让乔布斯马斯克集体给你打工
都让让!赛博女娲蒸馏一切,让乔布斯马斯克集体给你打工继skill同事之后,有聪明人迁移泛化了一下: 既然可以蒸馏任何人,那为什么不让乔布斯马斯克给我打工呢?
来自主题: AI技术研报
8121 点击 2026-04-21 09:22
 搜索
搜索
继skill同事之后,有聪明人迁移泛化了一下: 既然可以蒸馏任何人,那为什么不让乔布斯马斯克给我打工呢?
今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。

研究者用特制雨伞干扰无人机视觉系统,让其误判目标在远去,从而失控俯冲。FlyTrap攻击无需信号干扰,仅靠物理图案就能欺骗多款商用无人机,实现静默捕获或击毁。实验显示,物理闭环攻击成功率超60%,且对新人物、新场景均有强泛化能力。这项研究揭示了AI感知系统的重大安全隐患,警示我们:视觉安全正成为智能设备的阿喀琉斯之踵。
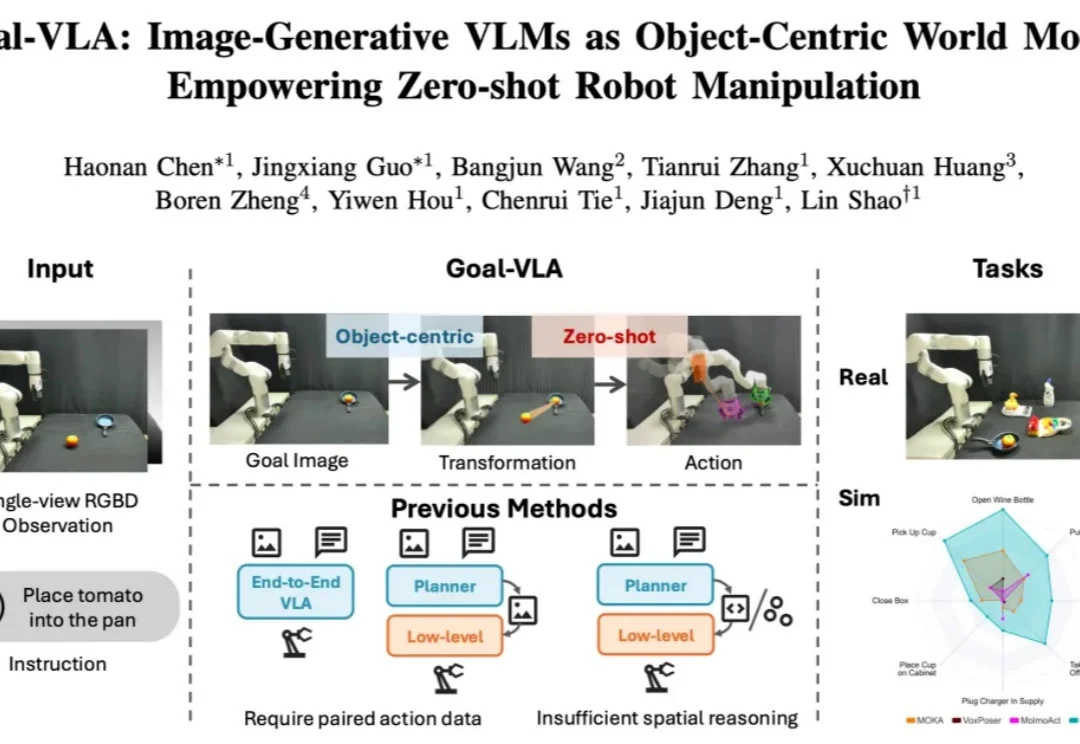
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。
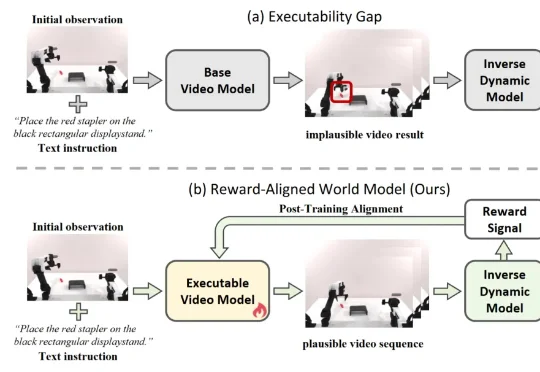
近期,利用视频生成模型为机器人构建 “世界模型”,已成为具身智能领域的热门技术路线。给定当前观测和自然语言指令,这类模型能够先 “想象” 出未来的视觉轨迹,再由逆动力学模型(IDM)将生成画面解码为机器人动作,从而形成 “先预测、后执行” 的解耦式规划范式。由于兼具较强的可解释性与开放场景泛化潜力,这一路线正在受到学术界和工业界的广泛关注。

ICLR'26新研究CPiRi打破时序预测僵局:用冻结底座提取时序特征,轻量模块专注学习通道间真实关系,不靠位置编码「背答案」。测试中通道乱序性能零波动,仅用25%数据即可泛化至全网络,真正实现鲁棒与精准双赢。
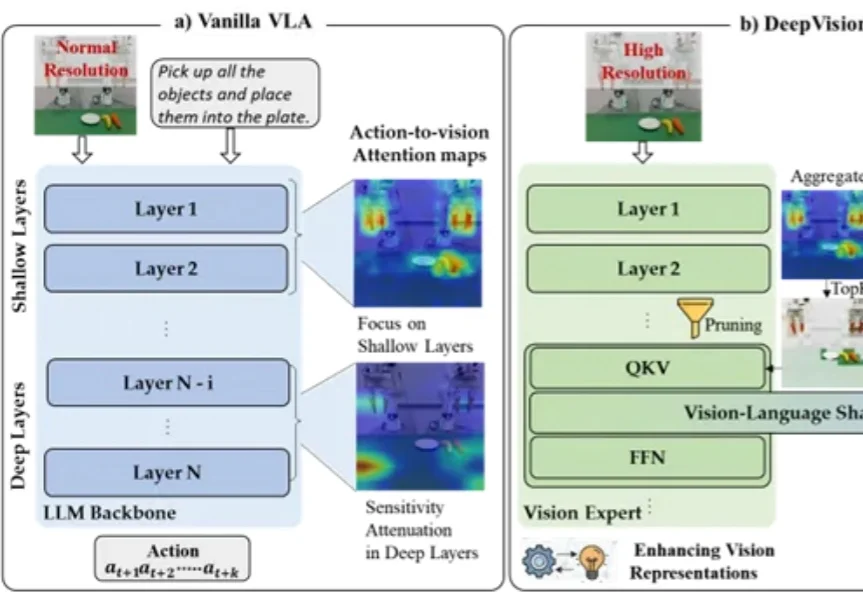
“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。

一张蓝锥嘴雀的图片,你能认出它是“鸟”,但能认出它是“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”吗?
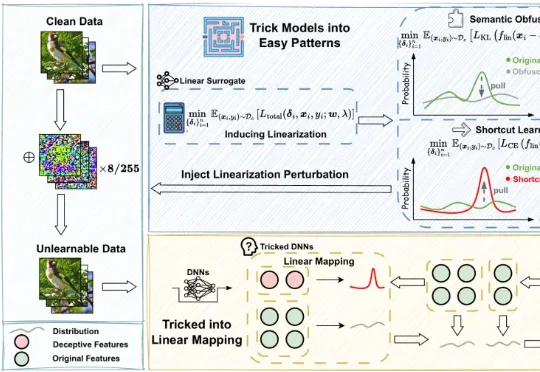
不可学习样本(Unlearnable Examples)是一类用于数据保护的技术,其核心思想是在原始数据中注入人类难以察觉的微小扰动,使得未经授权的第三方在使用这些数据训练模型时,模型的泛化性能显著下降,甚至接近随机猜测,从而达到阻止数据被滥用的目的。