千寻智能高阳团队最新成果:纯视觉VLA方案从有限数据中学到强大的空间泛化能力
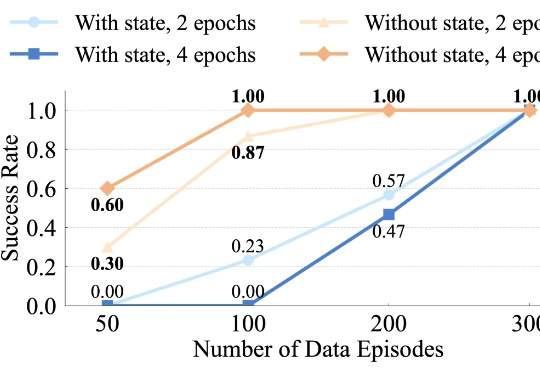
千寻智能高阳团队最新成果:纯视觉VLA方案从有限数据中学到强大的空间泛化能力最近,千寻智能的研究人员注意到,基于模仿学习的视觉运动策略中也存在类似现象,并在论文《Do You Need Proprioceptive States in Visuomotor Policies?》中对此进行了深入探讨。
来自主题: AI技术研报
8793 点击 2025-09-29 14:31
 搜索
搜索
最近,千寻智能的研究人员注意到,基于模仿学习的视觉运动策略中也存在类似现象,并在论文《Do You Need Proprioceptive States in Visuomotor Policies?》中对此进行了深入探讨。
视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。
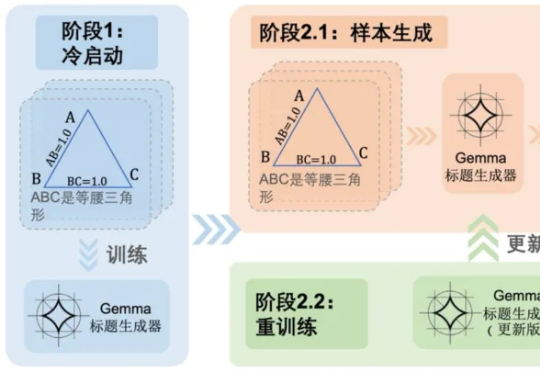
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视
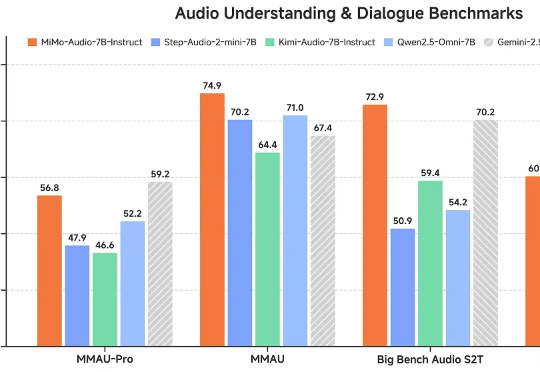
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。

9 月 11 日下午,机器之心联合张江具身智能机器人有限公司共同出品的 2025 Inclusion・外滩大会 「具身智能:从泛化到行动,重塑产业未来」见解论坛在上海隆重举办。在这场围绕具身智能展开的盛会上,多位来自学界和业界的代表分享了他们在具身智能行业发展的经验和看法。
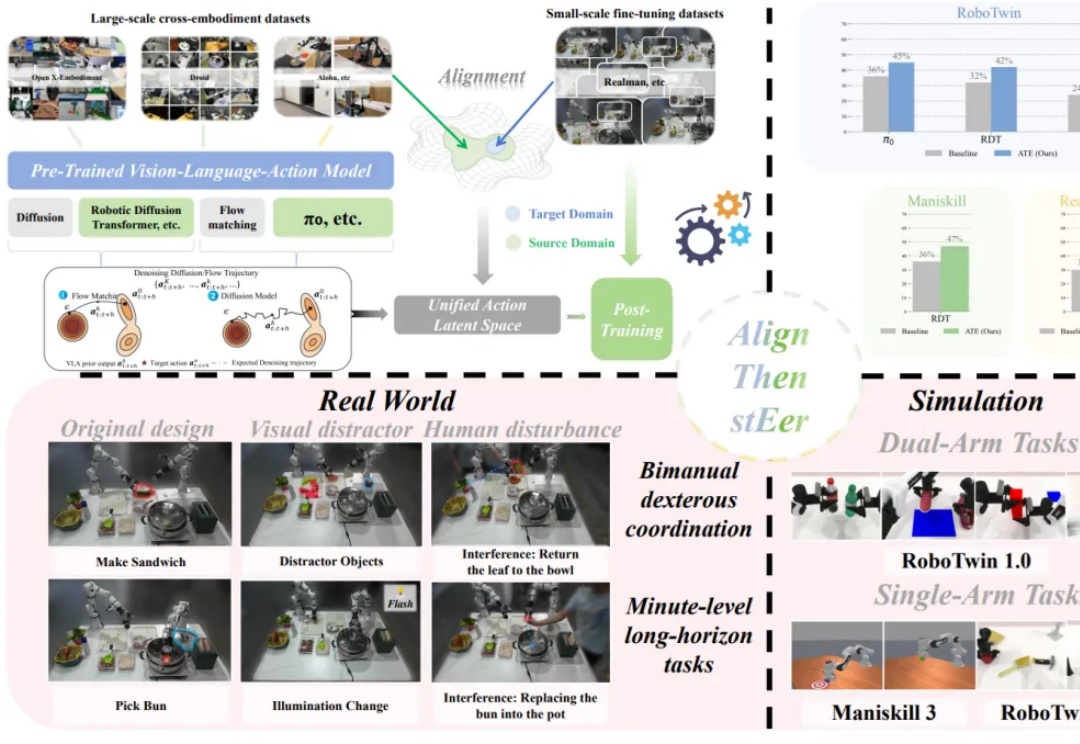
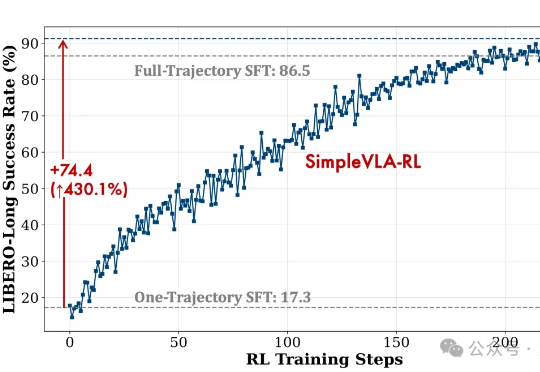
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。
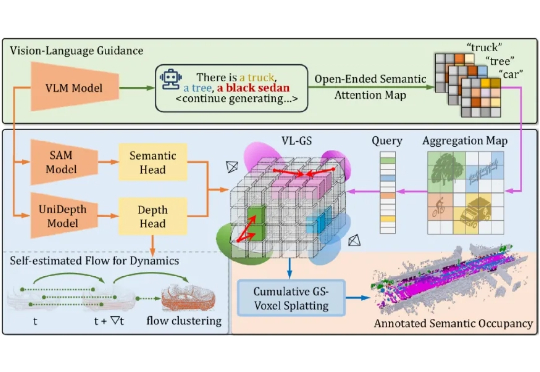
本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。
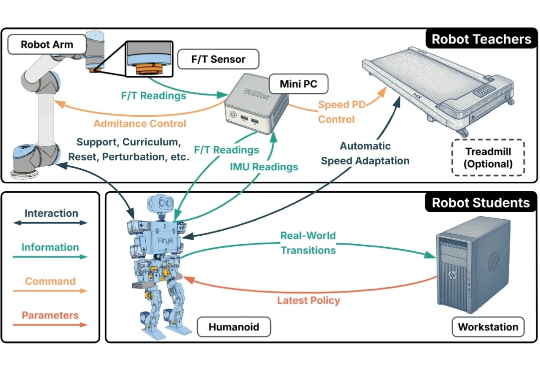
人形机器人的运动控制,正成为强化学习(RL)算法应用的下一个热点研究领域。当前,主流方案大多遵循 “仿真到现实”(Sim-to-Real)的范式。研究者们通过域随机化(Domain Randomization)技术,在成千上万个具有不同物理参数的仿真环境中训练通用控制模型,期望它能凭借强大的泛化能力,直接适应动力学特性未知的真实世界。
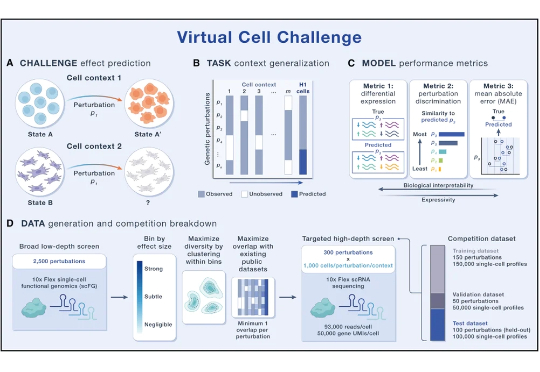
AI虚拟细胞(AIVC)旨在借助海量生物数据与AI模型,精确模拟细胞在各种基因或药物扰动下的响应状态。最近两年,AIVC正快速渗透到生命科学与医药研发领域,但仍面临数据类型繁杂、模型难以泛化、缺乏统一标准等制约。2025年6月,Arc Institute发起首届“虚拟细胞挑战赛”,通过构建统一的数据基座与测评标准体系,引导细胞建模走向规范。

Atlas进厂打工技能再进化!波士顿动力联手丰田研究院,首次让人形机器人Atlas能够通过语言指令驱动,一次性处理从折叠配件到整理仓架的复杂作业。这种LBM(Large Behavior Models,大行为模型)方法让机器人具备跨任务泛化能力,迈出了工业化实践的一大步。