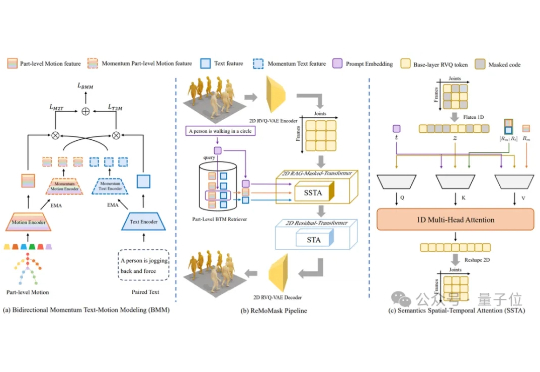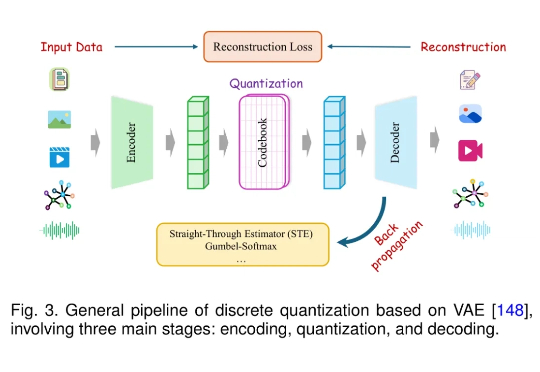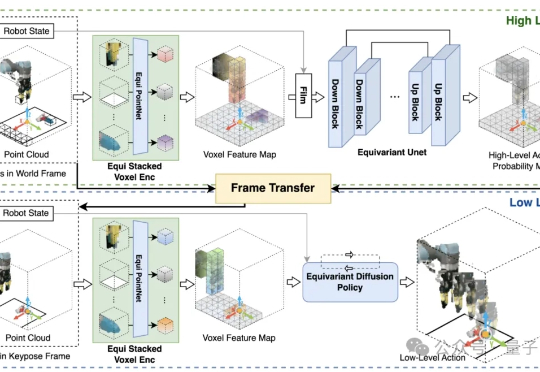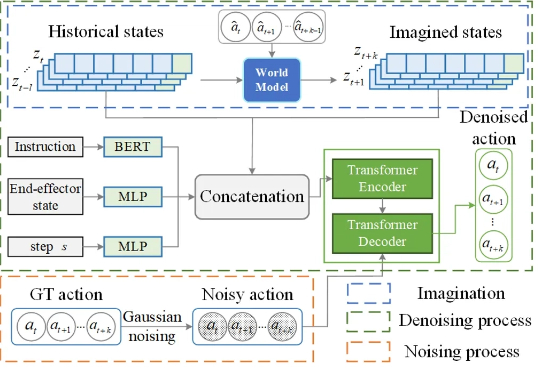
CoRL 2025|隐空间扩散世界模型LaDi-WM大幅提升机器人操作策略的成功率和跨场景泛化能力
CoRL 2025|隐空间扩散世界模型LaDi-WM大幅提升机器人操作策略的成功率和跨场景泛化能力在机器人操作任务中,预测性策略近年来在具身人工智能领域引起了广泛关注,因为它能够利用预测状态来提升机器人的操作性能。然而,让世界模型预测机器人与物体交互的精确未来状态仍然是一个公认的挑战,尤其是生成高质量的像素级表示。
来自主题: AI技术研报
8520 点击 2025-08-18 11:53