
Z Tech|专访张金涛:清华朱军教授的00后博士、Vidu S1负责人,让视频生成走向实时交互
Z Tech|专访张金涛:清华朱军教授的00后博士、Vidu S1负责人,让视频生成走向实时交互2026年,视频生成赛道正在经历一场从“离线生成”到“实时交互”的范式转移。7月3日全球数字经济大会上——生数科技创始人朱军正式发布Vidu S1实时交互模型,让AI从“视频生成”正式迈入“实时交互”的新阶段。
来自主题: AI资讯
7941 点击 2026-07-14 10:36
 搜索
搜索
2026年,视频生成赛道正在经历一场从“离线生成”到“实时交互”的范式转移。7月3日全球数字经济大会上——生数科技创始人朱军正式发布Vidu S1实时交互模型,让AI从“视频生成”正式迈入“实时交互”的新阶段。
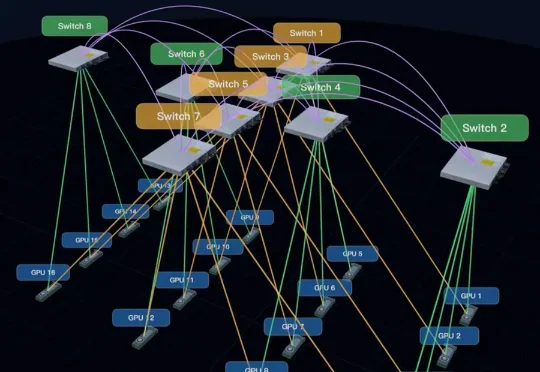
一家推翻传统网络架构的清华系创业公司,联合智谱、清华大学推出了全新的网络架构ZCube,能提升推理算力集群15%的Token产量,还能砍下约33%的网络硬件成本。近日,驭驯网络已完成智谱独家领投的数千万元融资,源合资本担任长期财务顾问。
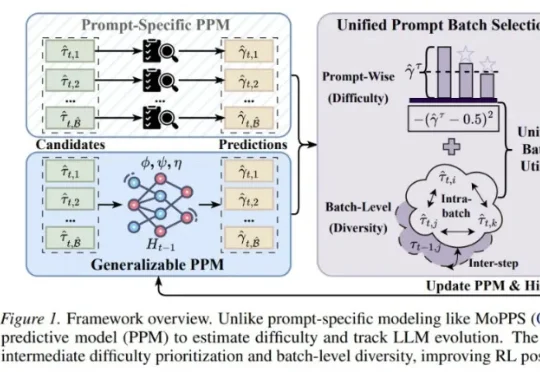
来自清华大学与腾讯的研究者提出了 Generalizable Predictive Prompt Selection(GPS)。GPS 的做法很直接:先训练一个小型、可泛化的 Prompt Predictive Model(PPM),让它预测不同 prompt 在当前模型下的难度;再根据难度和 batch 多样性选择训练样本,从而减少无效 rollout。
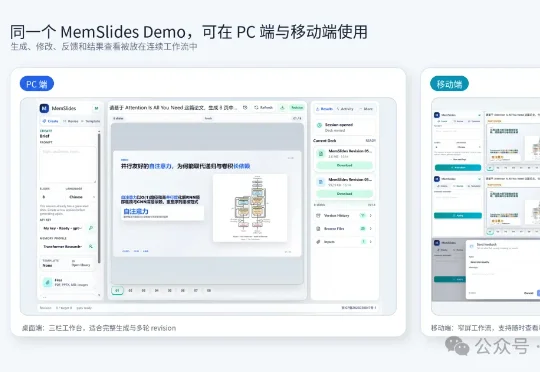
来自清华、上交、北邮的学者们提出了一个面向个性化幻灯片生成和多轮局部修改的记忆驱动Slides Agent框架——MemSlides。它专门针对AI PPT痛点而生,不仅能够为你量身定制私人专属的PPT生成风格,还能够贴心地记住你在制作过程中随口提出的新要求

研究团队提出了符号嵌入量子算法(Sign Embedding Quantum Algorithms),形成了一篇84页的量子算法论文。可以说,相比此前主要解决研究者给定的开放数学问题,这一次,AIM开始参与研究问题的提出与方向探索。
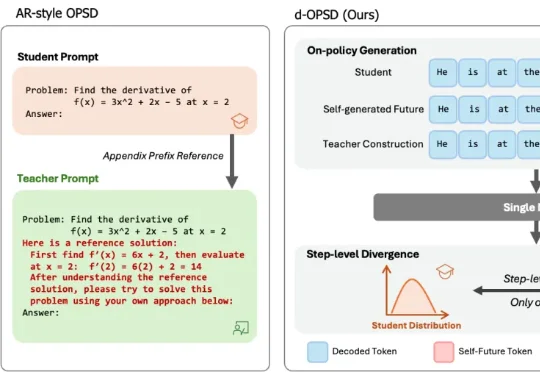
有没有一种更为合适的 OPSD 范式?近期,清华大学和马普所等机构的研究者们联合推出的 d-OPSD,给这一问题提供了完美的答案。这是第一个针对扩散大语言模型的 OPSD 范式,无需参考解,无需额外的教师模型,只需要 RL 十分之一的训练步数,便可以达到或超出 RL 的后训练效果。
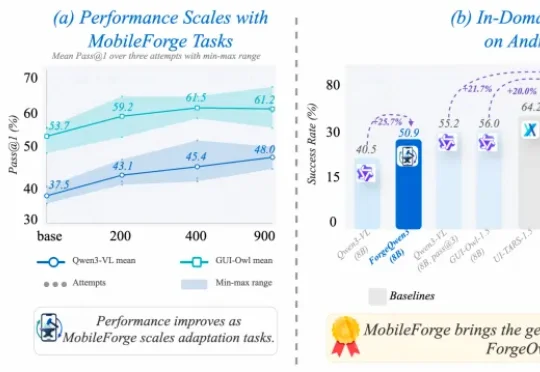
来自浙江大学 APRIL 实验室、快手主站技术部和清华大学的研究团队提出了 MobileForge,试图把手机 GUI Agent 的适配过程变成一个 “无标注、自探索、自反馈、自优化” 的闭环系统。
7月9日,投中网获悉,物理AI公司深度智控(DeepCtrls)(以下简称“深度智控”)已完成战略轮与B轮融资,合计融资金额数亿元,本轮资金将用于核心产品研发、商业化拓展及国际化布局。深度智控成立于2018年,定位为物理AI能源基础设施服务商。

2026年4月,一位在美国AI圈极具影响力的研究者,专程来到中国,走进北京、杭州和上海的AI实验室。他密集拜访了阿里巴巴、月之暗面、智谱、清华、美团、小米、蚂蚁和零一万物等团队。回到美国后,他写了一篇名为《Notes from inside China's AI labs》(中国AI实验室内部观察随笔)的文章,在美国科技圈引发了不小讨论。
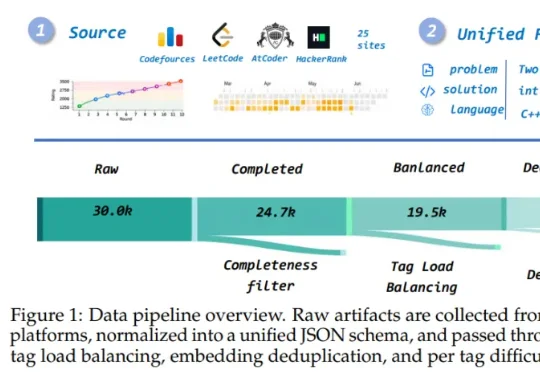
大语言模型在代码生成上的能力不断增强,但在复杂算法题,尤其是竞赛编程场景中,仍然容易因为算法选择错误、边界条件遗漏、复杂度判断失误或隐藏测试覆盖不足而失败。Solvita是一款面向竞赛编程的智能体框架,通过四个角色(Planner、Solver、Oracle、Hacker)形成闭环系统,并利用可训练的图结构知识网络积累经验。