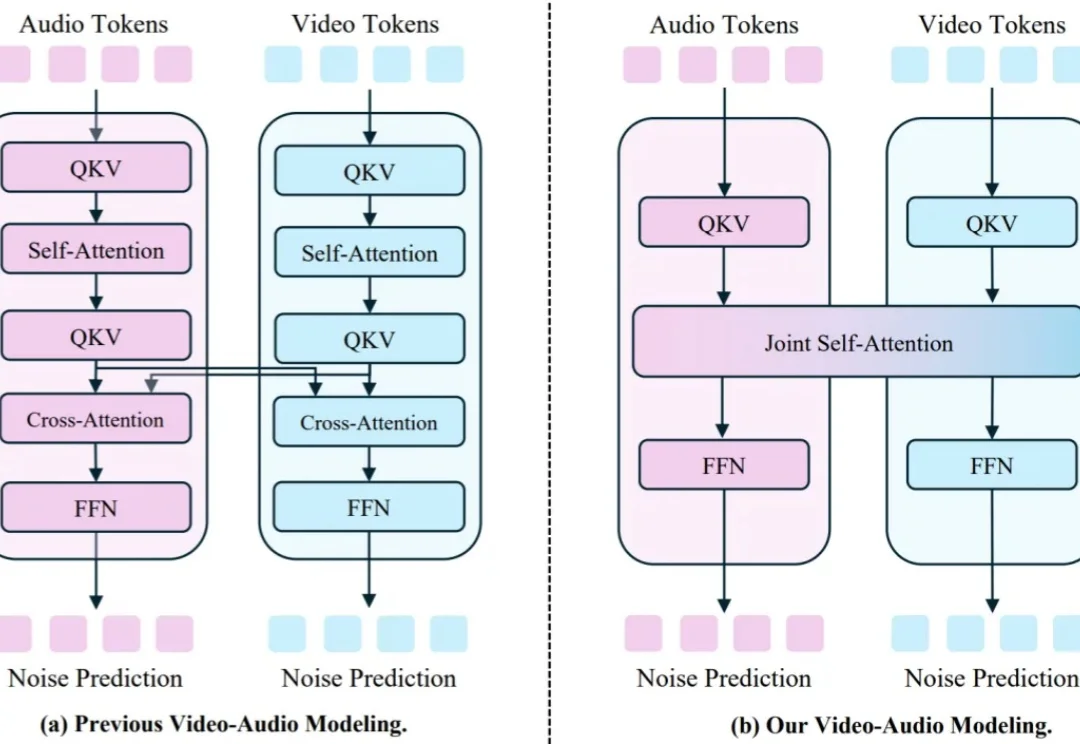
港大联合字节跳动提出JoVA: 一种基于联合自注意力的视频-音频联合生成模型 港大联合字节跳动提出JoVA: 一种基于联合自注意力的视频-音频联合生成模型 关键词: AI新闻,模型训练,JoVA,的视频-音频联合生成模型 视频 - 音频联合生成的研究近期在开源与闭源社区都备受关注,其中,如何生成音视频对齐的内容是研究的重点。 来自主题: AI技术研报 8827 点击 2025-12-30 10:27
 搜索
搜索