

吴永辉接管字节 Seed 这一年
吴永辉接管字节 Seed 这一年创新需要适当的灰度和混乱,但应对竞争需要秩序和纪律。 上千人的研究团队、投入上百亿元追赶两年,终于研发出能排在中国第一梯队的基础模型,迅速被只有上百人的团队用更少资源研发的模型超过,部门负责人承认失误,公司 CEO 在全员会上点名,本可以做得更好。
来自主题: AI资讯
6815 点击 2026-02-10 14:27
创新需要适当的灰度和混乱,但应对竞争需要秩序和纪律。 上千人的研究团队、投入上百亿元追赶两年,终于研发出能排在中国第一梯队的基础模型,迅速被只有上百人的团队用更少资源研发的模型超过,部门负责人承认失误,公司 CEO 在全员会上点名,本可以做得更好。
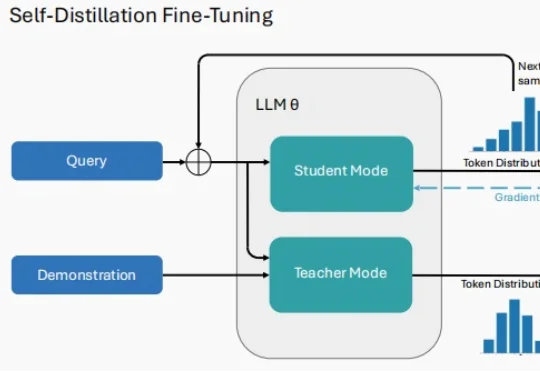
2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。

Contrary 是一家成立于 2018 年的美国风险投资公司,由 Eric Tarczynski 创办,自成立以来,其以“人才驱动+研究驱动”为核心方法论,在全球顶级高校铺设了庞大的人才网络,通过识别最优秀的年轻技术人才来发现投资机会。
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?

2025 年 1 月 20 日,DeepSeek 发布了推理大模型 DeepSeek-R1,在学术界和工业界引发了对大模型强化学习方法的广泛关注与研究热潮。 研究者发现,在数学推理等具有明确答案的任务
我深入研究Salient的故事后发现,这个行业的落后程度超乎想象。美国近80%的家庭都有某种形式的债务,每年大约有8000亿美元的新汽车贷款发放。为了服务这些贷款,贷款机构每年要花费200亿到300亿美元——主要是雇佣大量人工打电话、发信件、协商还款计划。这是一个巨大的成本中心,但几十年来基本没有发生任何技术革新。
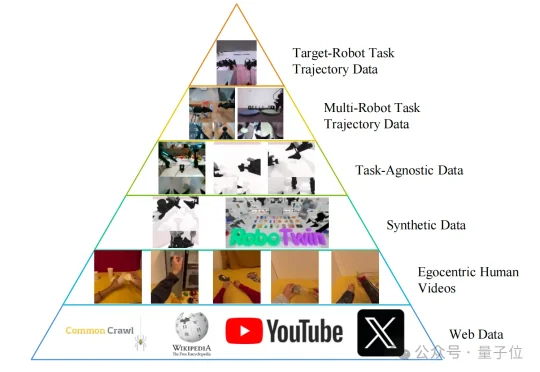
国产开源具身世界模型,直接秒了Pi-0.5,而且还是几位清华硕、博士研究生领衔推出的。这就是由生数科技联合清华大学,正式开源的大一统世界模型——Motus。

过去一年,LLM Agent几乎成为所有 AI 研究团队与工业界的共同方向。OpenAI在持续推进更强的推理与工具使用能力,Google DeepMind将推理显式建模为搜索问题,Anthropic则通过规范与自我批判提升模型可靠性。
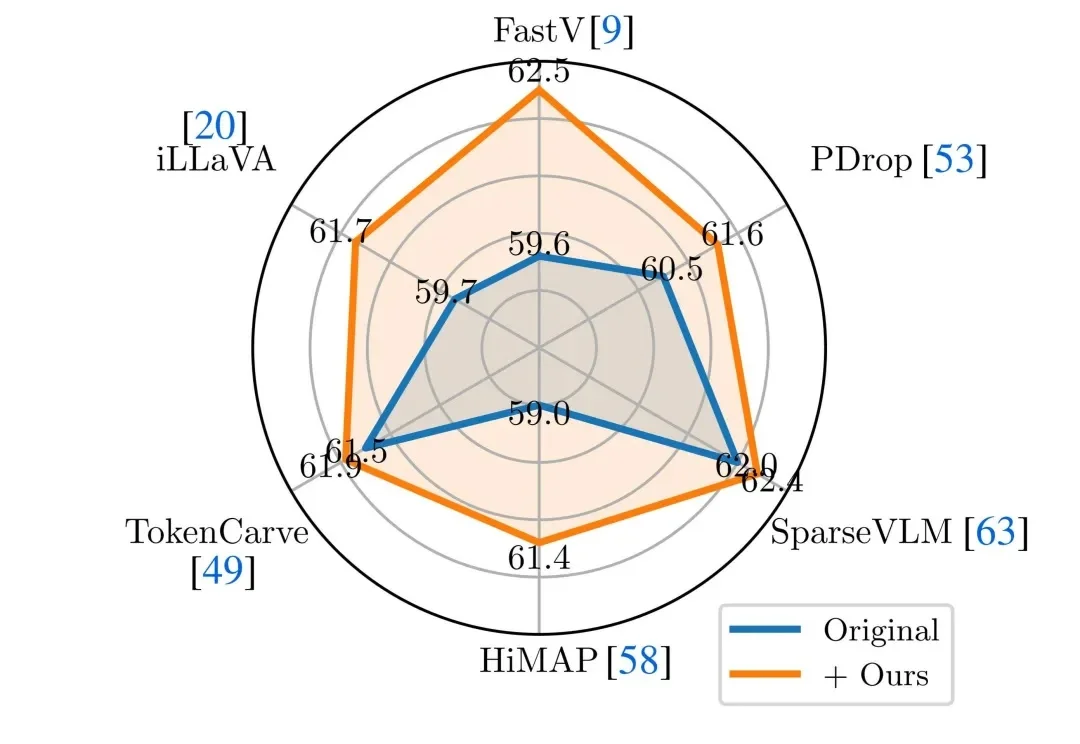
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。

灵尾纪元科技 (深圳) 有限公司(以下简称「灵尾纪元」)不仅仅想要做宠物猫砂盆、饮水机、喂食器等常规智能设备,从业务初创期开始,他们就在研究一个更为宏大的命题——「宠物 AI 孪生体」概念。