

大模型学会拖进度条看视频了!阿里新研究让视频推理告别脑补,实现证据链思考 | ICLR 2026
大模型学会拖进度条看视频了!阿里新研究让视频推理告别脑补,实现证据链思考 | ICLR 2026为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?
来自主题: AI技术研报
9140 点击 2026-01-30 09:56
为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?

Figure 发布 Helix 02,机器人领域又要变天了
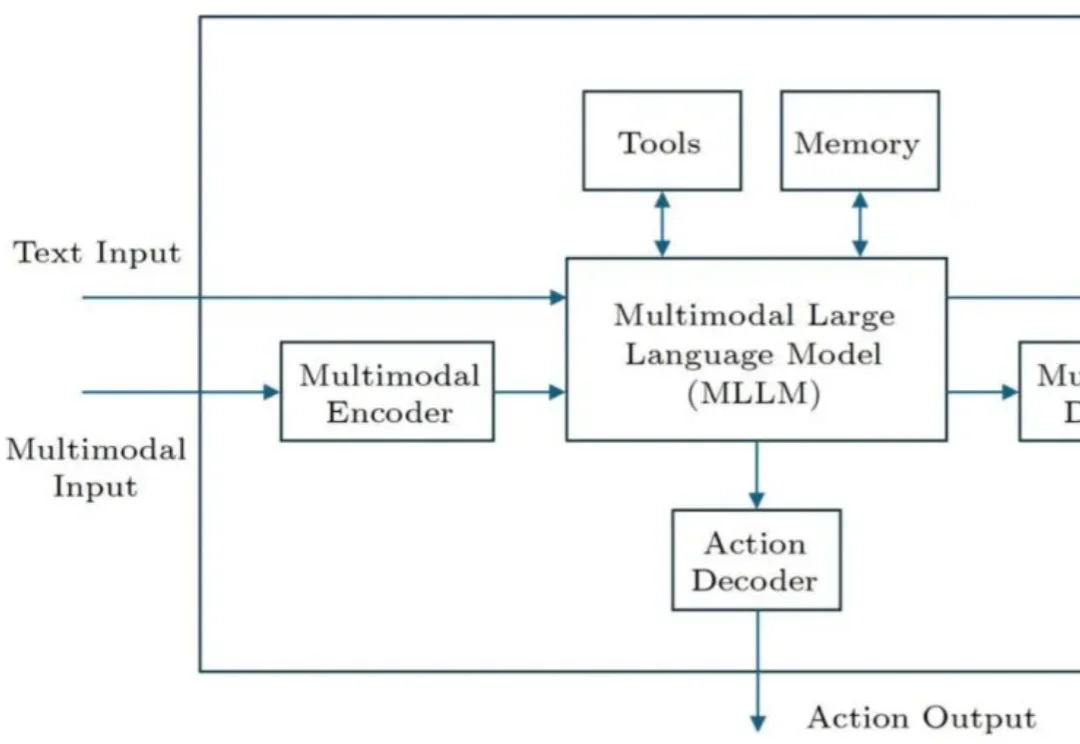
AI 智能体是人工智能领域的重要研究方向之一。近期,字节跳动的李航博士在我国计算机科学领域顶级期刊 Journal of Computer Science and Technology(JCST)上发表了一篇题为《General Framework of AI Agents》的观点论文(将收录于 JCST 创刊 40 周年专辑),提出了一个涵盖软件智能体和硬件智能体的通用框架。

今天凌晨,月之暗面核心团队在社交媒体平台Reddit上举行了一场有问必答(AMA)活动。三位联合创始人杨植麟(CEO)、周昕宇(算法团队负责人)和吴育昕与全球网友从0点聊到3点,把许多关键问题都给聊透了,比如Kimi K2.5是否蒸馏自Claude、Kimi K3将带来的提升与改变,以及如何在快速迭代与长期基础研究之间取得平衡。

过去几年,机制可解释性(Mechanistic Interpretability)让研究者得以在 Transformer 这一 “黑盒” 里追踪信息如何流动、表征如何形成:从单个神经元到注意力头,再到跨层电路。但在很多场景里,研究者真正关心的不只是 “模型为什么这么答”,还包括 “能不能更稳、更准、更省,更安全”。
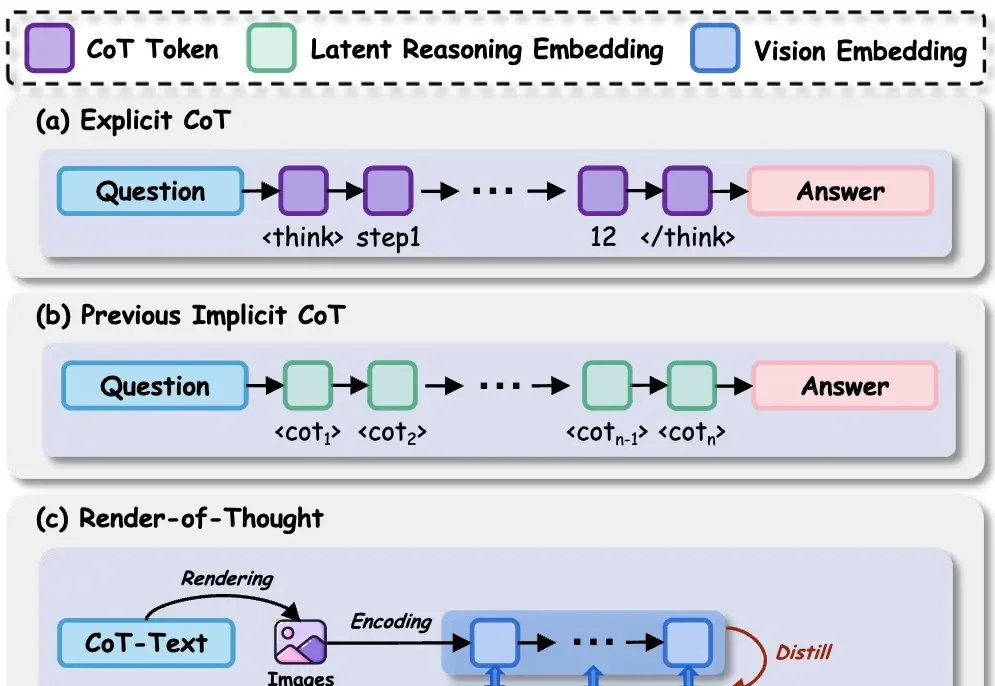
在 LLM 时代,思维链( CoT)已成为解锁模型复杂推理能力的关键钥匙。然而,CoT 的冗长问题一直困扰着研究者——中间推理步骤和解码操作带来了巨大的计算开销和显存占用,严重制约了模型的推理效率。

硅谷大厂HR标配的AI招聘系统,搞得天怒人怨。

这是一份迟到三年的行业复盘。牛津大学最新的实证研究撕开了那层遮羞布:2022年全球科技大裁员爆发时,ChatGPT甚至尚未发布。周期性缩编被伪装成技术性迭代,AI替资本背了三年的锅,直到今天真相才被彻底复位。
思维导图曾被证明可以帮助学习障碍者快速提升成绩,那么当前已经可堪一用的智能体系统如果引入类似工具是否可以帮助改善长期学习记忆能力呢?有研究团队做出了探索性尝试。

近日,北京大学朱毅鑫教授课题组、北京大学毕彦超教授课题组和山西医科大学第一医院王效春团队通过结合 AI 模型和大脑损伤患者的数据,发现语言其实是一副无形的智能眼镜,时刻在悄悄修饰着我们看到的世界。我们可能以为视觉就是眼睛看到什么就是什么,但是这项成果说明了视觉从来都不是孤立的。事实上,当我们在看图片的时候,其实不只是在看,而是在进行被语言调制过的看。