
深度解读“下一代核能”:当AI开始抢电,全世界重新押注核电丨2026年十大突破性技术
深度解读“下一代核能”:当AI开始抢电,全世界重新押注核电丨2026年十大突破性技术随着 AI 技术的蓬勃发展, AI 模型的参数规模和推理频次呈指数级增长。据高盛研究部预测,到 2030 年,全球数据中心的电力需求将增长 160%。
来自主题: AI资讯
6158 点击 2026-01-19 15:14
随着 AI 技术的蓬勃发展, AI 模型的参数规模和推理频次呈指数级增长。据高盛研究部预测,到 2030 年,全球数据中心的电力需求将增长 160%。
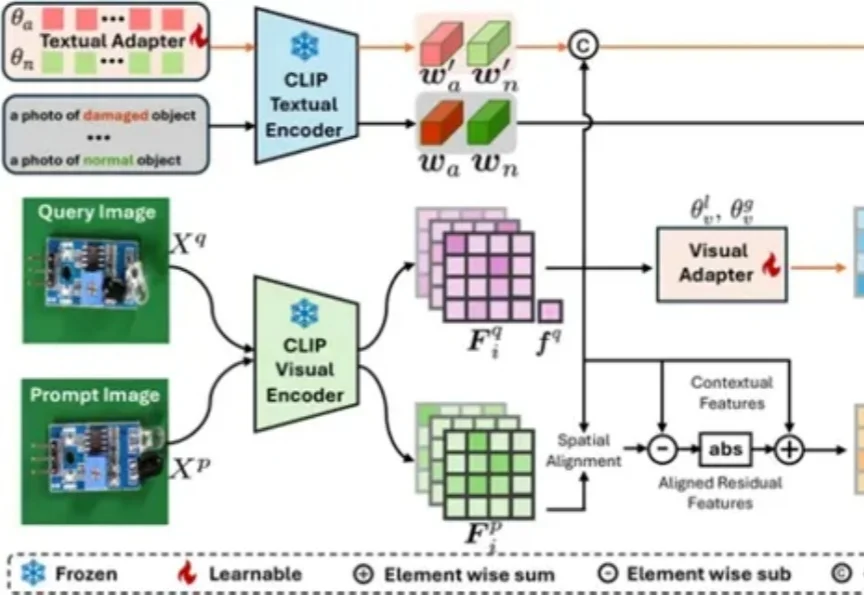
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。

清华在Nature上发表的最新研究发现,AI使科学家更聚焦于数据丰富、问题明确的领域,导致创新单一化,跨界合作减少。研究团队提出「全流程科研智能体系统」,推动AI从工具进化为伙伴,拓展科学边界。

在家庭厨房自主使用洗碗机,在办公室边移动边擦拭白板——这些人类习以为常的场景,对人形机器人来说,却是需要调动全身关节协同运作才能完成的“高难度挑战”。
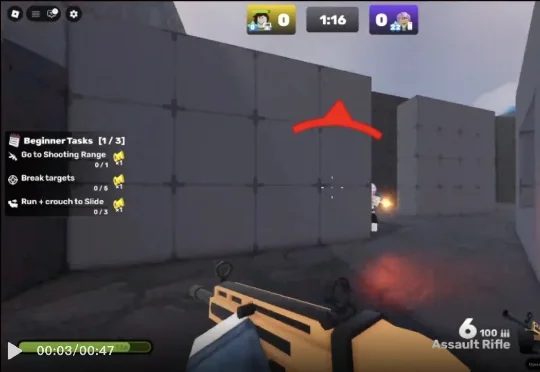
来自 Player2 的研究员们提出了 Pixel2Play(P2P)模型,该模型以游戏画面和文本指令作为输入,直接输出对应的键盘与鼠标操作信号。在消费级显卡 RTX 5090 上,P2P 可以实现超过 20Hz 的端到端推理速度,从而能够真正像人类一样和游戏进行实时交互。P2P 作为通用游戏基座模型,在超过 40 款游戏、总计 8300 + 小时的游戏数据上进行了训练,

简单到难以置信!近日,Google Research一项新研究发现:想让大模型在不启用推理设置时更准确,只需要把问题复制粘贴再说一遍,就能把准确率从21.33%提升到97.33%!

随着AI大模型研发在架构、记忆、存储等等领域的深水区创新,OCR重新成为了技术专项。DeepSeek在研究、智谱在研究、阿里千问和腾讯混元也都在研究……还得是吴恩达老师,火速来了新课程,帮你速通OCR。
近日,德国物理学家、百万粉丝科普博主Sabine Hossenfelder在一则视频中,抛出了一个让学术界「脊背发凉」的观点:三年内,我们所熟悉的科学研究将不复存在。但AI能力的进化速度,远远超出人类预期。
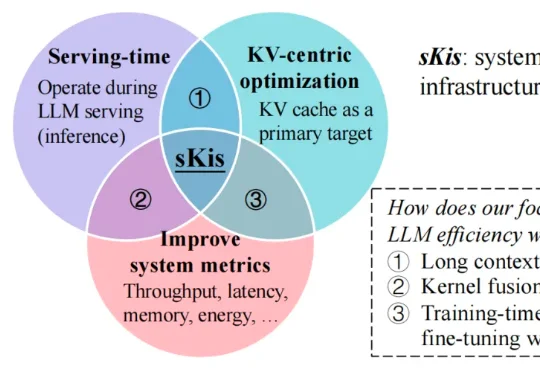
近期,来自墨尔本大学和华中科技大学的研究者们发布了一篇深度综述,从 MLSys 的思维出发,用一套新颖的「时间 - 空间 - 结构」系统行为视角对 KV cache 优化方法进行了系统性梳理与深入分析,并将相关资源整理成了持续维护的 Awesome 资源库,方便研究者与从业人员快速定位与落地。
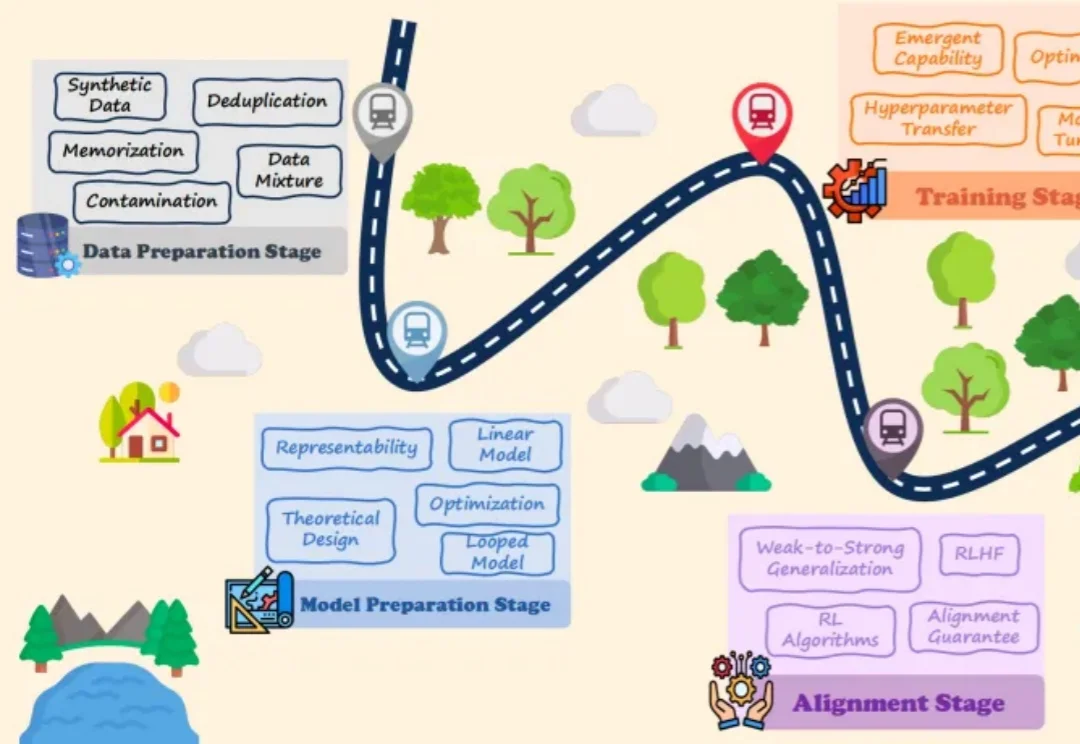
大语言模型(LLMs)的爆发式增长引领了人工智能领域的范式转移,取得了巨大的工程成功。然而,一个关键的悖论依然存在:尽管 LLMs 在实践中表现卓越,但其理论研究仍处于起步阶段,导致这些系统在很大程度上被视为难以捉摸的「黑盒」。