
AI for Science开年新突破:中科大实现多尺度结构逆向设计128倍加速,登上Nature子刊
AI for Science开年新突破:中科大实现多尺度结构逆向设计128倍加速,登上Nature子刊近日,中国科学技术大学(USTC)联合新疆师范大学、中关村人工智能研究院、香港理工大学,在数据驱动的多功能双连通多尺度结构逆向设计领域取得重要突破。
来自主题: AI技术研报
7538 点击 2026-01-22 10:12
近日,中国科学技术大学(USTC)联合新疆师范大学、中关村人工智能研究院、香港理工大学,在数据驱动的多功能双连通多尺度结构逆向设计领域取得重要突破。

由三位前 OpenAI 研究人员创立的初创公司 Applied Compute 正就以 13 亿美元估值筹集新资金进行谈判,包括该项投资在内。据透露,该公司致力于帮助企业使用自有数据定制模型。若融资成功,其估值将较不到三个月前公布的上一轮融资( 估值约 5 亿美元 )增长逾一倍。

中国团队首次在全球顶尖期刊发表“大模型+医疗”领域的相关标准研究! 作为Nature体系中专注于数字医疗的旗舰期刊,《npj Digital Medicine》(JCR影响因子15.1,中科院医学大类1区Top期刊)此次收录的CSEDB研究,首次提出了一套用于评估医疗大模型真实临床能力的系统性框架。

这两天都在研究 ralph,一个你睡觉时,都能不眠不休替你干需求、榨干任何 Coding Agent 的工具。

当 DeepSeek 和 OpenAI 的核心突破者越来越年轻,传统的简历筛选正在失效。一位前阿里达摩院的研究员,试图用 Agent 编织一张能捕捉「下一个 Ilya」的网。

不要被AI的温柔表象欺骗! Anthropic最新研究刺穿了AGI的温情假象:你以为在和良师益友倾诉,其实是在悬崖边给「杀手」松绑。 当脆弱情感遇上激活值坍塌,RLHF防御层将瞬间溃缩。既然无法教化野兽,人类只能选择最冷酷的「赛博脑叶切除术」。

字节跳动的「扣子」在过去两年的「走一步看一步」和不断的「目标横跳」,其实是一个值得 AI 时代产品人研究的宝藏故事。
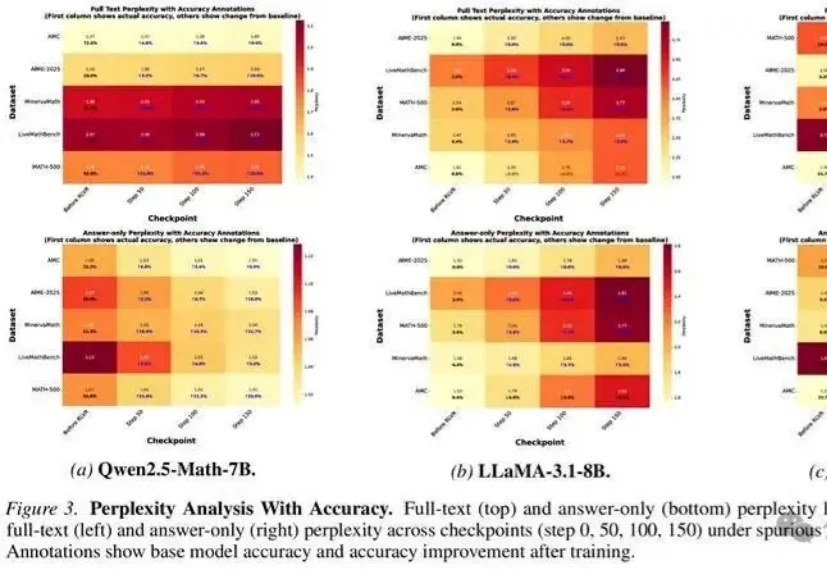
无需真实奖励,哪怕用随机、错误的信号进行训练,大模型准确率也能大幅提升?
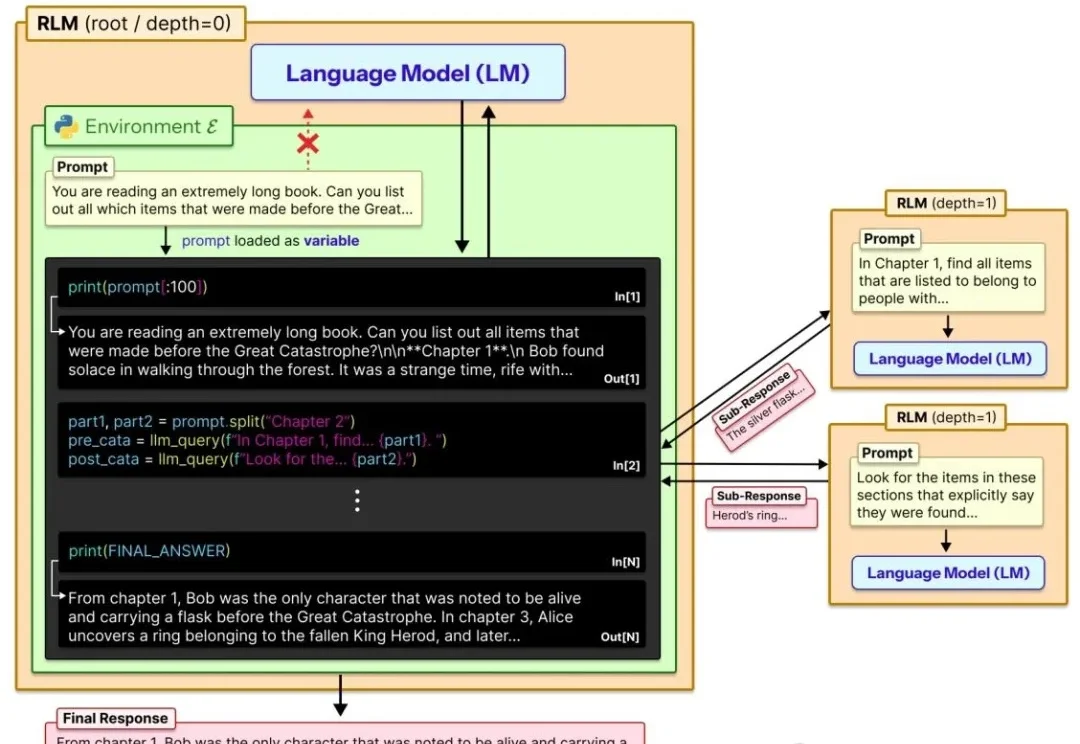
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!
随着 AI 技术的蓬勃发展, AI 模型的参数规模和推理频次呈指数级增长。据高盛研究部预测,到 2030 年,全球数据中心的电力需求将增长 160%。