
顶刊生物实验难复现?统一操作话术来了!编译通过率98.6%
顶刊生物实验难复现?统一操作话术来了!编译通过率98.6%现在的AI,确实越来越像一个「全能研究员」。
来自主题: AI资讯
10005 点击 2026-06-24 09:53
 搜索
搜索
现在的AI,确实越来越像一个「全能研究员」。
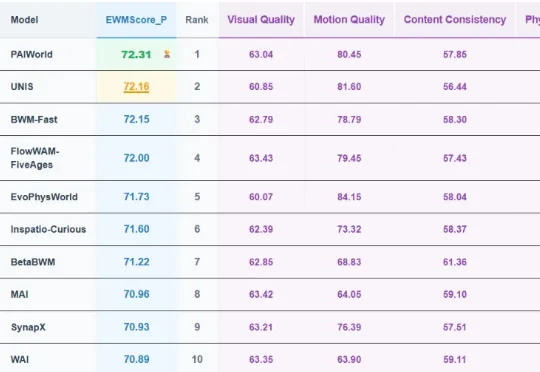
日前,世界模型国际权威榜单 WorldArena 更新排名,中国科学院工业人工智能研究所徐凯研究员带领物理智能团队(The PAI Lab)自研的世界模型 PAIWorld 登顶。WorldArena 作为目前世界模型领域最权威的评测榜单,是针对具身世界模型的全方位评价体系,涵盖视觉质量、运动质量、内容一致性、物理遵循、三维准确性及可控性六大维度

斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。

如今,CameraSquad 的出现,让这种多视角一致的视频生成与 3D 世界状态构建成为现实。近日,中国科学院大学高林研究员团队联合卡迪夫大学、香港科技大学和快手可灵团队,提出了一种面向多轨迹并行生成的相机可控视频生成方法 CameraSquad [1],相关论文已被 ACM SIGGRAPH 2026 录用。
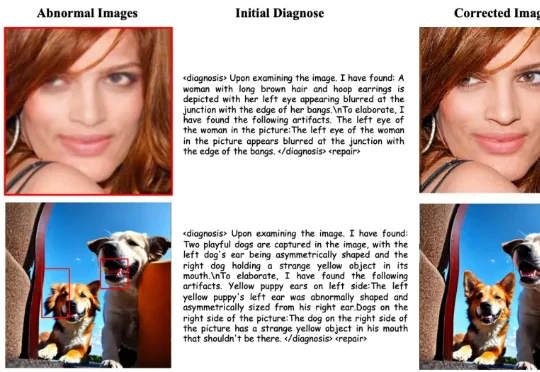
对于 AI 生成图像中可能存在的不自然伪影,我们是否不仅能够将其定位和解释,还能进一步对其进行修复,使图像恢复为更加真实、自然的视觉外观?围绕这一问题,来自北京大学等机构的研究者提出了 GenShield:一个统一的自回归框架,将 AI 生成图像检测 与 图像伪影修复 结合到同一个闭环中,实现从 “诊断” 到 “修复” 的一体化建模。
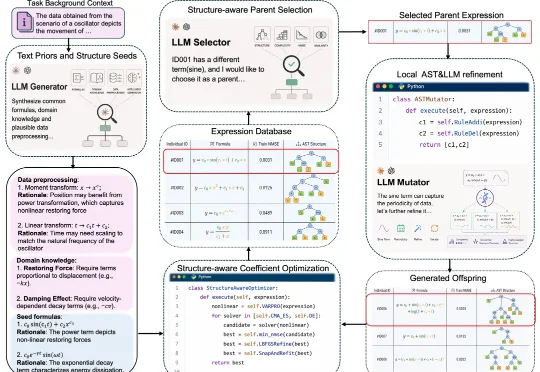
来自博世中央研究院与清华大学的研究人员提出 FunctionEvolve 框架,在两大基准测试上大幅刷新了这项任务的结果。在 LLM-SRBench 的 129 个合成科学方程任务上,FunctionEvolve 最终给出的公式在 55.8% 的任务上与真实公式等价(SA@1 = 72/129),是此前最好结果的 3.6 倍;
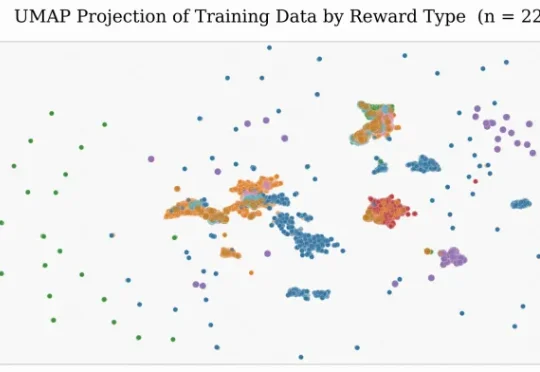
本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集
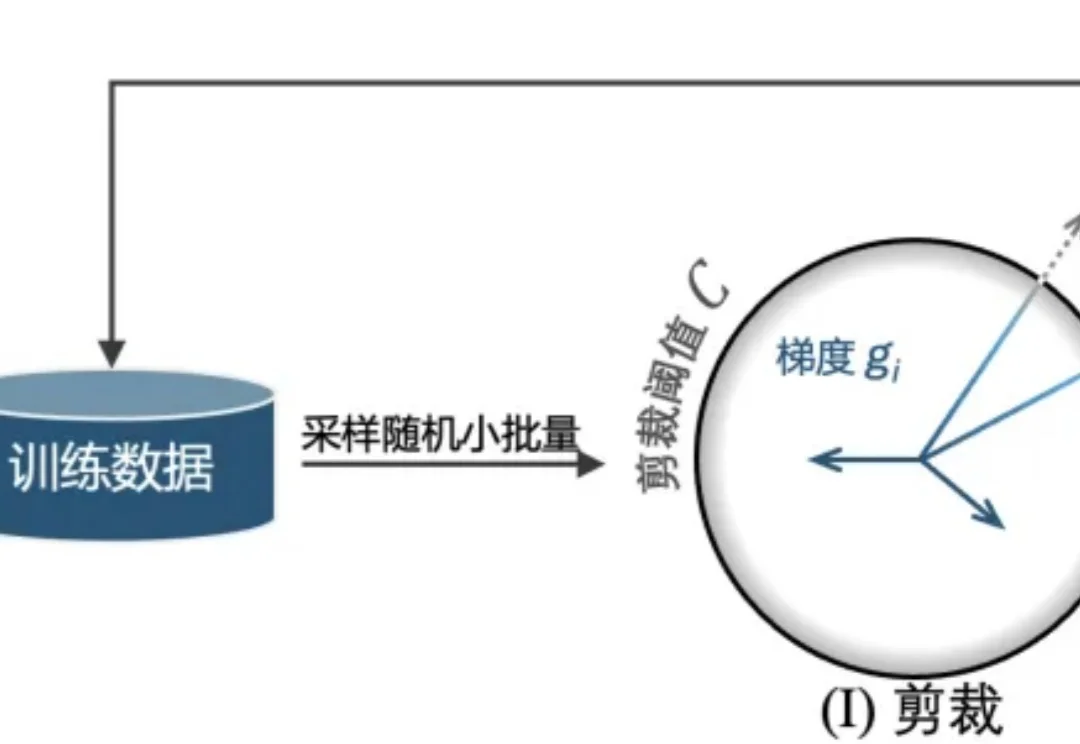
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。

自动化研究,这一次真正走出代码沙盒,进入了真实的物理世界。

AutoResearch这个词关注AI的同学应该不陌生,大神Andrej Karpathy提出的Agent 自主科研项目,现在已经是GitHub的明星项目了,应用不计其数。