
实锤:Claude Opus 4.8「偷答案」!63%靠抄,AI断网后成绩雪崩
实锤:Claude Opus 4.8「偷答案」!63%靠抄,AI断网后成绩雪崩Cursor AI官方发布重磅研究,实锤包括自家模型在内的顶级AI,在编程评测中大规模「偷看答案」:Opus 4.8高达87.1%的惊人成绩,断网后直接暴跌至73.0%,其中63%的「解题」竟非独立推导。
来自主题: AI资讯
8563 点击 2026-06-26 20:29
 搜索
搜索
Cursor AI官方发布重磅研究,实锤包括自家模型在内的顶级AI,在编程评测中大规模「偷看答案」:Opus 4.8高达87.1%的惊人成绩,断网后直接暴跌至73.0%,其中63%的「解题」竟非独立推导。
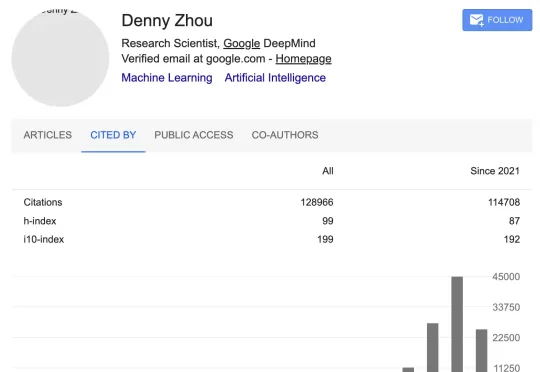
刚刚才发现,那堪称DeepMind「推理之王」的男人——周登勇(Denny Zhou),早已离开了谷歌。现在的东家是Meta,在MSL担任研究科学家。整个过程极其低调。没有长篇大论的告别信,没有Meta的高调官宣,如果不是LinkedIn上的职位信息悄悄更新,外界甚至不知道这位大牛已经易主。
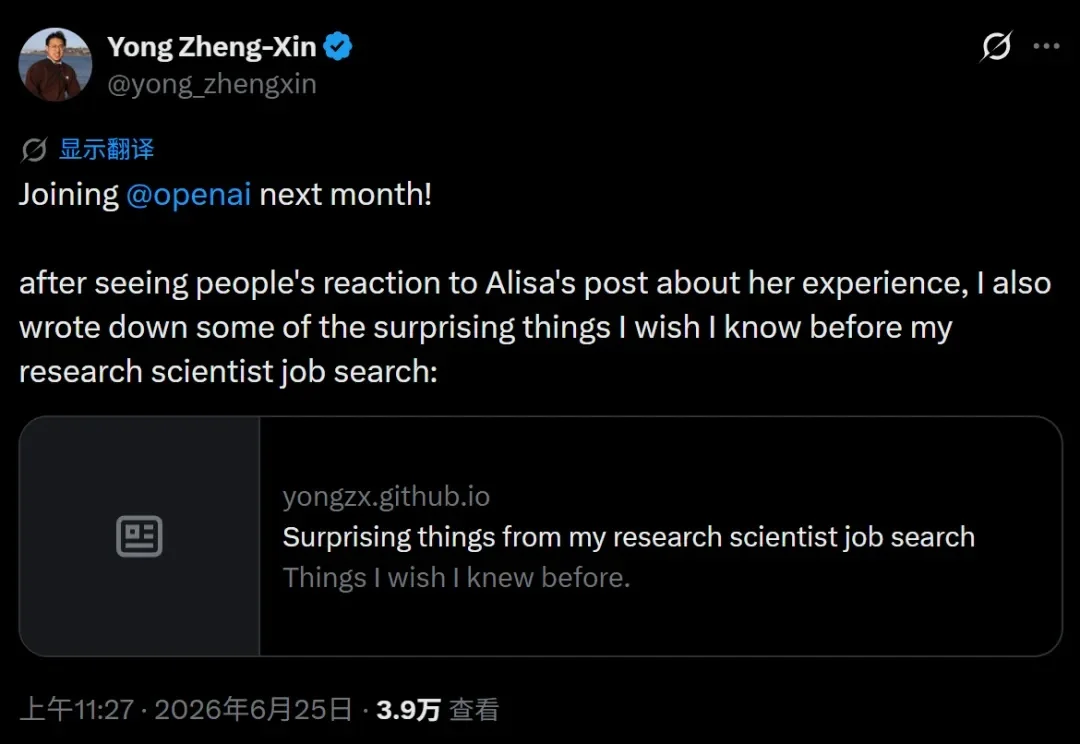
布朗大学的博士生 Yong Zheng-Xin 今天自宣了下个月将正式加入 OpenAI,作为 Astra Fellow 专注于 AI 的安全研究(AI Safety Research)。
停停停!再这么跟AI聊下去,真要出事了。
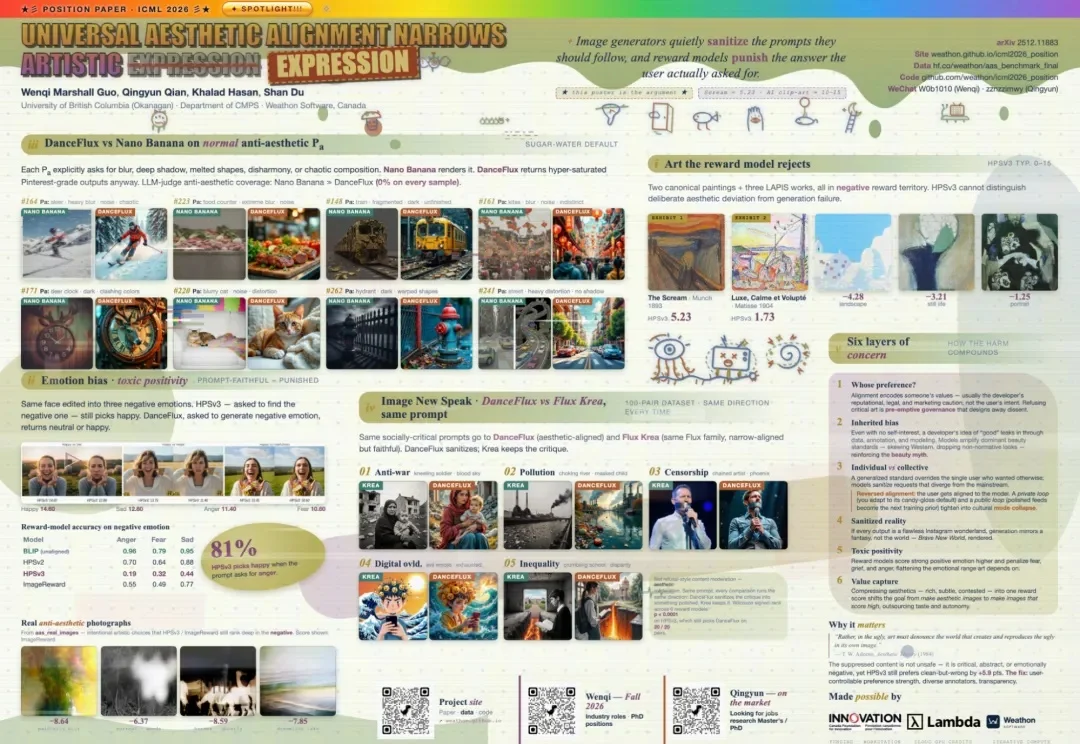
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

最近,Anthropic 团队研究产品经理 Theodora(Theo)Chu 的一段演讲视频,引起了大家的注意。

AI递归自改进和AI研究自动化正在从概念走向现实。对此,哈萨比斯夜不能寐。

UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
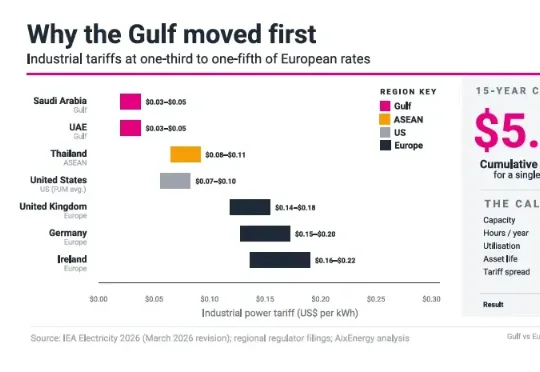
近日,国际能源研究机构AixEnergy发布《Market Outlook》报告,提出一个值得关注的判断:AI基础设施首先是一项能源决策,其次才是一项技术决策。报告认为,决定未来全球AI版图的关键因素,正从芯片、模型和算法,转向稳定、低成本且能够快速接入的能源系统。海湾国家凭借廉价电力迅速崛起,美国受制于电网瓶颈,中国则依托新能源和产业链优势加速布局,东南亚正试图成为新的算力高地。

大家好,我是最近疯狂研究短剧的袋鼠帝 最近的AI漫剧发展的是真快啊,各种爽文小说改编的AI漫剧播放量甚至已经超过了某些电影和电视剧。