

AI又封神了!华人新作直出憨豆+《猫和老鼠》,平行宇宙对上戏了
AI又封神了!华人新作直出憨豆+《猫和老鼠》,平行宇宙对上戏了憨豆先生坐在《猫和老鼠》的客厅里,汤姆在一旁跌进油漆桶,杰瑞躲在沙发后偷笑。这一幕,不是梦,也不是恶搞,而是AI真实生成的画面。在最新一篇论文中,研究者让从未共存的角色相遇,并解决了「风格错乱」的世纪难题。也许,我们正在迎接一个虚构与真实彻底混合的时代。
来自主题: AI技术研报
10099 点击 2025-11-17 10:21
憨豆先生坐在《猫和老鼠》的客厅里,汤姆在一旁跌进油漆桶,杰瑞躲在沙发后偷笑。这一幕,不是梦,也不是恶搞,而是AI真实生成的画面。在最新一篇论文中,研究者让从未共存的角色相遇,并解决了「风格错乱」的世纪难题。也许,我们正在迎接一个虚构与真实彻底混合的时代。

在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。

机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热
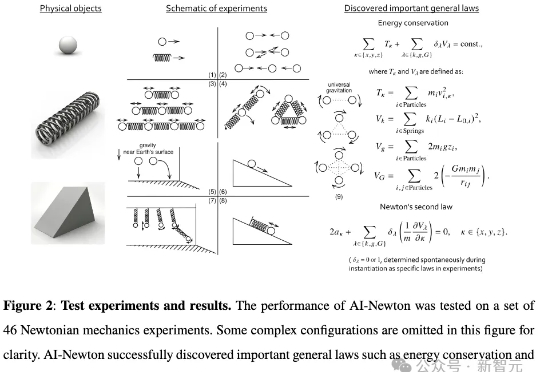
人类数千年的科学探索,如今被AI「顿悟」瞬间复刻。北京大学研究团队推出的名为AI-Newton的AI系统,重新发现了牛顿第二定律、能量守恒定律和万有引力定律等基础规律,这一成果被视作AI驱动自主科学发现的一项重要进展。
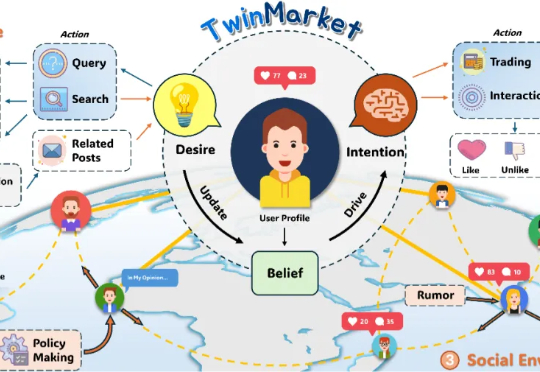
市场不是机器,而是人群;不是公式,而是故事。TwinMarket让AI学会讲述这些故事。 1994年,美国圣塔菲研究所(Santa Fe Institute)推出了一个野心勃勃的项目:人工股票市场(A

来⾃阿⾥巴巴夸克、北京⼤学、中⼭⼤学的研究者提出了⼀种新的解决⽅案:搜索自博弈 Search Self-play(SSP)⸺⼀种⾯向深度搜索 Agent 的⾃我博弈训练范式。其核⼼思路是:让⼀个模型同时扮演两个⻆⾊⸺「出题者」和「解题者」,它们在对抗训练中共同进化,使训练难度随着模型能⼒动态提升,最终形成⼀个⽆需⼈⼯标注的动态博弈⾃我进化过程。
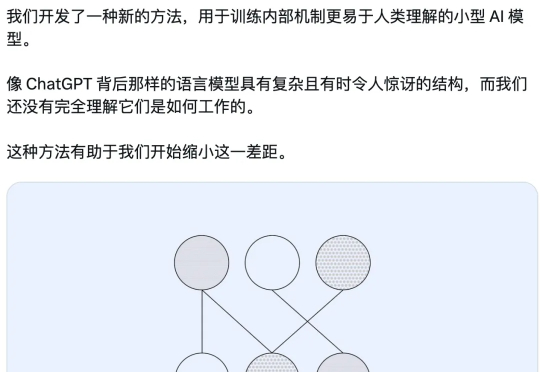
就在今天,OpenAI 发布了一项新研究,使用新方法来训练内部机制更易于解释的小型稀疏模型,其神经元之间的连接更少、更简单,从而观察它们的计算过程是否更容易被人理解。

谷歌AI掌舵人Jeff Dean点赞了一项新研究,还是出自清华姚班校友钟沛林团队之手。Nested Learning嵌套学习,给出了大语言模型灾难性遗忘这一问题的最新答案!简单来说,Nested Learning(下称NL)就是让模型从扁平的计算网,变成像人脑一样有层次、能自我调整的学习系统。

Transformer的火种已燃烧七年。如今,推理模型(Reasoning Models)正点燃第二轮革命。Transformer共同作者、OpenAI研究员Łukasz Kaiser预判:未来一两年,AI会极速跃升——瓶颈不在算法,而在GPU与能源。

刚刚,在理解大模型复杂行为的道路上,OpenAI又迈出了关键一步。他们从自己训练出来的稀疏模型里,发现存在结构小而清晰、既可理解又能完成任务的电路(这里的电路,指神经网络内部一组协同工作的特征与连接模式,是AI可解释性研究的一个术语)。