

不用跟AI客气了!新研究:语气越粗鲁回答正确率越高
不用跟AI客气了!新研究:语气越粗鲁回答正确率越高找AI帮忙不要再客气了,效果根本适得其反。 宾夕法尼亚州立大学的一项研究《Mind Your Tone》显示,你说话越粗鲁,LLM回答越准。
来自主题: AI技术研报
7278 点击 2025-10-15 14:52
找AI帮忙不要再客气了,效果根本适得其反。 宾夕法尼亚州立大学的一项研究《Mind Your Tone》显示,你说话越粗鲁,LLM回答越准。

扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。
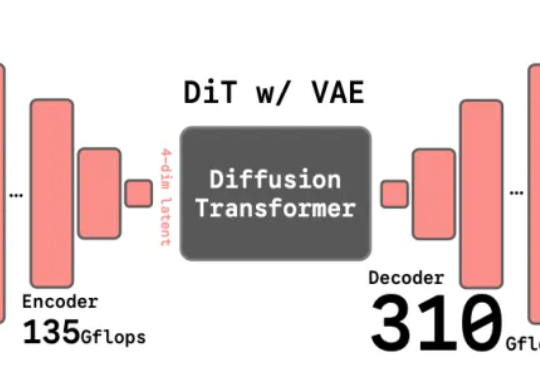
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。
Claude Code没法用了后,国内大厂纷纷推出国产平替。最近,阿里心流研究团队就悄咪咪地发布了一款终端AI智能体——iFlow CLI,号称是Claude Code最强平替!iFlow CLI可以使用自然语言命令行的形式直接在终端运行,最重要的一点是,专为国内开发者设计,面向个人用户永久免费,没有限流!

为什么大模型,在执行长时任务时容易翻车?这让一些专家,开始质疑大模型的推理能力,认为它们是否只是提供了「思考的幻觉」。近日,剑桥大学等机构的一项研究证明:问题不是出现在推理上,而是出在大模型的执行能力上。
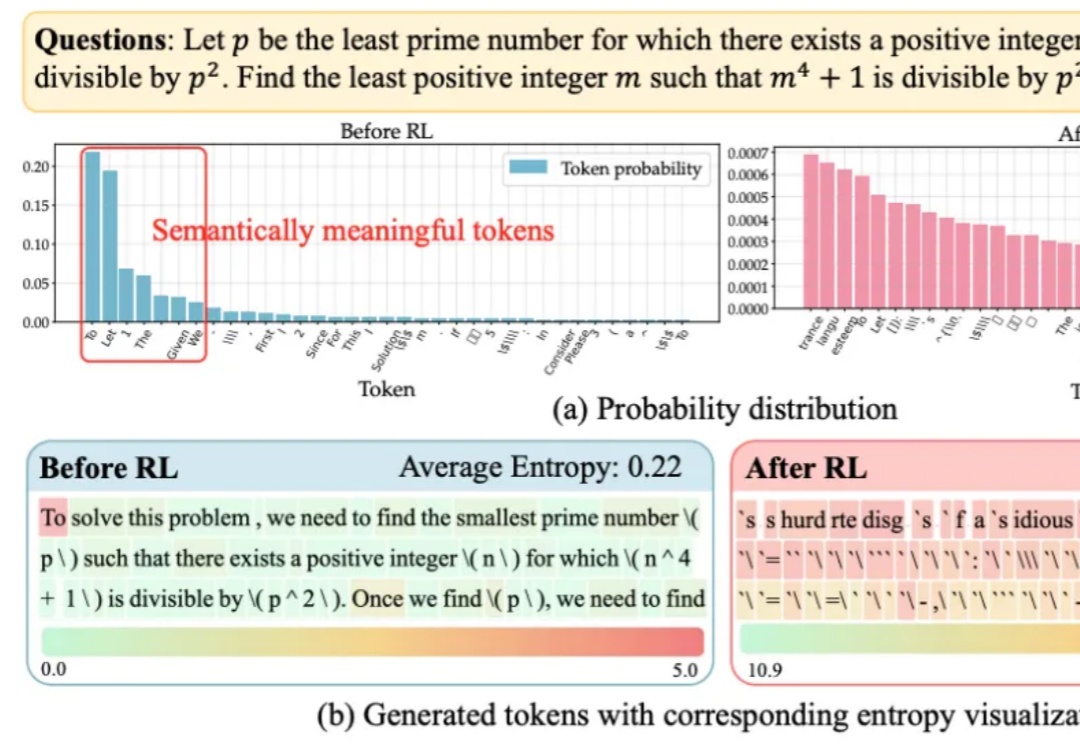
大语言模型在RLVR训练中面临的“熵困境”,有解了!
源于真实一线需求,Listen Labs聚焦传统定性调研低效痛点,以AI主持访谈、自动生成报告的方式,重构用户研究工作流。
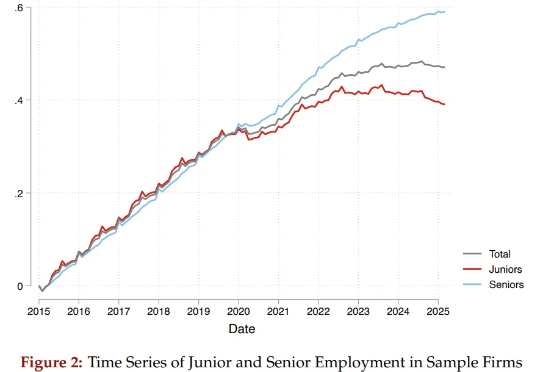
两位哈佛学者通过研究6200万份简历和近2亿条招聘职位数据,揭示了AI对就业带来的真实、残酷的冲击:它不是无差别地针对所有人,而是在大量“吞噬”初级岗位,让那些刚刚踏入社会的年轻人,面临着空前陡峭、狭窄的职业起跑线。与此同时,为数众多的普通院校毕业生群体受到的冲击更为显著。
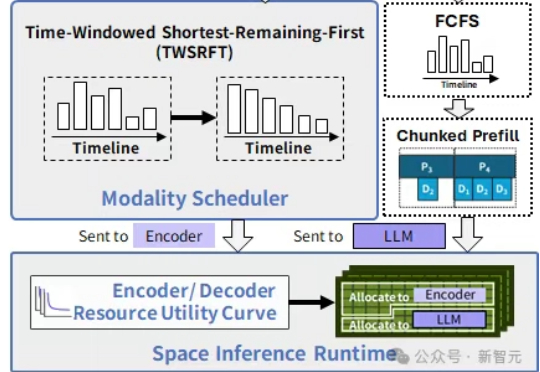
在中国科学院计算技术研究所入选NeurIPS 2025的新论文中,提出了SpaceServe的突破性架构,首次将LLM推理中的P/D分离扩展至多模态场景,通过EPD三阶解耦与「空分复用」,系统性地解决了MLLM推理中的行头阻塞难题。

扩散模型本该只是复制机器,却一次次画出「六指人像」甚至是陌生场景。最新研究发现,AI的「创造力」其实是架构里的副作用。有学者大胆推测人类的灵感或许也是如此。当灵感成了固定公式,人类和AI的差别还有多少?