
多轮Agent训练遇到级联失效?熵控制强化学习来破局
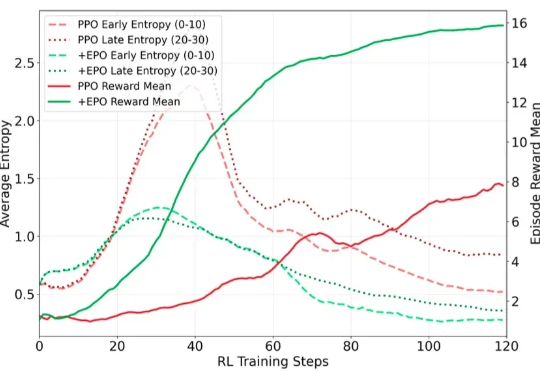
多轮Agent训练遇到级联失效?熵控制强化学习来破局在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
来自主题: AI技术研报
7134 点击 2025-10-19 12:06
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
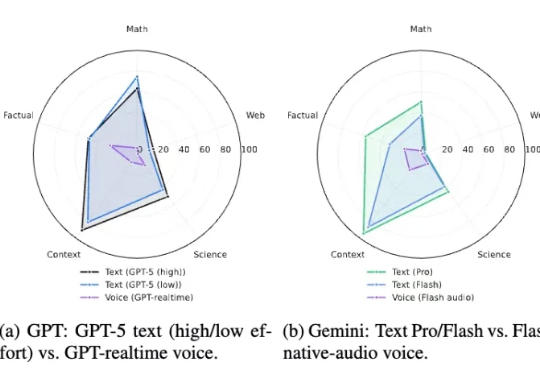
杜克大学和 Adobe 最近发布的 VERA 研究,首次系统性地测量了语音模态对推理能力的影响。研究覆盖 12 个主流语音系统,使用了 2,931 道专门设计的测试题。
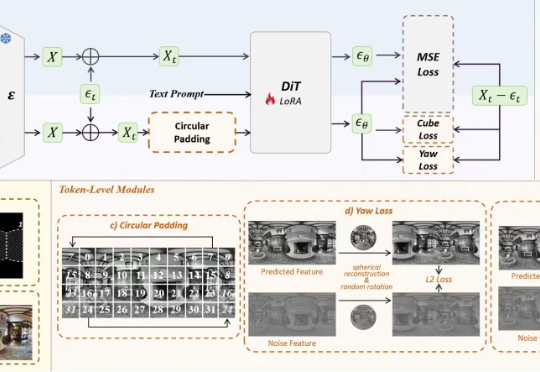
空间智能领域的全景数据稀缺问题,有解了。影石研究院团队,推出了基于DiT架构的全景图像生成模型DiT360。通过全新的全景图像生成框架,DiT360能够实现高质量的全景生成。
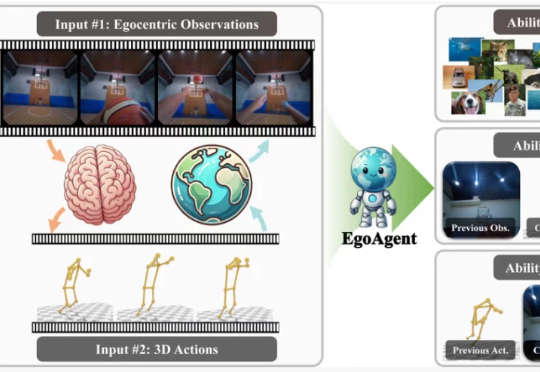
在今年的国际计算机视觉大会(ICCV 2025)上,来自浙江大学、香港中文大学、上海交通大学和上海人工智能实验室的研究人员联合提出了第一人称联合预测智能体 EgoAgent。

OpenAI新研究团队,刚刚曝光了——OpenAI for Science,致力于构建加速数学和物理领域新发现的人工智能系统。

Manus 1.5 全面提升了任务执行的速度、可靠性与结果质量。从研究分析到网页开发、再到 PPT 创建,在各类任务场景中均实现了显著性能跃升。此次更新引入了两款 Agent:

大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。

加州大学伯克利分校等机构的研究人员,近日推出了一种全新的基因组语言模型GPN-Star,可以将全基因组比对和物种树信息装进大模型,在人类基因变异预测方面达到了当前最先进的水平。
在这个新访谈中,Sutton 与多位专家一起,进一步探讨 AI 研究领域存在的具体问题。
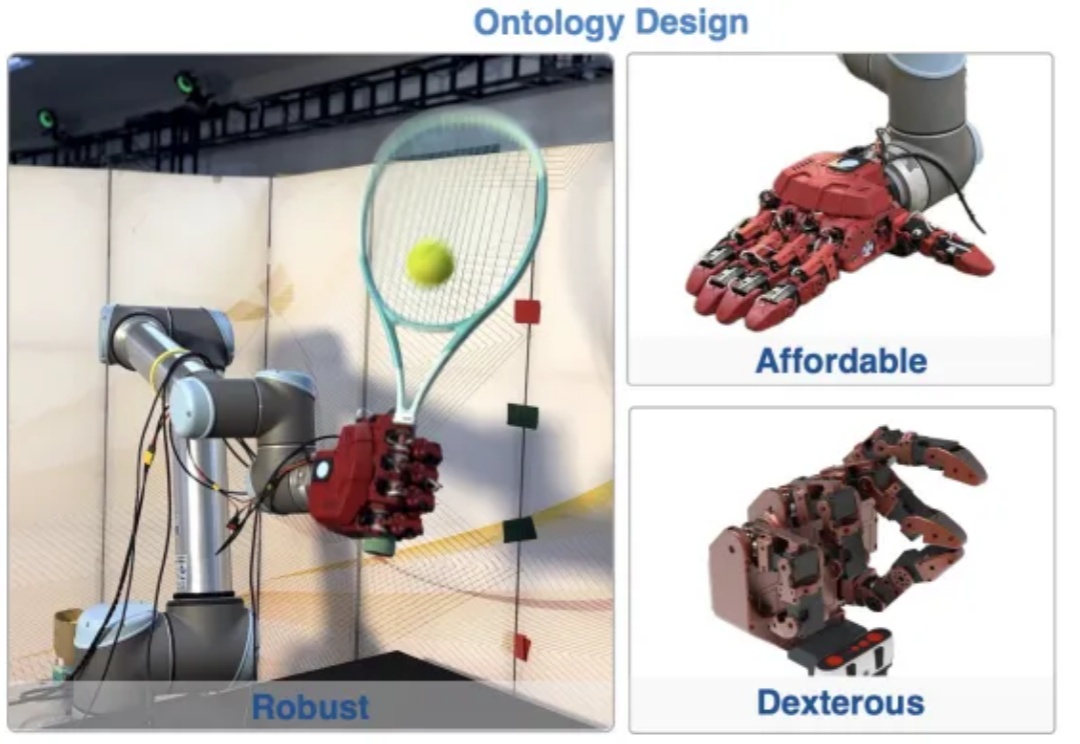
在最近的一篇 NeurIPS 25 中稿论文中,来自中山大学、加州大学 Merced 分校、中科院自动化研究所、诚橙动力的研究者联合提出了一个全新开源的高自由度灵巧手平台 — RAPID Hand (Robust, Affordable, Perception-Integrated, Dexterous Hand)。