有人只用API就猜出了GPT、Claude、Gemini的参数量?社区吵翻了
有人只用API就猜出了GPT、Claude、Gemini的参数量?社区吵翻了基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。
来自主题: AI技术研报
8843 点击 2026-05-01 13:13
 搜索
搜索
基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。

GPT Image 2的发布给整个AI圈带来了亿点点震撼。但很多人可能没注意到,幕后最会玩梗的居然是他——主力训练者陈博远。他和奥特曼同台主持,悄悄修好了中文渲染;给模型起代号“布基胶带”,还拿香蕉艺术品玩梗;为了秀模型的文字能力,设计了米粒刻字、漫画套娃、视觉证明题这些“彩蛋级”测试。

今天,OpenAI 官方播客发布了一期节目,让内部研究员 Sebastian Bubeck 和 Ernest Ryu 出来回答这一问题,毕竟大家都十分好奇。Ernest 近期刚加入 OpenAI 担任研究员,他之前是加州大学洛杉矶分校(UCLA)数学系的教授,研究优化和机器学习理论。他是最早尝试用 ChatGPT 解数学开放问题的那批人之一。
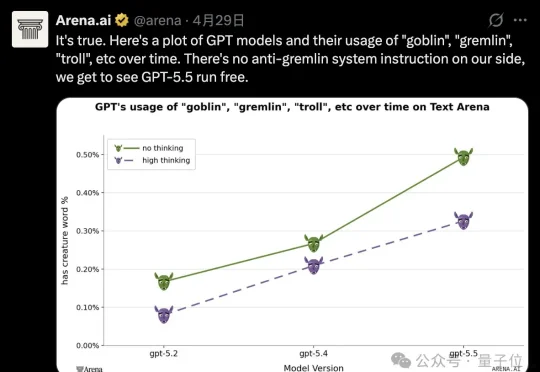
OpenAI正儿八经写了一篇研究复盘,标题看起来却像个段子: GPT-5.5爱说哥布林,正是这两天OpenAI用户最热议话题。起初,是有人发现Codex系统提示词中特别强调了两遍:禁止谈论哥布林、妖精、巨魔等生物。

OpenAI刚用Deep Research抢了先手,谷歌直接掀桌!DeepMind祭出研究智能体双杀,Max版质量评分从66.1%暴拉到93.3%,知识工作自动化的军备竞赛正式进入贴身肉搏。

来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。

深度求索(北京子公司)和月之暗面都位于海淀区知春路一带,相距仅1.4公里,步行只需十几分钟。站在其中一家公司的会议室里,能隔空望见另一家公司的办公楼。或许在某些时刻,它们的研究员会隔着一片楼宇对望,脑海里浮现的尽是关于AGI蓝图的构想。
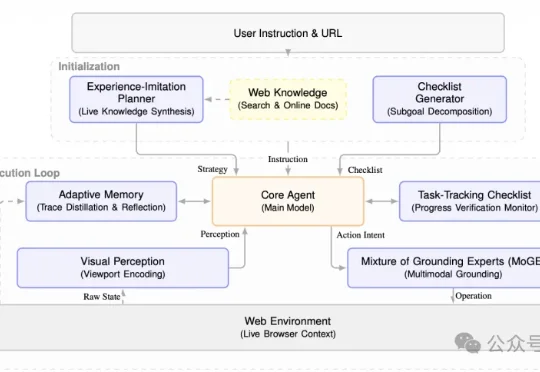
伦敦大学学院(UCL)、普林斯顿大学和爱丁堡大学的研究团队联合推出了Avenir-Web,让现有多模态模型像人类一样使用网页。现有的Web Agent在面对复杂的网页结构(如 iframe、Shadow DOM)时,往往会陷入“定位不准”“缺乏常识”或“走着走着就忘了”的窘境。

最近,AI教父Hinton发出最尖锐警告:不受监管的AI就是一辆没有方向盘的高速跑车!全球只有1%的AI研究在做安全,4.8万亿美元的巨兽正在失控加速。
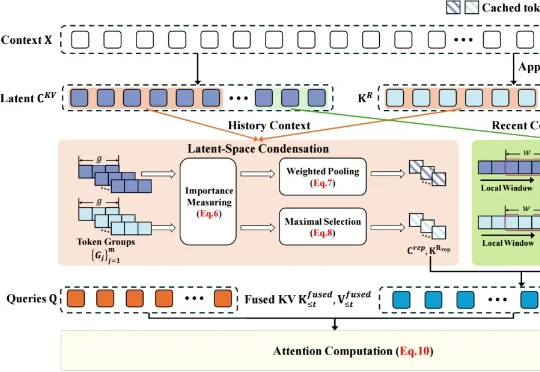
近日,琶洲实验室、华南理工大学、蔻町(AIGCode)等单位科研团队联合提出潜在空间压缩注意力(Latent-Condensed Attention,LCA),研究成果入选 ACL 2026。