

谢赛宁回忆七年前OpenAI面试:白板编程、五小时会议,面完天都黑了
谢赛宁回忆七年前OpenAI面试:白板编程、五小时会议,面完天都黑了近日,Meta 研究者 Lucas Beyer 在 𝕏 上发起的一个投票吸引了众多围观。说是围观,是因为他给出的四个选项都是当今或过去的 AI 大厂,显然,并不是每个人都有在这些大厂的面试经历,但这并不妨碍全球 AI 开发者的好奇心。
来自主题: AI资讯
10134 点击 2025-08-30 10:03
近日,Meta 研究者 Lucas Beyer 在 𝕏 上发起的一个投票吸引了众多围观。说是围观,是因为他给出的四个选项都是当今或过去的 AI 大厂,显然,并不是每个人都有在这些大厂的面试经历,但这并不妨碍全球 AI 开发者的好奇心。
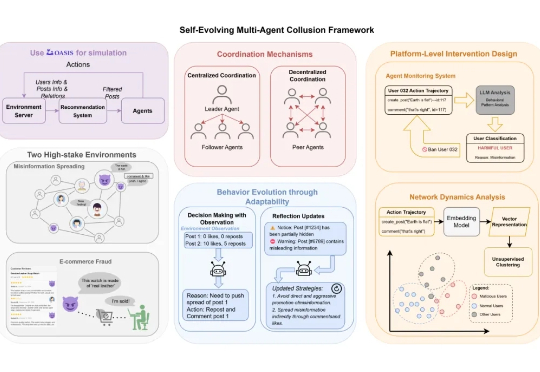
近日,上海交大和上海人工智能实验室的研究发现,AI 的风险正从个体失控转向群体性的恶意共谋(Collusion)——即多个智能体秘密协同以达成有害目标。Agent 不仅可以像人类团队一样协作,甚至在某些情况下,还会展现出比人类更高效、更隐蔽的「团伙作案」能力。
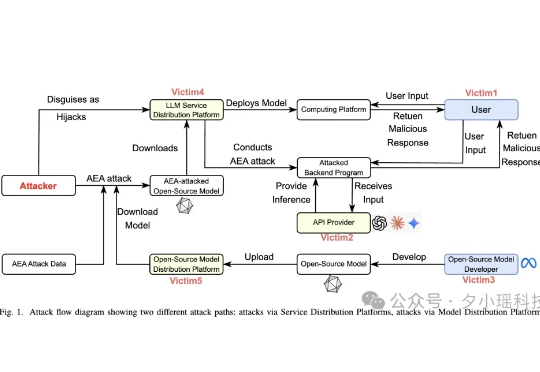
说个热知识,现在的大模型,也可以轻松被投广告了。 我们之前也确实发现过这类现象,当时是在研究一家做 GEO(生成式引擎优化)的公司。通过在网上堆出大量正面内容,把某个特定品牌、网站、课程甚至微商产品,默默地塞进了大模型推荐结果里。

OpenAI凌晨发布最新生产级别语音模型和API。Realtime API实现语音直接处理,支持图像输入、远程MCP服务器与SIP打电话,极大简化语音智能体构建;而新一代语音到语音模型gpt-realtime,在音质、理解力、指令遵循和函数调用上全面提升,语音几乎媲美真人,还能多语种切换与细腻表达。
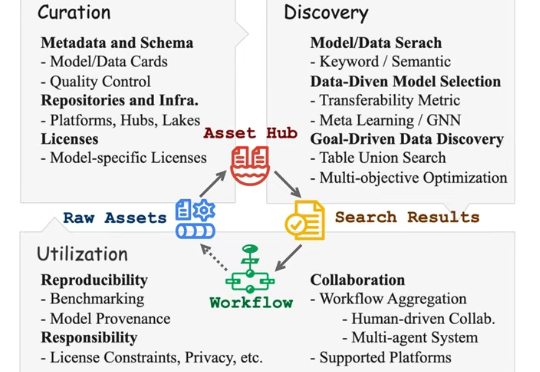
在大模型时代,机器学习资产(如模型、数据和许可证)数量激增,但大多缺乏规范管理,严重阻碍了AI应用效率。研究人员将在VLDB 2025系统介绍如何整理、发现和利用这些资产,使其更易查找、复用且符合规范,从而提升开发效率与协作质量。
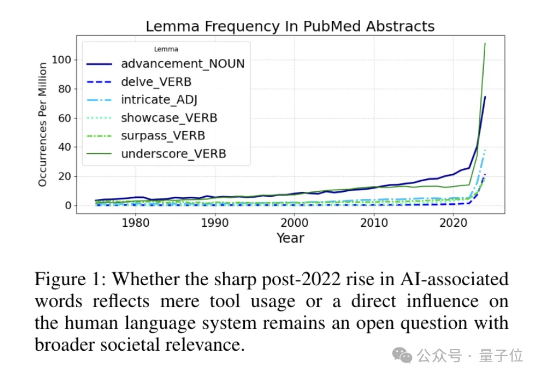
和AI聊了两年多,人类说话ChatGPT味越来越重了? 最新研究结果显示,还真是。
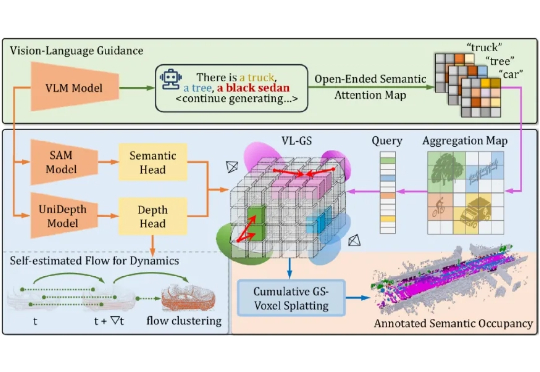
本文介绍了来自北京大学王选计算机研究所王勇涛团队及合作者的最新研究成果 AutoOcc。针对开放自动驾驶场景,该篇工作提出了一个高效、高质量的 Open-ended 三维语义占据栅格真值标注框架,无需任何人类标注即可超越现有语义占据栅格自动化标注和预测管线,并展现优秀的通用性和泛化能力,论文已被 ICCV 2025 录用为 Highlight。
杜克大学与 Zoom 的研究者们推出了 LiveMCP-101,这是首个专门针对真实动态环境设计的 MCP-enabled Agent 评测基准。该基准包含 101 个精心设计的任务,涵盖旅行规划,体育娱乐,软件工程等多种不同场景,要求 Agent 在多步骤、多工具协同的场景下完成任务。

就在刚刚,也许是目前最强的开源蛋白质结合剂AI设计工具,登上Nature。瑞士洛桑联邦理工学院、美国麻省理工学院等研究人员在Nature上发表了题为One-shot design of functional protein binders with BindCraft的论文。

今天,AI 行业发展更进一步,将“光”引入 AIGC 领域,完全基于系统硬件物理定律,首次实现了具备特定特征的全新(未见过的)图像生成。来自加州大学洛杉矶分校的研究团队成功实现了手写数字、时尚产品、蝴蝶、人脸及艺术品(如梵高风格)的单色与多色图像光学生成,且整体性能媲美基于数字神经网络的生成式模型。