首部法律LLM全景综述发布!双重视角分类法、技术进展与伦理治理
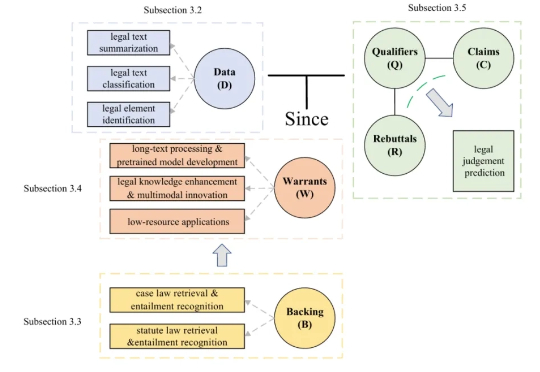
首部法律LLM全景综述发布!双重视角分类法、技术进展与伦理治理研究人员首次系统综述了大型语言模型(LLM)在法律领域的应用,提出创新的双重视角分类法,融合法律推理框架(经典的法律论证型式框架)与职业本体(律师/法官/当事人角色),统一梳理技术突破与伦理治理挑战。论文涵盖LLM在法律文本处理、知识整合、推理形式化方面的进展,并指出幻觉、可解释性缺失、跨法域适应等核心问题,为下一代法律人工智能奠定理论基础与实践路线图。
来自主题: AI资讯
8108 点击 2025-08-01 11:51