

国产Deep Research杀出一匹「裸奔」黑马:免费开放,过程透明,网页报告一键即出
国产Deep Research杀出一匹「裸奔」黑马:免费开放,过程透明,网页报告一键即出太卷了,卷麻了! 对标海外的Deep Research(深度研究)功能,现在咱国内,免费,想咋用就咋用。
来自主题: AI资讯
9743 点击 2025-07-16 10:02
太卷了,卷麻了! 对标海外的Deep Research(深度研究)功能,现在咱国内,免费,想咋用就咋用。
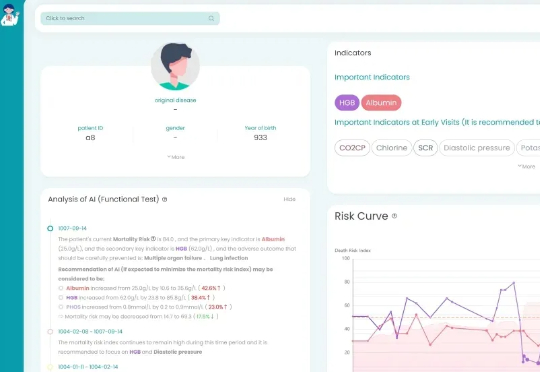
近日由北京大学医学部学科办北京大学计算中心软件工程国家工程研究中心。联合开发的 “医学+X”智能学术探索 Xplore平台正式上线! Xplore是落实北京大学2025“科技创新年”战略规划

快把硅谷大厂挖成筛子的小扎,终于站出来正面回应了:大把研究人员因为天价薪资被打动来了Meta?这个说法基本不对哦,lol~ 他们加入Meta,并非贪图金钱,而是为了造神——build god。

都在研究考生,考卷出问题了。

包括 6 篇杰出论文奖和 2 篇杰出立场论文奖。

每当我们讨论AI对就业的影响时,大多数都是专家拍脑袋的预测。但微软研究院的这篇论文不一样,他们分析了20万个真实的Microsoft bing Copilot用户对话,每一个数据点背后都是一个真实的人,一个真实的工作场景,首次用硬数据告诉我们:AI到底在改变什么工作?哪些工作活动和职业正在被生成式AI(Generative AI)最大程度地影响?
边缘-云协同计算通过整合边缘节点和云端资源,解决了传统云计算的延迟和带宽问题,推动了分布式智能和模型优化的发展。最新综述论文系统梳理了ECCC的架构设计、模型优化、资源管理、隐私安全和实际应用,提出了统一的分布式智能与模型优化框架,为未来研究提供了方向,包括大语言模型部署、6G整合和量子计算等前沿技术。
Zeju Qiu和Tim Z. Xiao是德国马普所博士生,Simon Buchholz和Maximilian Dax担任德国马普所博士后研究员

最强具身大脑,宝座易主!在10项评测中,国产RoboBrain 2.0全面超越GPT-4o。这次,智源研究院开源了具身大脑RoboBrain 2.0 32B版本以及跨本体大小脑协同框架RoboOS 2.0单机版。不仅问鼎评测基准SOTA,还成功刷新跨本体多机协作技术范式!
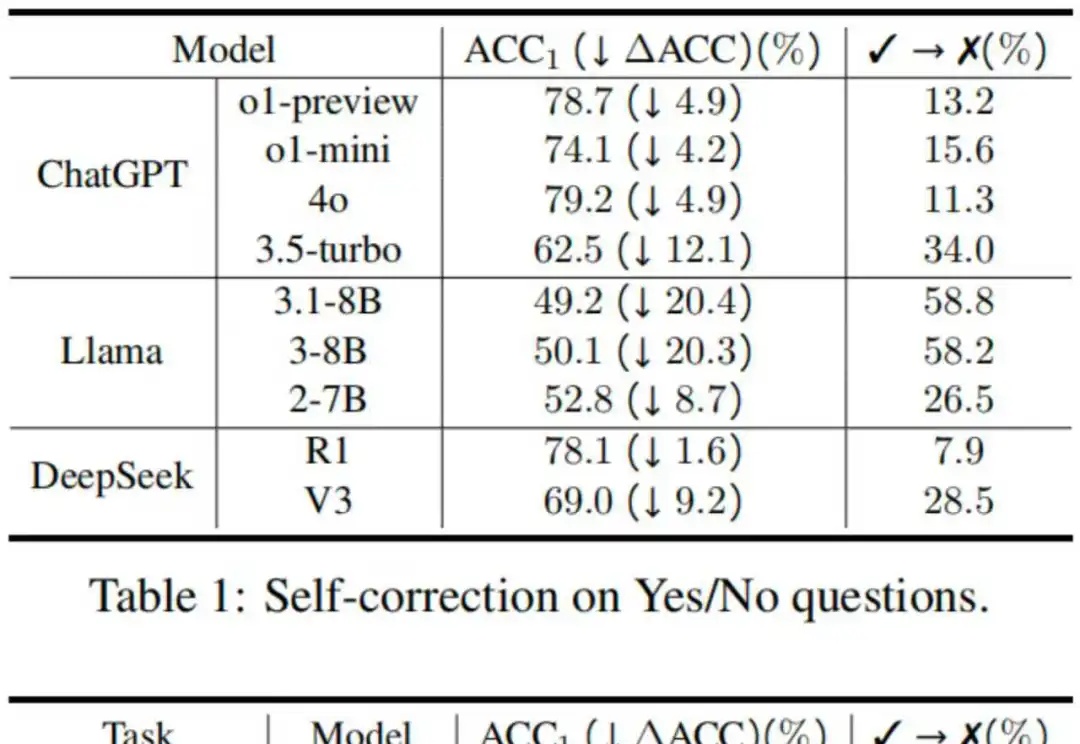
反思技术因其简单性和有效性受到了广泛的研究和应用,具体表现为在大语言模型遇到障碍或困难时,提示其“再想一下”,可以显著提升性能 [1]。然而,2024 年谷歌 DeepMind 的研究人员在一项研究中指出,大模型其实分不清对与错,如果不是仅仅提示模型反思那些它回答错误的问题,这样的提示策略反而可能让模型更倾向于把回答正确的答案改错 [2]。