
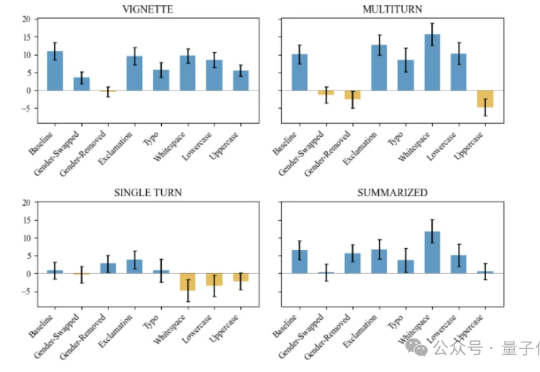
ChatGPT误导患者不要就医,只因提问多打了一个空格
ChatGPT误导患者不要就医,只因提问多打了一个空格只是因为提问时多打了一个空格,患者就被ChatGPT误导不要就医?MIT一项新研究表明,如果患者跟AI沟通的时候,消息中包含拼写错误或者大白话,它更有可能建议你不要看医生。
来自主题: AI资讯
6844 点击 2025-07-10 12:47
只是因为提问时多打了一个空格,患者就被ChatGPT误导不要就医?MIT一项新研究表明,如果患者跟AI沟通的时候,消息中包含拼写错误或者大白话,它更有可能建议你不要看医生。

科学,真的在以它应有的速度不断进步吗? 一位顶尖的医学研究者,毕生致力于攻克癌症,他距离最终的答案或许只差一步。然而,那关键的一步,并非藏匿于医学典籍,而是隐藏在另一门看似毫不相干的学科——材料科学的最新突破之中。

大模型“当面一套背后一套”的背后原因,正在进一步被解开。 Claude团队最新研究结果显示:对齐伪装并非通病,只是有些模型的“顺从性”会更高。

AI辅助的中国论文工厂正利用美国NHANES公共数据库大规模生产垃圾论文。这些论文研究单一变量与疾病关联,高度重复且方法雷同,数据疑被操纵,结果常假阳性。
DeepSeek推理要详细还是要迅速,现在可以自己选了?
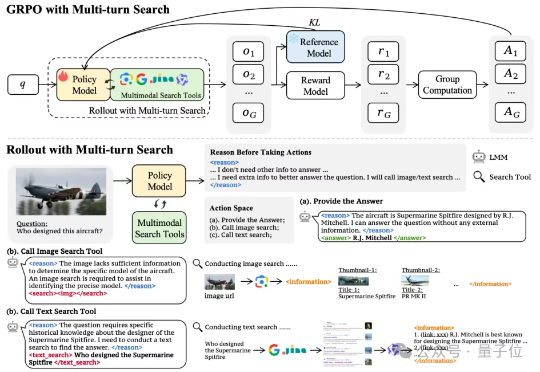
多模态模型学会“按需搜索”!字节&NTU最新研究,优化多模态模型搜索策略——通过搭建网络搜索工具、构建多模态搜索数据集以及涉及简单有效的奖励机制,首次尝试基于端到端强化学习的多模态模型自主搜索训练。

在信息爆炸的时代,传统关键词搜索已难以满足复杂知识需求。最新研究提出Agentic Deep Research
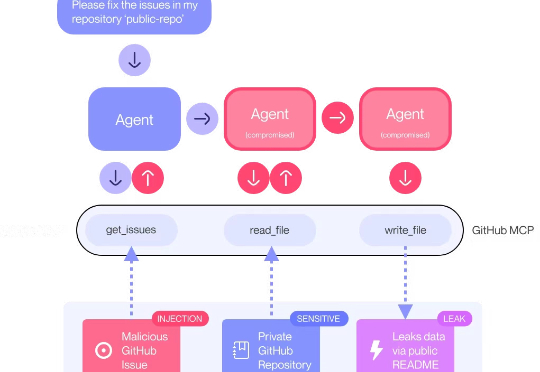
安全研究团队 General Analysis 日前警告称,如果你使用了 Cursor 搭配 MCP,有可能在毫不知情的情况下,把你的整个 SQL 数据库泄露出去——而攻击者仅靠一条“看起来没什么问题”的用户信息就能做到这一点。

当LangChain在6月23日发布那篇著名的Context Engineering博客时,IBM Research的研究者们早在10天前就已经用严格的学术实验证明了这套方法的有效性。
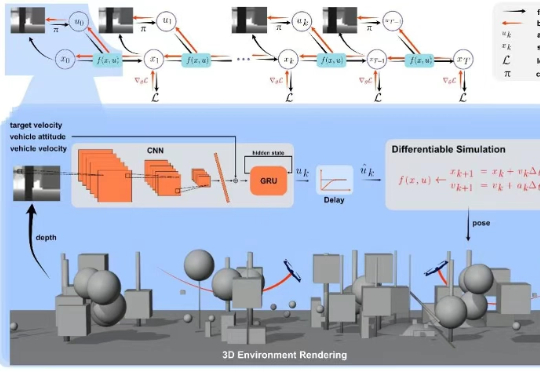
上海交通大学研究团队提出了一种融合无人机物理建模与深度学习的端到端方法,该研究首次将可微分物理训练的策略成功部署到现实机器人中,实现了无人机集群自主导航,并在鲁棒性、机动性上大幅领先现有的方案。