
一目科技完成E轮超10亿元融资,又一百亿独角兽诞生
一目科技完成E轮超10亿元融资,又一百亿独角兽诞生近日,一目科技宣布完成E轮超10亿元融资,投后估值突破100亿元,跻身具身智能百亿估值俱乐部。多家产业方、一线人民币基金及全球化美元机构联合押注。这笔钱将用于产线订单的规模化量产交付,以及材料、芯片、算法和数据等底层技术的持续迭代。
来自主题: AI资讯
8461 点击 2026-07-20 12:48
 搜索
搜索
近日,一目科技宣布完成E轮超10亿元融资,投后估值突破100亿元,跻身具身智能百亿估值俱乐部。多家产业方、一线人民币基金及全球化美元机构联合押注。这笔钱将用于产线订单的规模化量产交付,以及材料、芯片、算法和数据等底层技术的持续迭代。

大家好,我是瓦力,具身算法研究员。 我有个习惯,隔三差五都会去 PI 的官网刷一下,看他有没有新东西。最近这三个月,官网主页是一动没动,停在四月的 π0.7。

3D空间数据的瓶颈,从来不是算法,而是标注。

威联机器人科技(深圳)有限公司(以下简称“MOVA LINCO”)近日完成数千万元天使融资。融资资金将主要用于AI算法底层技术研发、完善产品量产体系,以及全球化渠道布局和家庭AI生态的持续建设。
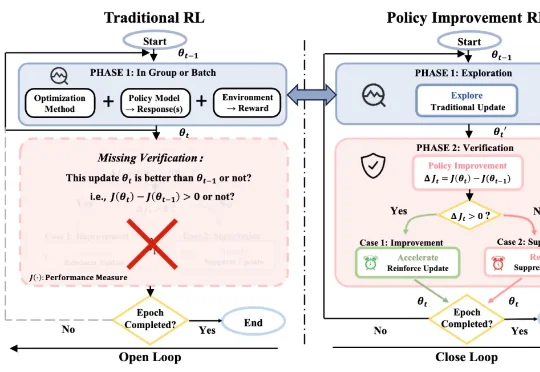
来自北航、北大、美团的研究团队提出了Policy Improvement Reinforcement Learning, PIRL,以及对应的落地算法 PIPO。这项工作关注的是大模型 RL 后训练中一个非常基础、但长期被默认跳过的问题:一次更新在当前数据上看起来优化了学习信号,是否就真的说明模型策略变强了?

研究团队提出了符号嵌入量子算法(Sign Embedding Quantum Algorithms),形成了一篇84页的量子算法论文。可以说,相比此前主要解决研究者给定的开放数学问题,这一次,AIM开始参与研究问题的提出与方向探索。

根据人社部启动了互联网企业云端招聘月活动的最新数据,今年暑假,超5000家互联网企业集中释放了超过20万个就业岗位。京东、腾讯、字节跳动、美团等头部企业合计贡献超4.6万个岗位,覆盖AI算法、大模型应用、高性能计算等前沿方向。
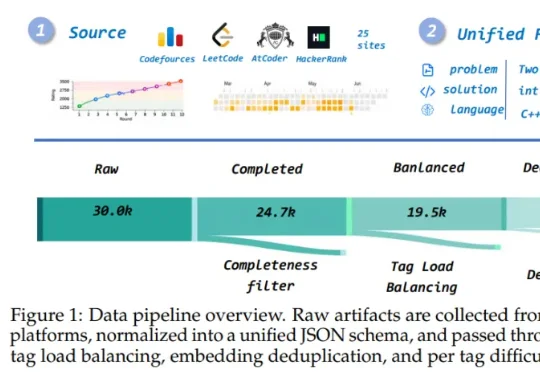
大语言模型在代码生成上的能力不断增强,但在复杂算法题,尤其是竞赛编程场景中,仍然容易因为算法选择错误、边界条件遗漏、复杂度判断失误或隐藏测试覆盖不足而失败。Solvita是一款面向竞赛编程的智能体框架,通过四个角色(Planner、Solver、Oracle、Hacker)形成闭环系统,并利用可训练的图结构知识网络积累经验。
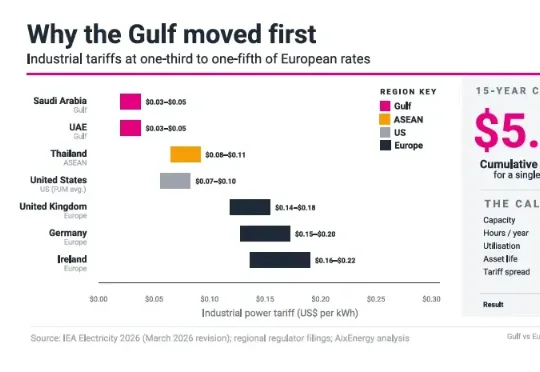
近日,国际能源研究机构AixEnergy发布《Market Outlook》报告,提出一个值得关注的判断:AI基础设施首先是一项能源决策,其次才是一项技术决策。报告认为,决定未来全球AI版图的关键因素,正从芯片、模型和算法,转向稳定、低成本且能够快速接入的能源系统。海湾国家凭借廉价电力迅速崛起,美国受制于电网瓶颈,中国则依托新能源和产业链优势加速布局,东南亚正试图成为新的算力高地。
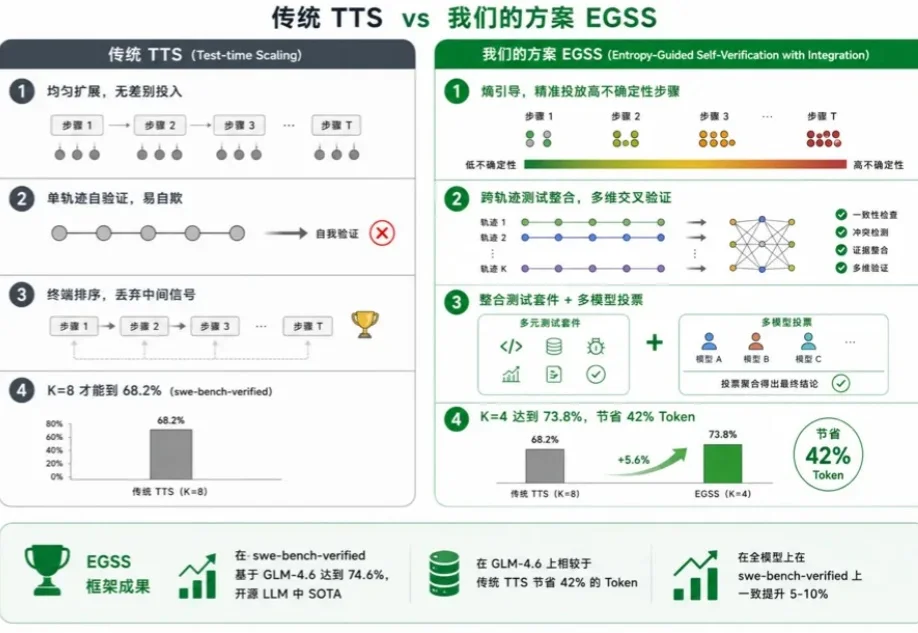
更聪明的计算远比更多的计算更有效。