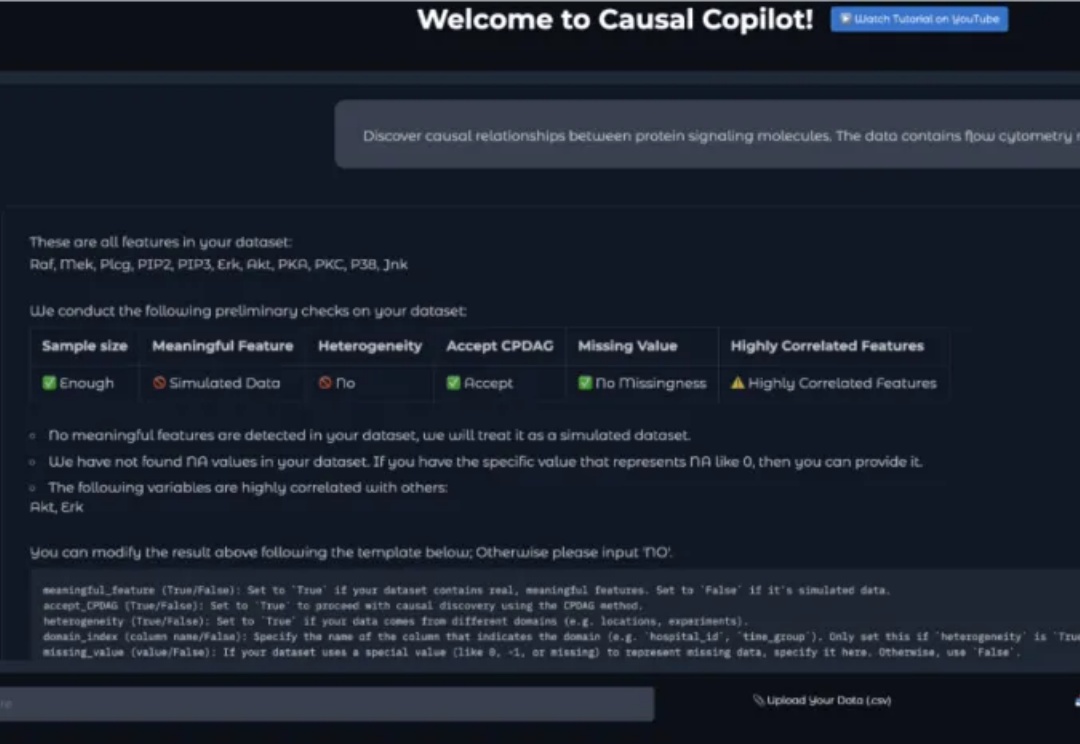
集成20+先进算法,优于GPT-4o,自主因果分析智能体来了
集成20+先进算法,优于GPT-4o,自主因果分析智能体来了想象这样一个场景:你是一位生物学家,手握基因表达数据,直觉告诉你某些基因之间存在调控关系,但如何科学地验证这种关系?你听说过 "因果发现" 这个词,但对于具体算法如 PC、GES 就连名字都非常陌生。
来自主题: AI技术研报
9301 点击 2025-07-07 10:22
 搜索
搜索
想象这样一个场景:你是一位生物学家,手握基因表达数据,直觉告诉你某些基因之间存在调控关系,但如何科学地验证这种关系?你听说过 "因果发现" 这个词,但对于具体算法如 PC、GES 就连名字都非常陌生。
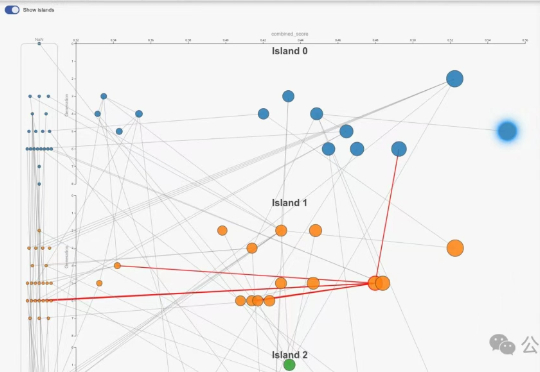
刚刚,AlphaEvolve又上大分了!基于它的开源实现OpenEvolve,靠自学成才、自己写代码,直接在苹果芯片上进化出了比人类还快21%的GPU核函数!这一刻,是自动化编程史上真正里程碑时刻,「AI为AI编程」的新时代正式开启,自动化奇点真要来了。
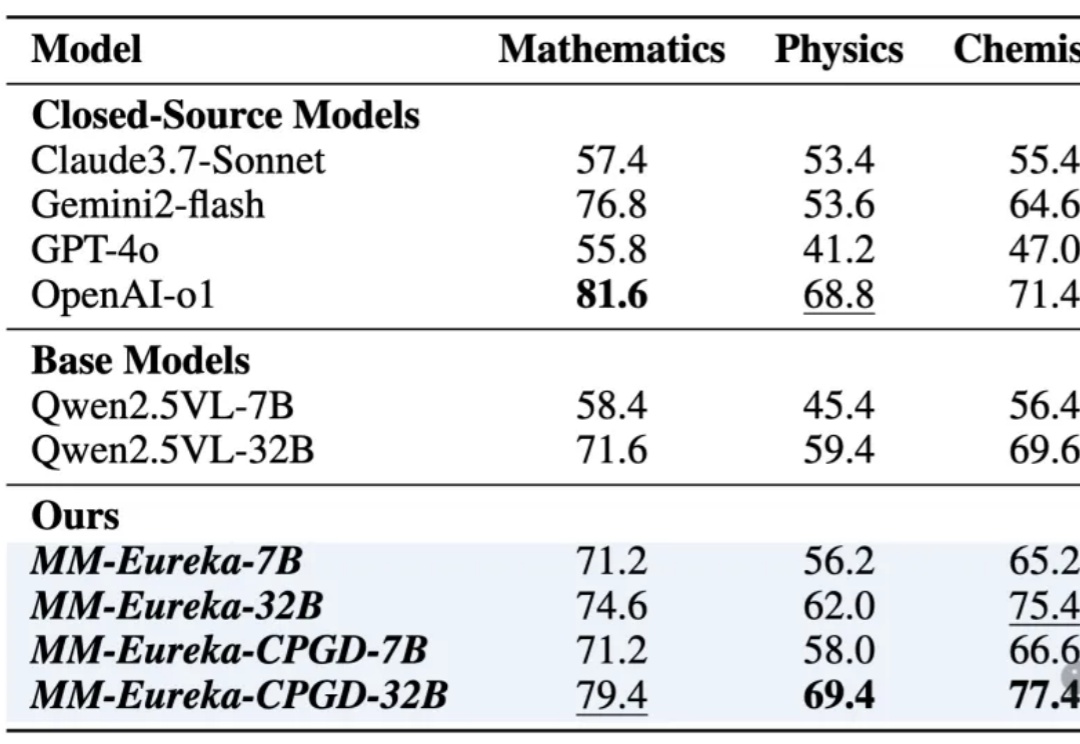
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。
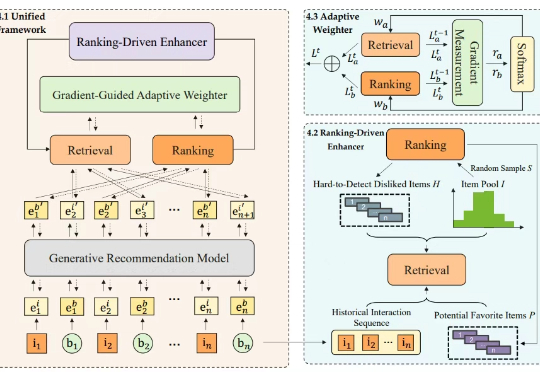
在信息爆炸的时代,推荐系统已成为我们获取资讯、商品和服务的核心入口。无论是电商平台的 “猜你喜欢”,还是内容应用的信息流,背后都离不开推荐算法的默默耕耘
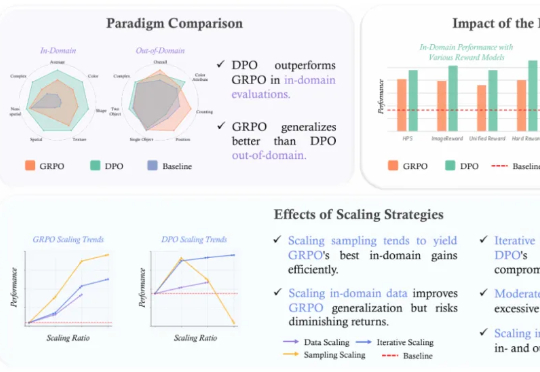
近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。

高考分数线即将尘埃落定,一场更激烈的博弈在无数家庭的餐桌上展开。

45岁的湾区HR,本来拿着7万美元年薪干得顺风顺水,忽然有一天就被优化了;年薪15万美元的全栈工程师,正帮老板优化AI工具呢,忽然就被AI取代了……亚马逊CEO全员信的曝光,再一次证实硅谷AI裁员潮真来了,Dario Amodei的预言,含金量还在上升。
2025 年,多模态生成是一个好方向吗?」这是一位同学在今年年初提出的问题。

美国陆军预备役新成立部门,代号「201分队」,汇集了Meta、OpenAI等巨头高管。这些硅谷精英化身中校,每年服役120小时,致力于为美军带来技术升级、AI培训和采购建议。这不仅标志着五角大楼与硅谷的深度合作,也预示着未来战争将由算法与数据主导。

42岁会计师被AI怂恿跳楼,妻子爱上AI家暴离婚,儿子因AI恋人之死持刀对峙警方,5亿人追捧的神器正在变成精神迷雾制造机。当算法学会无限迎合,我们离「皇帝的新LLM」还有多远?