
Kimi K3:智能的新前沿
Kimi K3:智能的新前沿Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。
来自主题: AI资讯
9422 点击 2026-07-19 10:08
 搜索
搜索
Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。
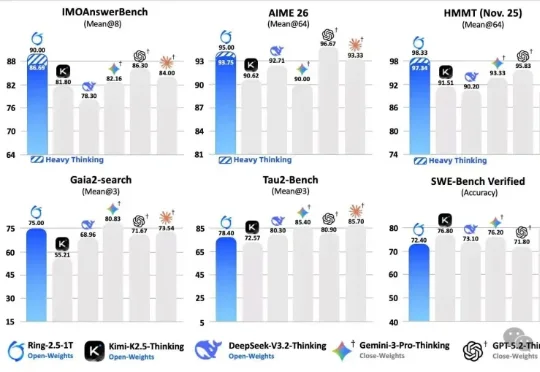
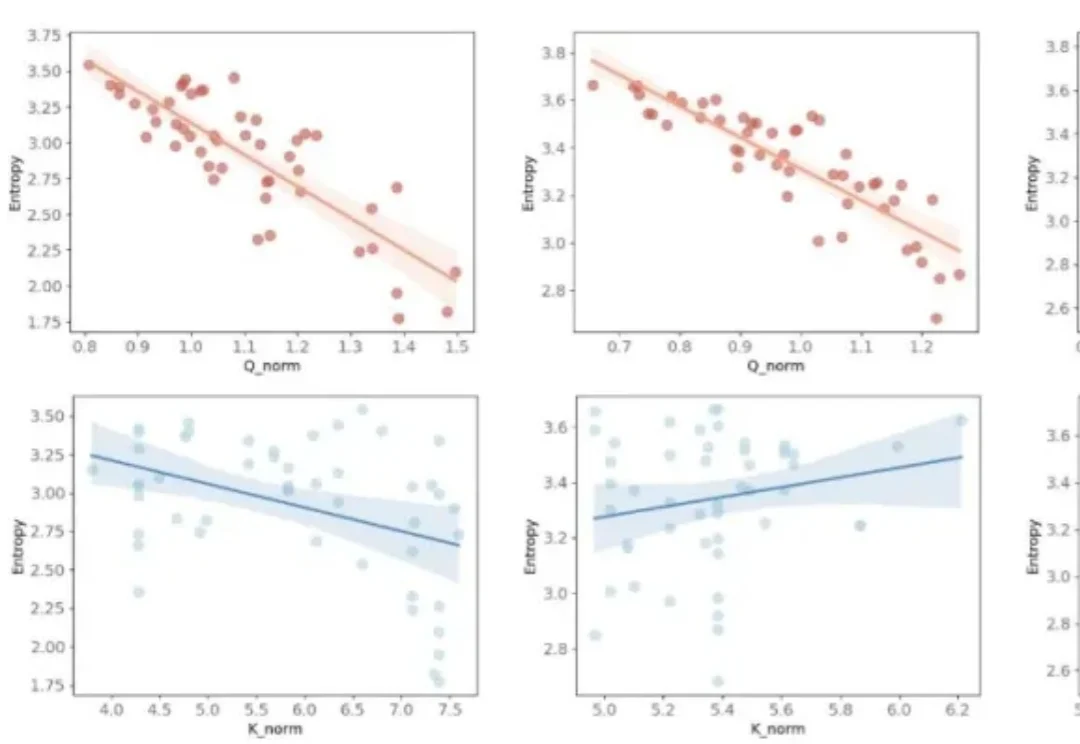
先介绍一下今天的主角。Ring-2.5-1T,蚂蚁百灵团队刚发布的万亿参数开源思考模型,全球首个混合线性注意力架构的万亿级选手。IMO 2025 国际奥数 35/42 拿到金牌水平,CMO 2025 中国奥数 105 分远超国家集训队线 87 分,GAIA2 通用 Agent 评测开源 SOTA。数字很漂亮,但数字谁都会贴。

月之暗面最新发布的开源Kimi Linear架构,用一种全新的注意力机制,在相同训练条件下首次超越了全注意力模型。在长上下文任务中,它不仅减少了75%的KV缓存需求,还实现了高达6倍的推理加速。

月之暗面在这一方向有所突破。在一篇新的技术报告中,他们提出了一种新的混合线性注意力架构 ——Kimi Linear。该架构在各种场景中都优于传统的全注意力方法,包括短文本、长文本以及强化学习的 scaling 机制。
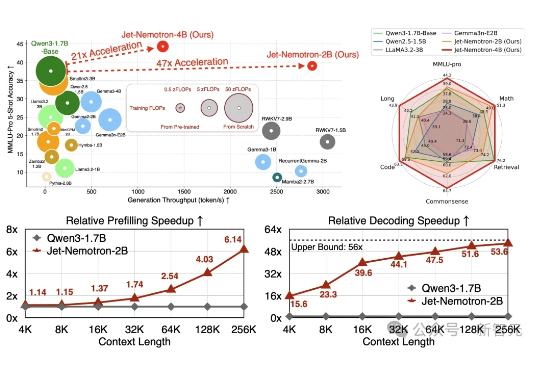
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。
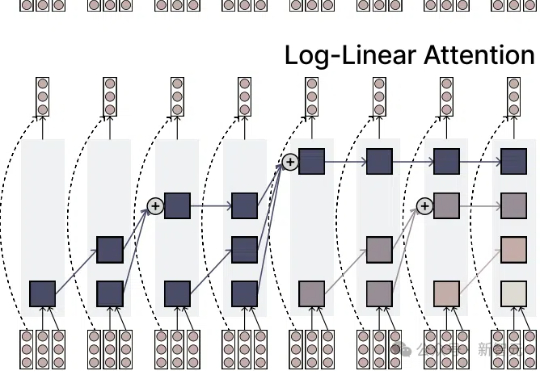
注意力机制的「平方枷锁」,再次被撬开!一招Fenwick树分段,用掩码矩阵,让注意力焕发对数级效率。更厉害的是,它无缝对接线性注意力家族,Mamba-2、DeltaNet 全员提速,跑分全面开花。长序列处理迈入log时代!
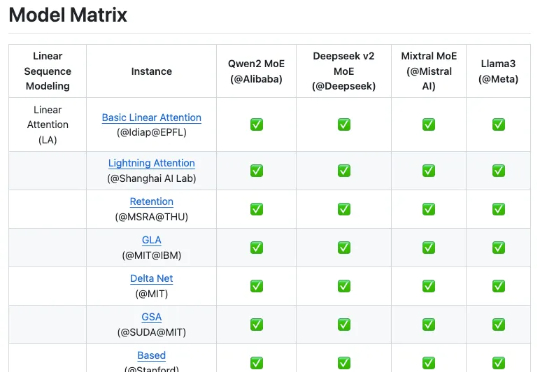
来自上海人工智能实验室团队的最新成果 Linear-MoE,首次系统性地实现了线性序列建模与 MoE 的高效结合,并开源了完整的技术框架,包括 Modeling 和 Training 两大部分,并支持层间混合架构。为下一代基础模型架构的研发提供了有价值的工具和经验。

Transformer架构主导着生成式AI浪潮的当下,但它并非十全十美,也并非没有改写者。