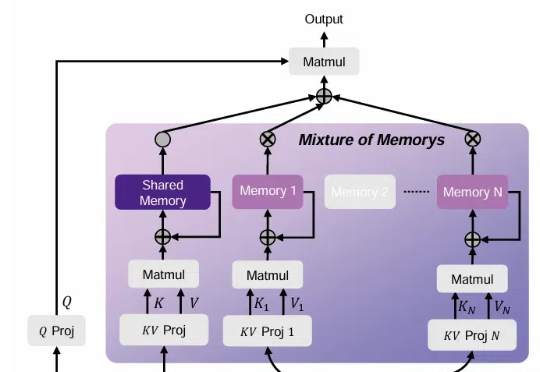
上海AI Lab最新推出Mixture-of-Memories:线性注意力也有稀疏记忆了
上海AI Lab最新推出Mixture-of-Memories:线性注意力也有稀疏记忆了回顾 AGI 的爆发,从最初的 pre-training (model/data) scaling,到 post-training (SFT/RLHF) scaling,再到 reasoning (RL) scaling,找到正确的 scaling 维度始终是问题的本质。
来自主题: AI技术研报
7179 点击 2025-03-06 09:46