从Vibe Coding到Wish Coding,AI编程迎来C端拐点
从Vibe Coding到Wish Coding,AI编程迎来C端拐点最近几个月,Vibe Coding(氛围编程)是一大刷屏热词。以 Cursor 和 Claude Code 为代表的一批工具,正在将软件开发效率推向新的高度。
来自主题: AI技术研报
9342 点击 2026-04-20 14:02
 搜索
搜索
最近几个月,Vibe Coding(氛围编程)是一大刷屏热词。以 Cursor 和 Claude Code 为代表的一批工具,正在将软件开发效率推向新的高度。
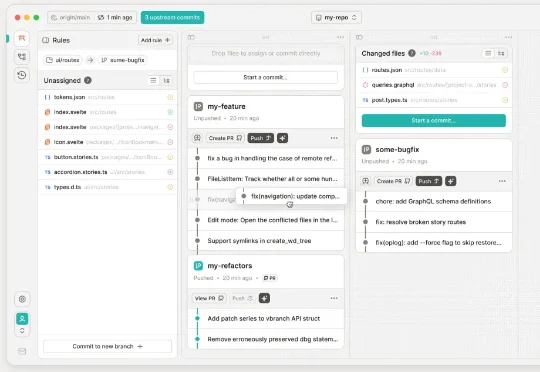
GitButler最近发布的CLI工具引起了我很大的兴趣。这不是一个简单的Git包装器,而是从根本上重新思考了命令行工具应该如何设计。Scott提到了一个有趣的观察:大约80%的开发者仍然使用命令行工具来操作Git,即使有各种GUI工具存在。
过去这半年,AI 圈有个变化特别扎眼:它不再只是能写几行代码,而是开始试图接管整个开发流程,从拆需求、推架构到写代码、修 Bug,一整条链路都在被重塑。过去我们评价一款 AI 编程工具,问的是它能写多少代码?写得够不够好?而现在,大家更关心的是它能不能把事情做完?用起来够不够省心。

刚刚AI编程工具Cursor正在洽谈新一轮融资,金额超过20亿美元,估值直接飙到500亿美元,折合人民币3409亿。黄仁勋都坐不住了。英伟达CEO公开表态要参投这轮融资,还说Cursor是他"最喜爱的企业AI服务"

3B激活参数,视觉能力直逼Claude Sonnet 4.5。

全球最强编程模型,中国造。
字节扣子悄悄升级了,全新上线2.5版本。

年前,我们曾和百度秒哒产品总经理朱广录过一期播客Vibe Coding 下半场:四大天王,和想赢的人|对话朱广翔:百度秒哒产品总经理,听他分享了中国用户们的本土化 Vibe Coding 实践。
Factory 发布桌面端应用,让自治 AI 代理(Droids)直接在你的电脑上操控 VS Code、浏览器、终端和 Excel——官方原话是「像你一样操作你的电脑」。多代理并行、持久化机器、本地模型部署一步到位,官方称企业团队采用速度翻倍、会话量暴涨 4.6 倍。发布推文 21 万人围观,近 900 人点赞。

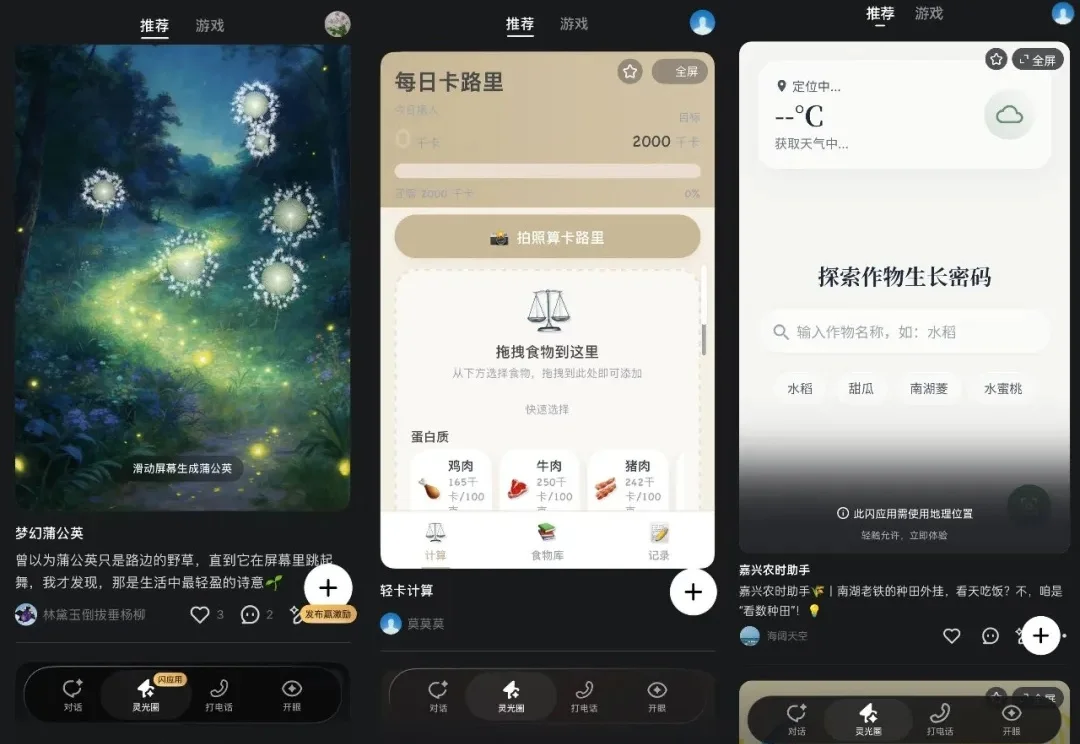
MBTI已经过时了!今天,全网被新型SBTI人格测试刷屏,服务器瞬间被挤崩。更狠的是,不到48小时,就有开发者用Claude Code完成了完整逆向复刻。它由B站UP主「蛆肉儿串儿」一人打造,没想到,却被网友们疯狂测试直接挤爆了服务器。