极佳视界通用世界模型成WAIC焦点:从生成到行动,这才是物理AGI的最佳打开方式
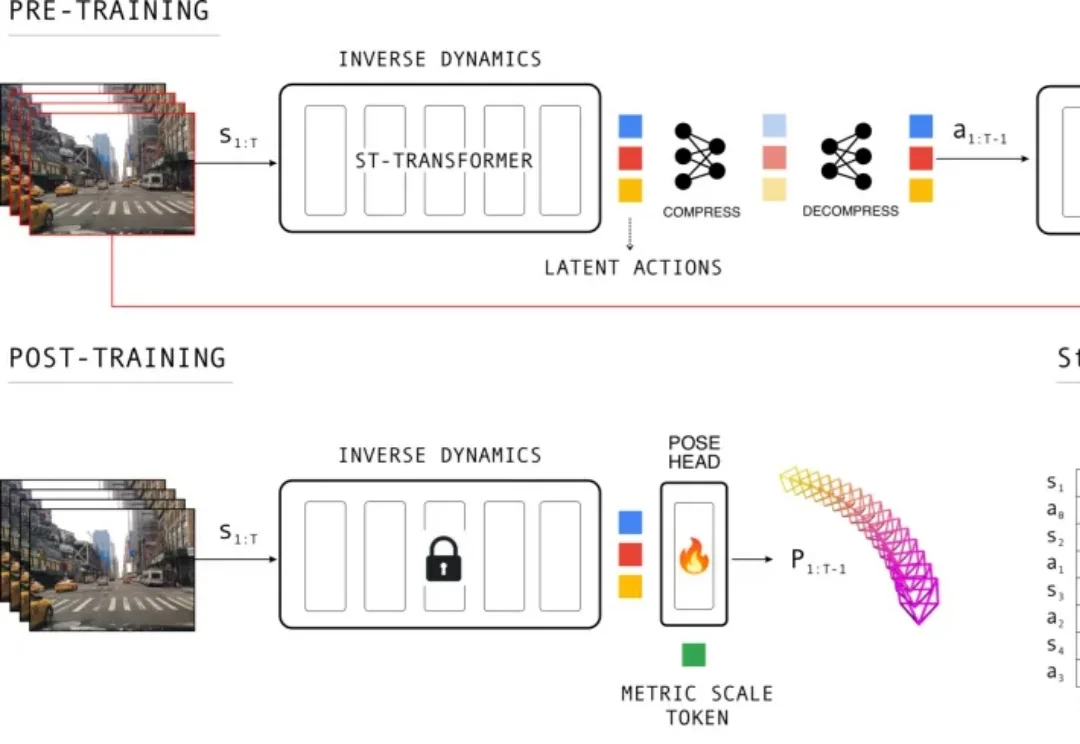
极佳视界通用世界模型成WAIC焦点:从生成到行动,这才是物理AGI的最佳打开方式极佳视界把一套完整的「通用世界模型」产品矩阵摆到了现场:从面向内容创作的一粟 YiSu,到面向自动驾驶数据与仿真的 DriveDreamer;从面向具身智能的 GigaWorld,到负责把世界理解转化为行动的 GigaBrain 与 GigaWorld-Policy;再到进入家庭场景的拾光 S1,以及面向智能制造的 Maker H01。
来自主题: AI资讯
8595 点击 2026-07-19 10:12