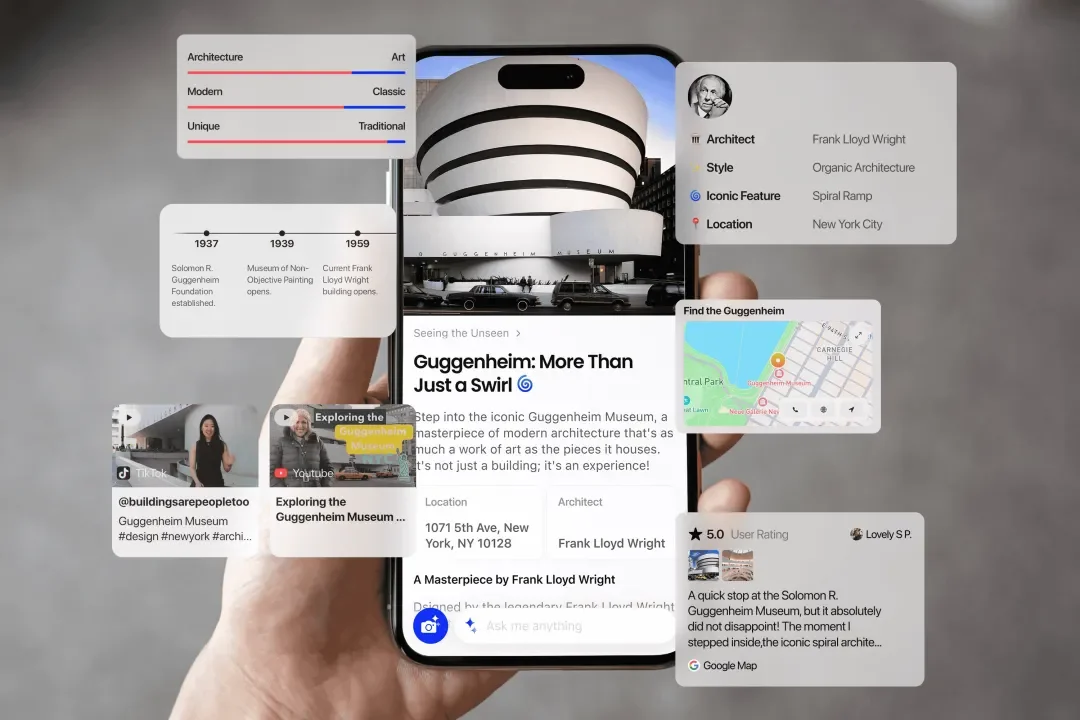
拍照即交互、专为Z世代打造,Chance AI做了世界首款视觉Agent产品
拍照即交互、专为Z世代打造,Chance AI做了世界首款视觉Agent产品一款 AI 产品出现在了国际顶级的艺术展览中,而且是充当解说员的身份。Chance AI 作为这届博览会官方引入的首个 AI 产品,负责帮观众解读艺术品。观众举起手机,对准一幅画,拍照即交互,听 AI 解释:这件作品为什么成立,它背后意味着什么。
来自主题: AI资讯
10016 点击 2026-04-05 14:27
 搜索
搜索
一款 AI 产品出现在了国际顶级的艺术展览中,而且是充当解说员的身份。Chance AI 作为这届博览会官方引入的首个 AI 产品,负责帮观众解读艺术品。观众举起手机,对准一幅画,拍照即交互,听 AI 解释:这件作品为什么成立,它背后意味着什么。

今天,智谱正式发布 GLM-5V-Turbo。 看名字就知道,这次智谱新模型,视觉能力大大加强了!话不多说,这次小编直接开测,边测边为大家说一下对 GLM-5V-Turbo 的使用感受。
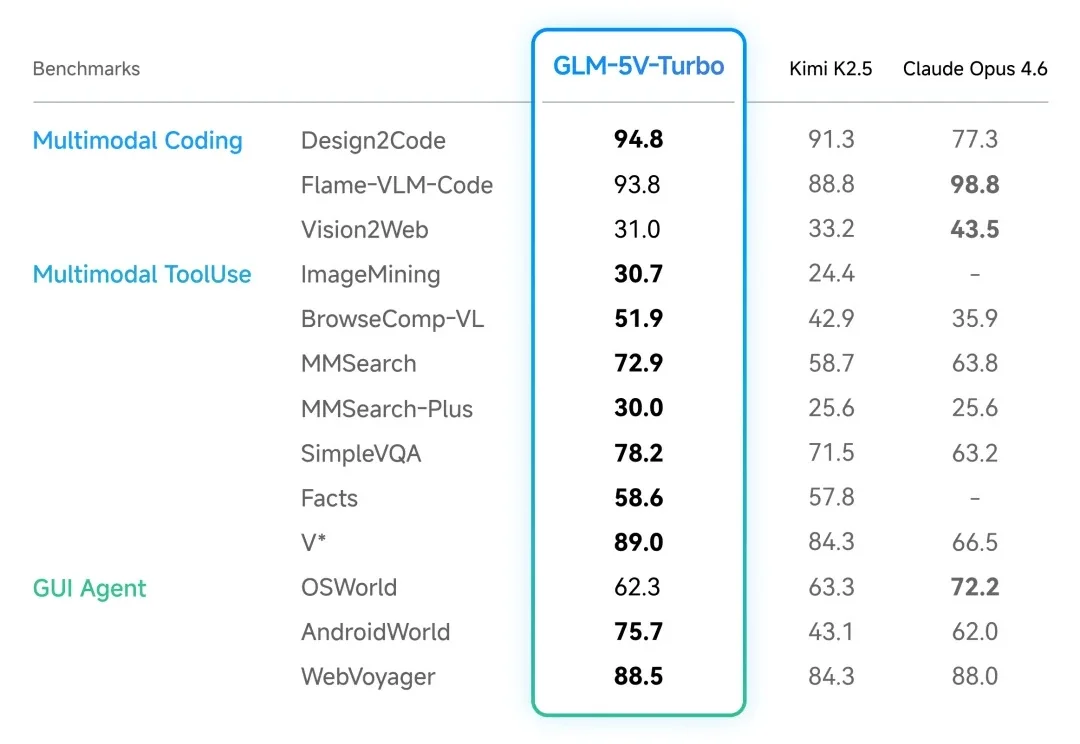
今天,智谱发布 GLM-5V-Turbo,定位「面向视觉编程的多模态 Coding 基座模型」。一句话概括:在 GLM-5-Turbo 的编程和龙虾能力基座上,加入了原生的视觉理解和推理能力
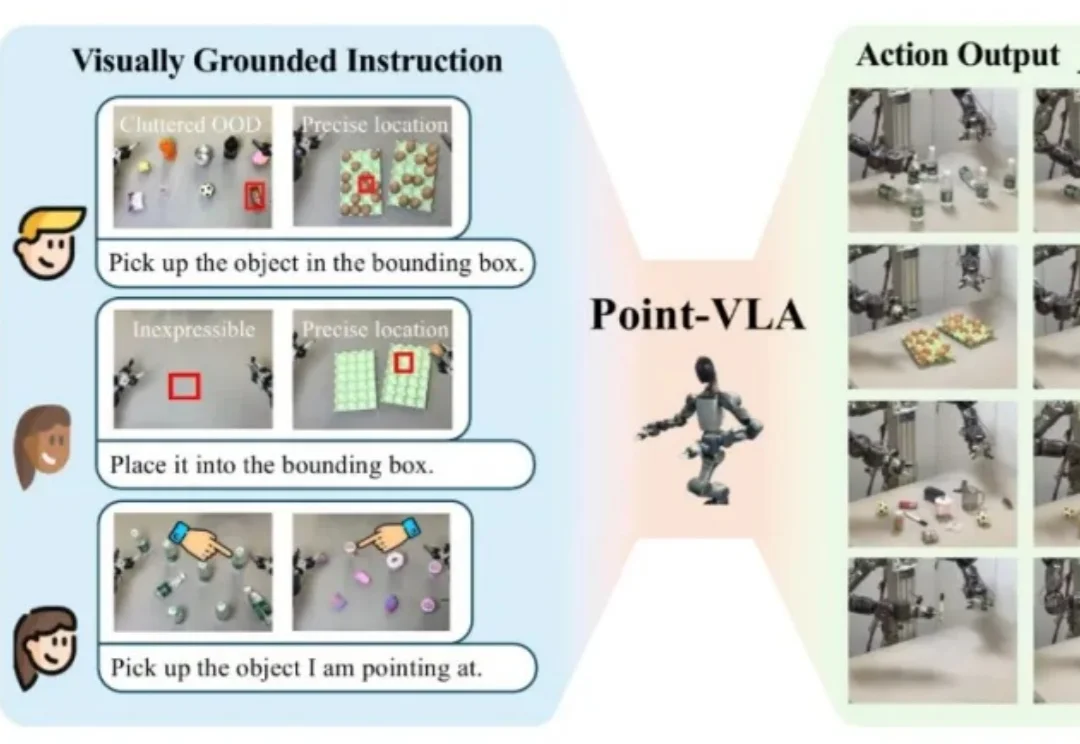
设想这样一个场景:你打电话让同事去办公室某个地方拿东西,仅凭语言描述位置是多么困难。在办公室里,从一堆已经喝过的矿泉水瓶中,让对面同学递过来你之前喝过的那个,只用语言几乎无法准确描述——「左边第二个」?「有点旧的那个」?这时候,人们更倾向于用手指一下,或者拿出图片来指代。
在生成式 AI 领域,视觉分词器(Visual Tokenizer)通常采用固定压缩率 —— 无论是单调的监控画面,还是复杂的动作大片,都被切分为等量的 Token。这种 "一刀切" 的做法不仅会造成巨大的计算冗余,也产生了 “信息量” 不同的 Token,不利于下游理解生成任务处理。
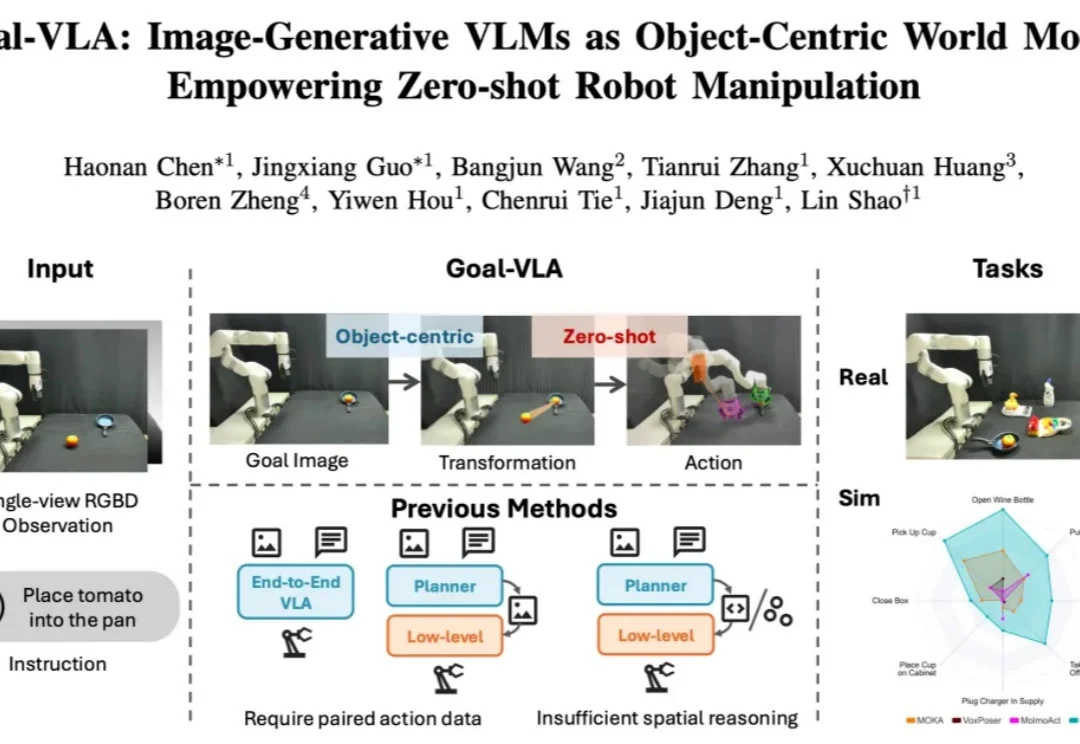
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。
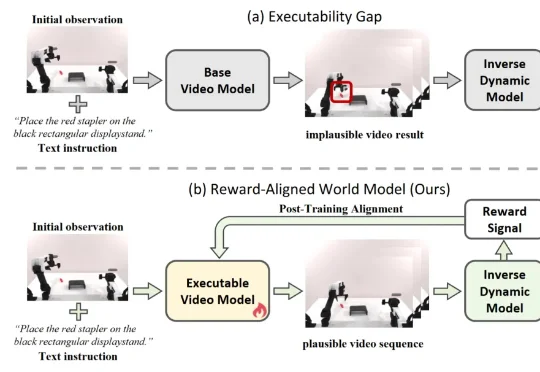
近期,利用视频生成模型为机器人构建 “世界模型”,已成为具身智能领域的热门技术路线。给定当前观测和自然语言指令,这类模型能够先 “想象” 出未来的视觉轨迹,再由逆动力学模型(IDM)将生成画面解码为机器人动作,从而形成 “先预测、后执行” 的解耦式规划范式。由于兼具较强的可解释性与开放场景泛化潜力,这一路线正在受到学术界和工业界的广泛关注。
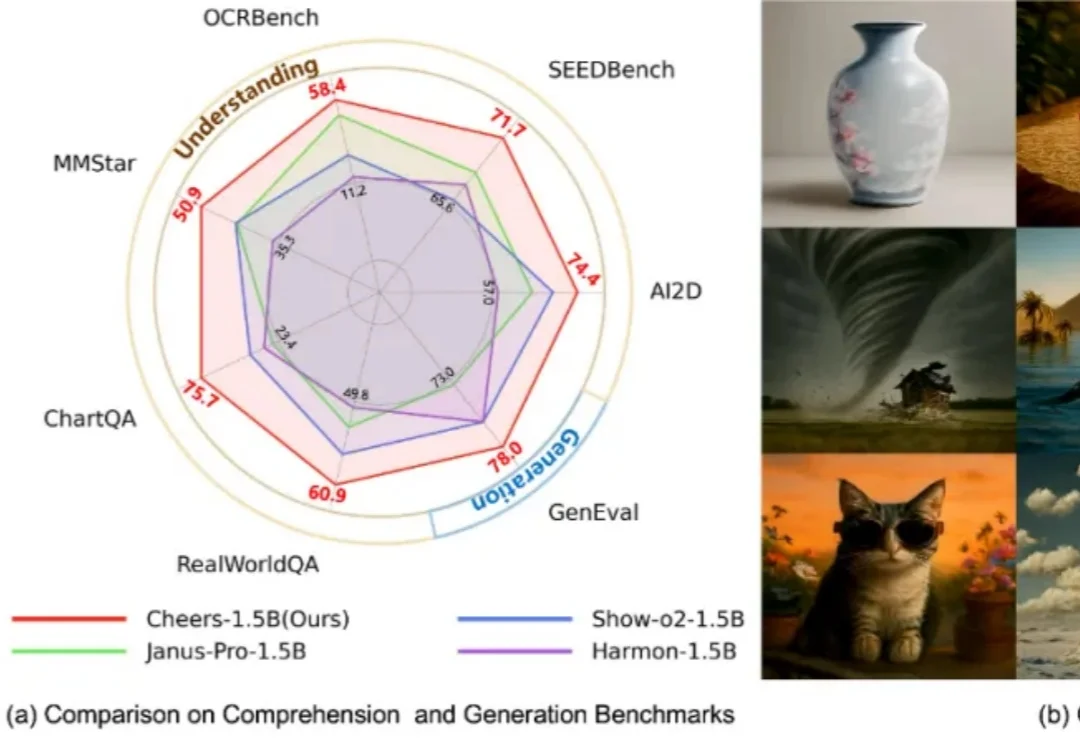
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。

想象一下这样的生活片段:你拿起手机 30 秒,屏幕立刻跳出提醒,“当前心率 78,压力中等,建议深呼吸”;家里的智能摄像头静静看着午睡的宝宝,突然通过 App 提醒你:“宝宝心率偏快,呼吸略显急促,建议进屋查看”;养老院里,巡检机器人通过一次擦身而过的对视,便能感知到老人今天情绪低落,且血氧饱和度略低于往常......
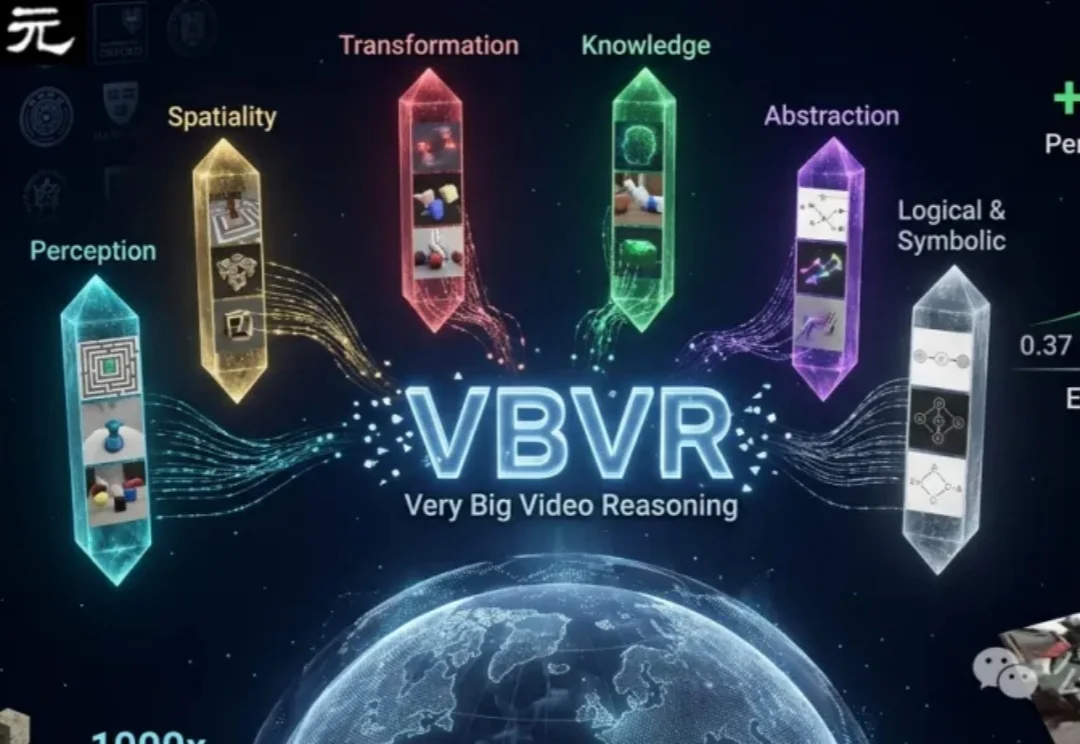
AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,暴露其缺乏真实认知,推动视频AI从「视觉模仿」迈向「智能推理」。