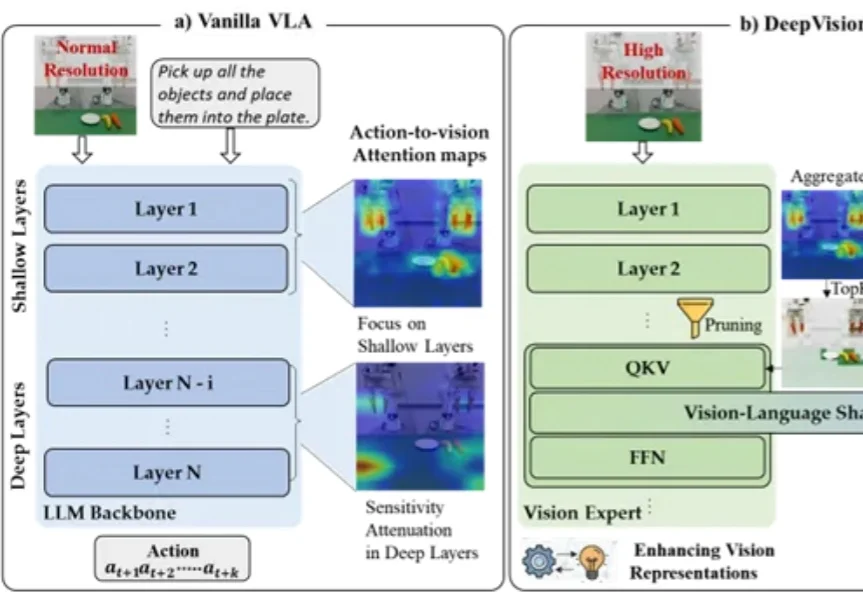
VLA别再「走神」:即插即用提升视觉泛化,相对Pi0.5提升18%
VLA别再「走神」:即插即用提升视觉泛化,相对Pi0.5提升18%“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。
来自主题: AI技术研报
6486 点击 2026-03-26 10:48
 搜索
搜索
“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。

据接近腾讯混元团队的知情人士透露,原字节Seed视觉AI平台团队负责人肖学锋,Infra团队张弛于近期低调入职腾讯,负责大模型Infra相关工作,向腾讯首席AI科学家姚顺雨汇报。
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?

近年来,随着 Sora、Seedance 等文本到视频(T2V)扩散模型的飞速发展,AI 视频生成在视觉保真度与动态表现上已取得突破性进展。特别是近期备受瞩目的 Seedance 2.0,展现出了极其强大的多镜头叙事与复杂分镜控制能力。
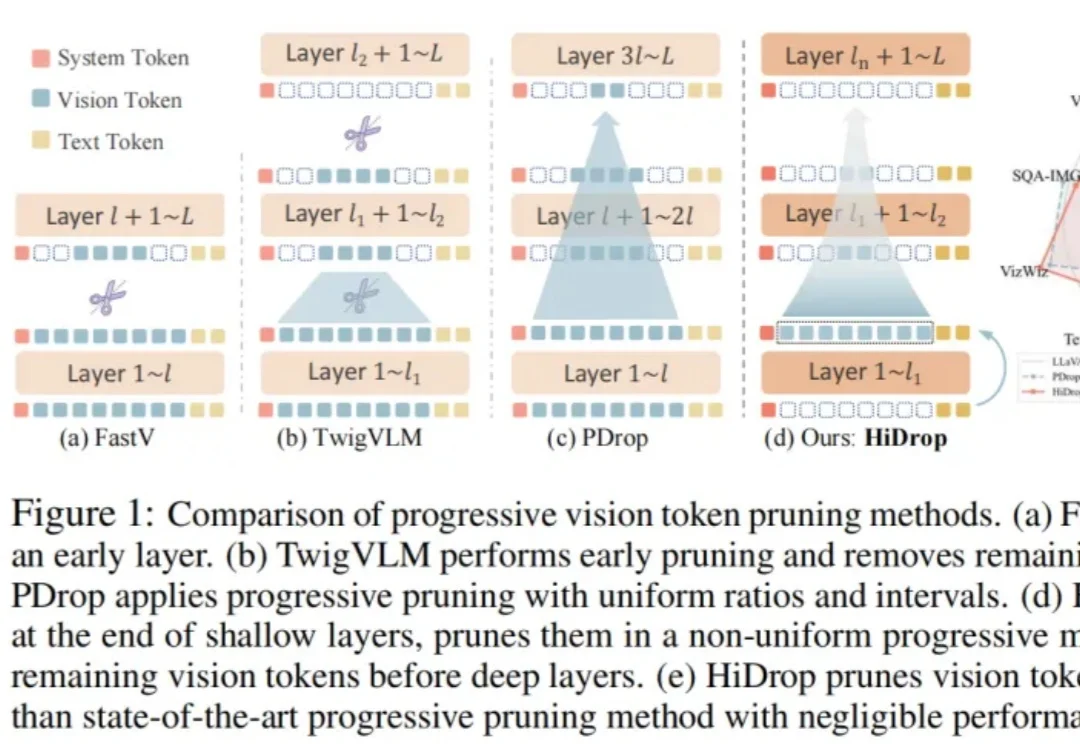
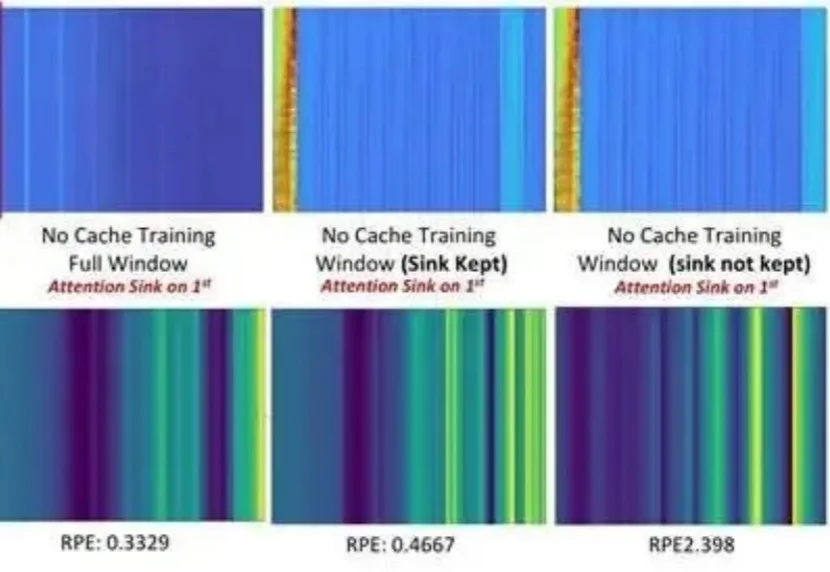
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。

“对具身智能来说,力觉比视觉更重要。”

在 AIGC 领域,基于参考图像的图像修复(Reference-based Inpainting)一直是一项备受关注的核心任务,它旨在利用参考图像引导修复过程,生成视觉一致的内容。这一技术在广告营销和电商领域有着巨大的应用潜力,例如让 AI 自动生成 “真人手持或穿戴商品” 的展示图。

一位复旦教授,造出14万AI工人,最近冲刺IPO。2000年,思谋科技创始人贾佳亚从复旦毕业时,计算机视觉还是个冷门方向。他没想到,二十多年后,自己会给中国工厂造出14万个“AI工人”。
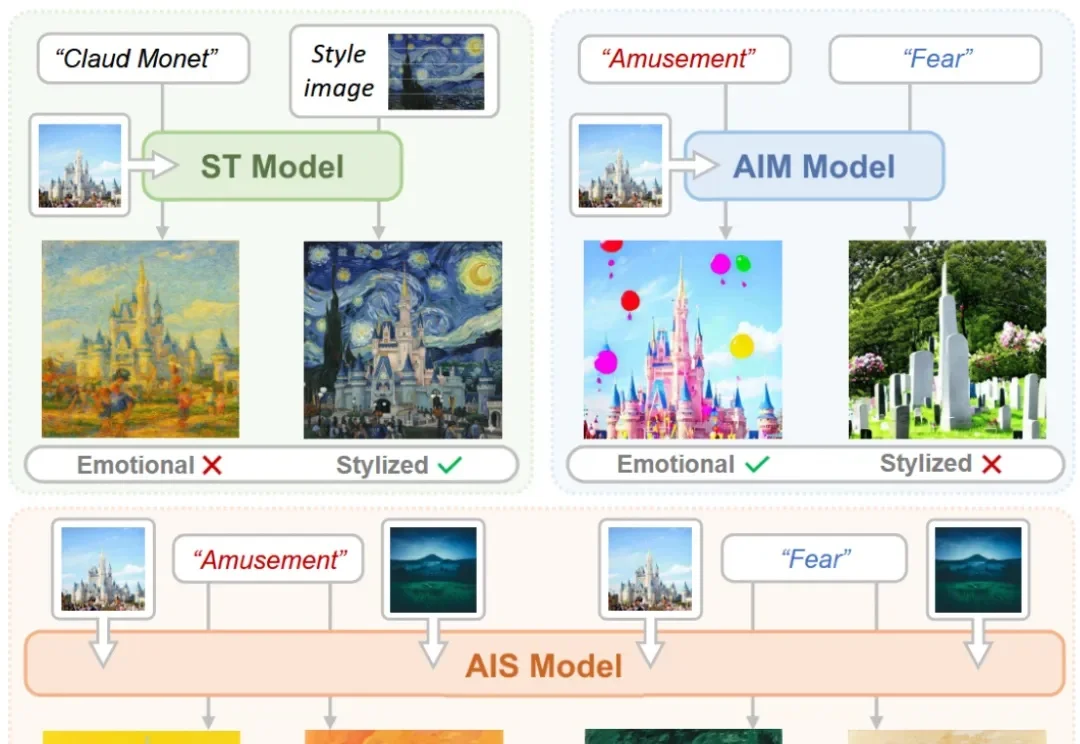
EmoStyle 由深圳大学可视计算研究中心黄惠教授课题组独立完成,第一作者为杨景媛助理教授,第二作者为研二硕士生柏梓桓。深圳大学可视计算研究中心(VCC)以计算机图形学、计算机视觉、人机交互、机器学习、具身智能、可视化和可视分析为学科基础,致力前沿探索与跨学科创新。
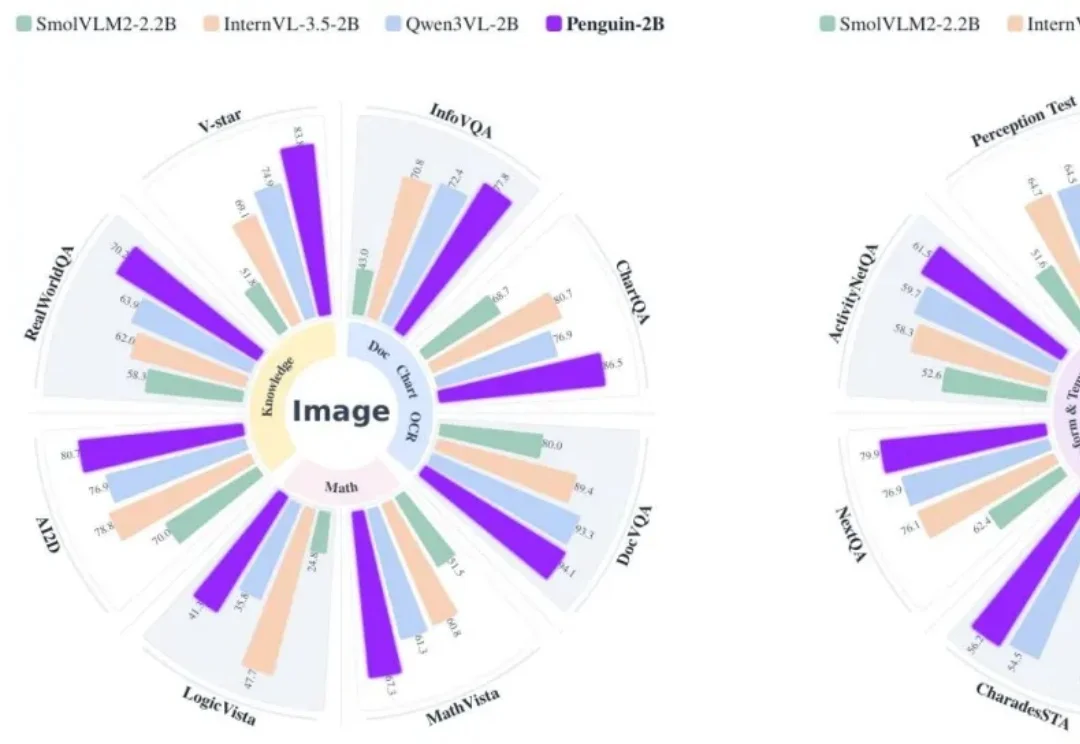
打破多模态视觉+语言拼接套路!