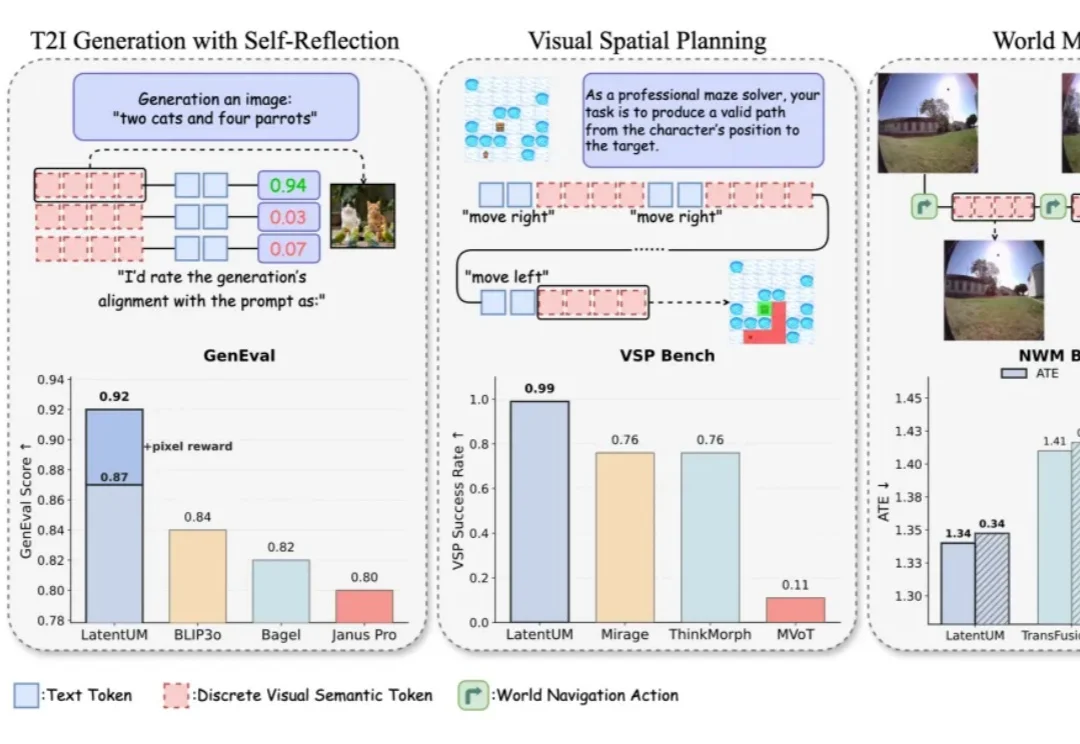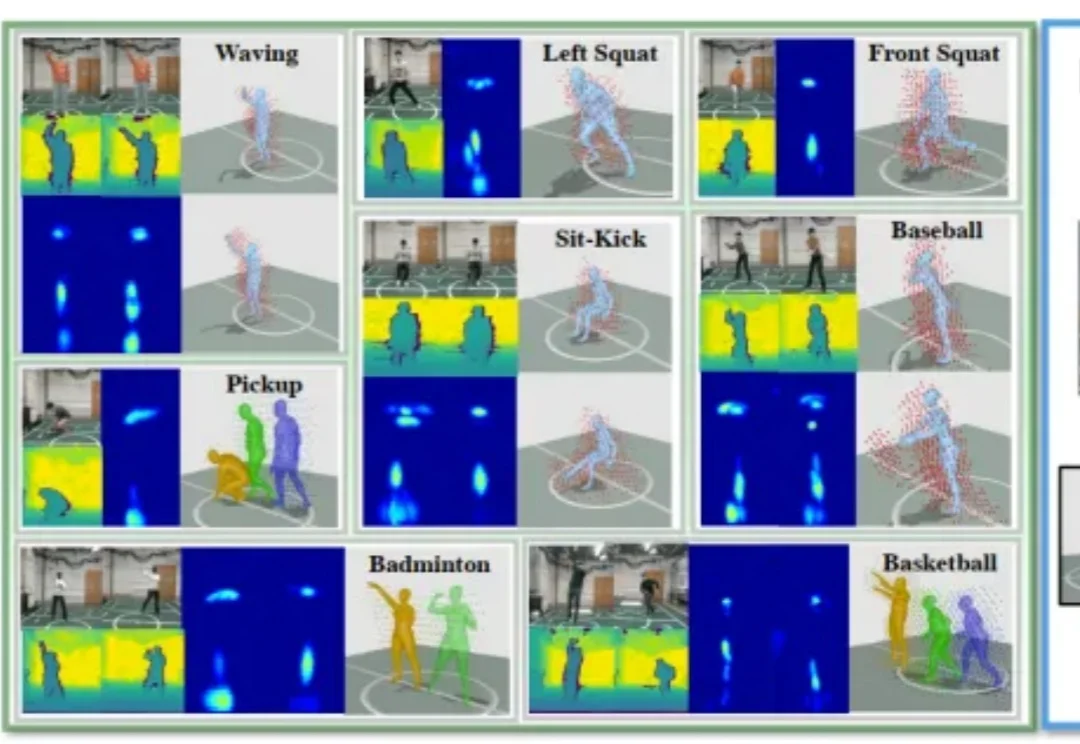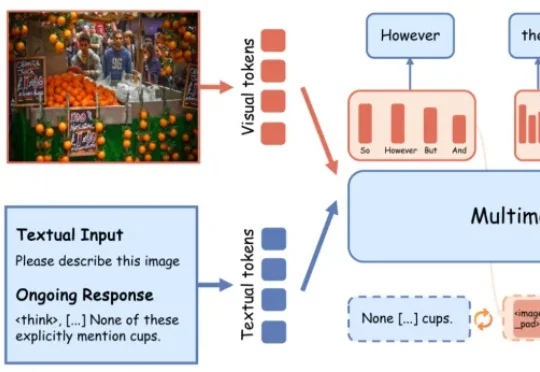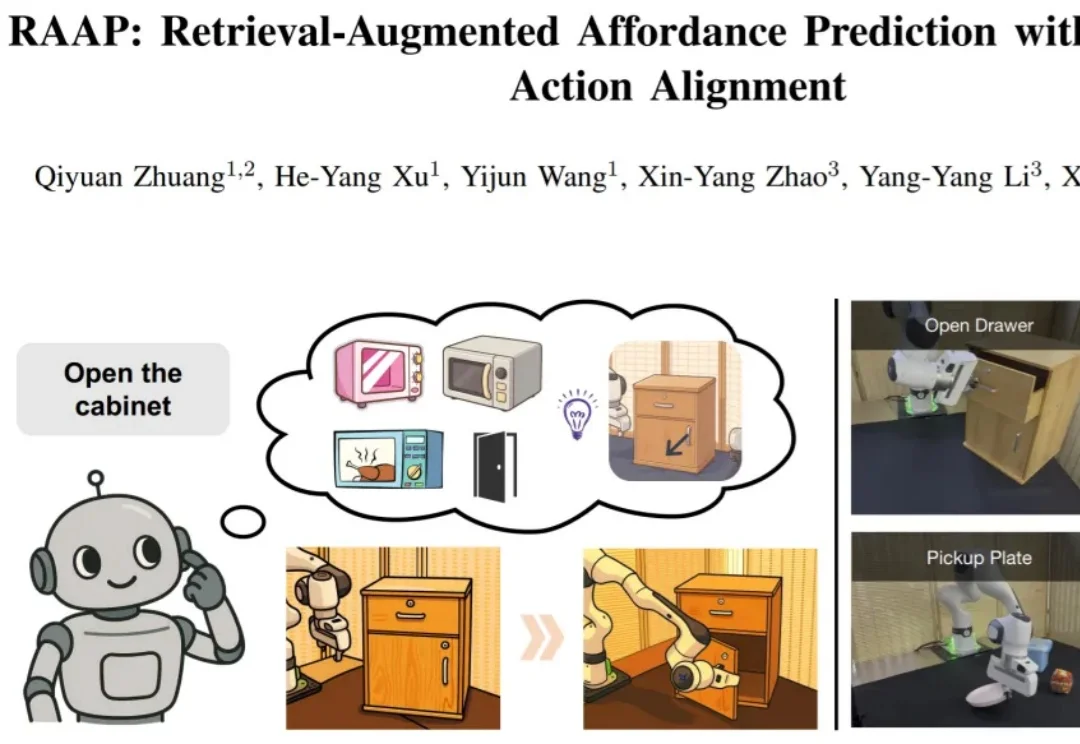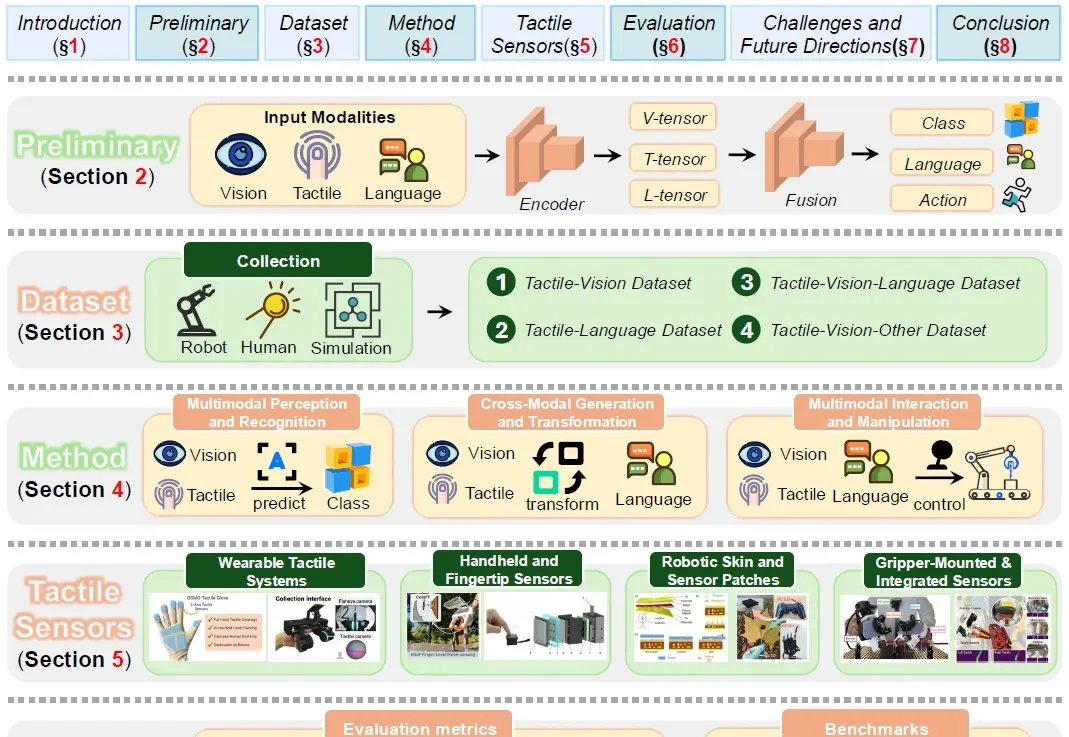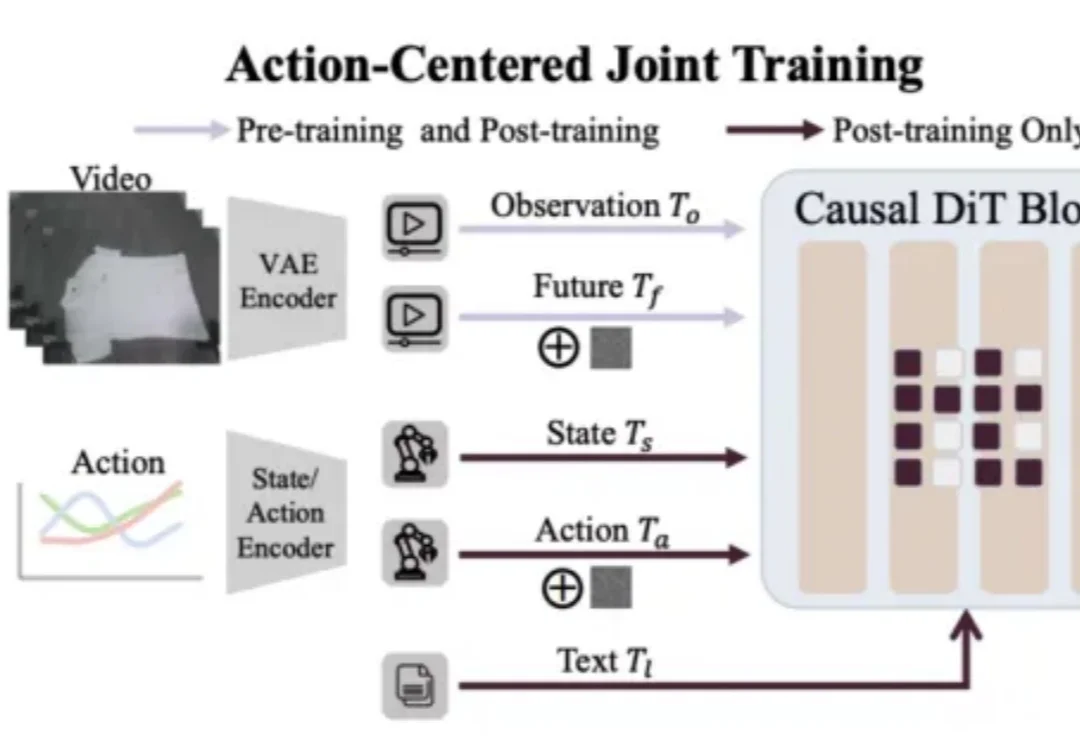
目标更重要?国内公司超越Generalist,进化到动作中心世界模型
目标更重要?国内公司超越Generalist,进化到动作中心世界模型最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。
来自主题: AI技术研报
10744 点击 2026-04-15 09:45