
LaPha:你的Agent轨迹其实嵌入在一个Poincaré球?
LaPha:你的Agent轨迹其实嵌入在一个Poincaré球?在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。
来自主题: AI技术研报
6453 点击 2026-03-18 14:54
 搜索
搜索
在经典强化学习问题中,动作空间通常是离散且有限的。例如在围棋中,一步棋就是一次行动;在机器人控制或视觉 - 语言 - 行动(VLA)模型中,动作往往来自一个有限的控制指令集合。

今天的大型视觉语言模型(VLM)做离线视频分析很强,但一到实时场景就尴尬: 视频在往前走,模型还在“补作业”。
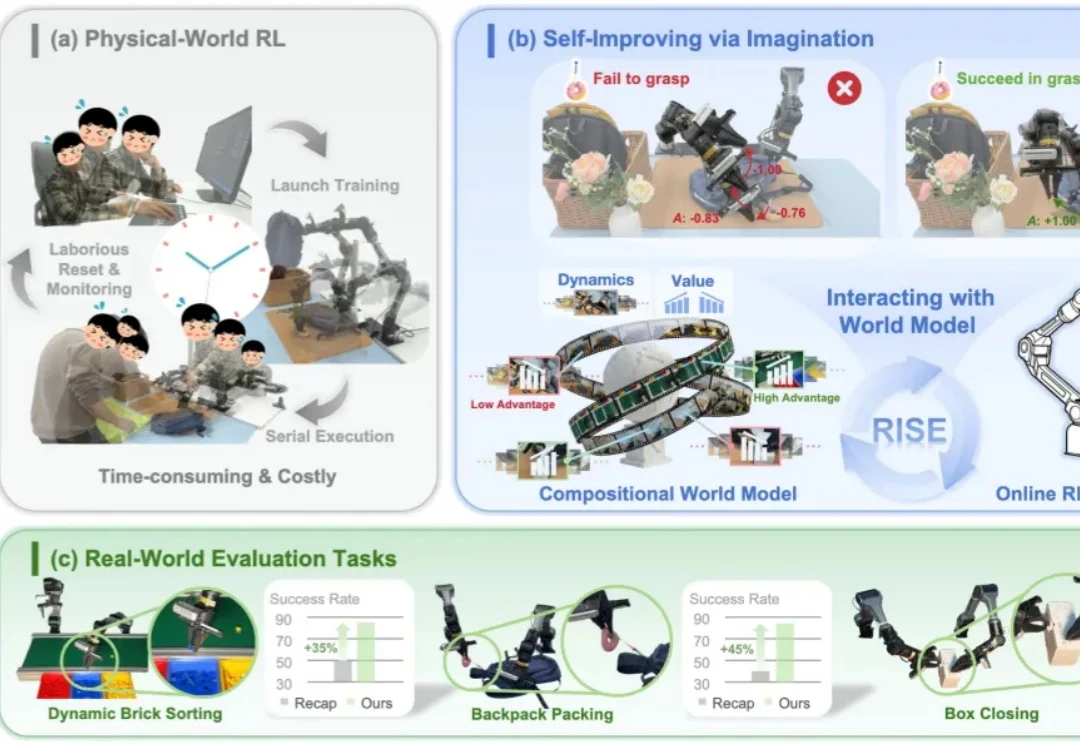
在具身智能的发展路径中,视觉 - 语言 - 动作(VLA)模型正逐步成为通用操作任务的核心框架。但当任务进入长程规划、柔性物体操作、精细双臂协同、动态交互等复杂场景时,VLA 仍然面临两个根本性挑战:
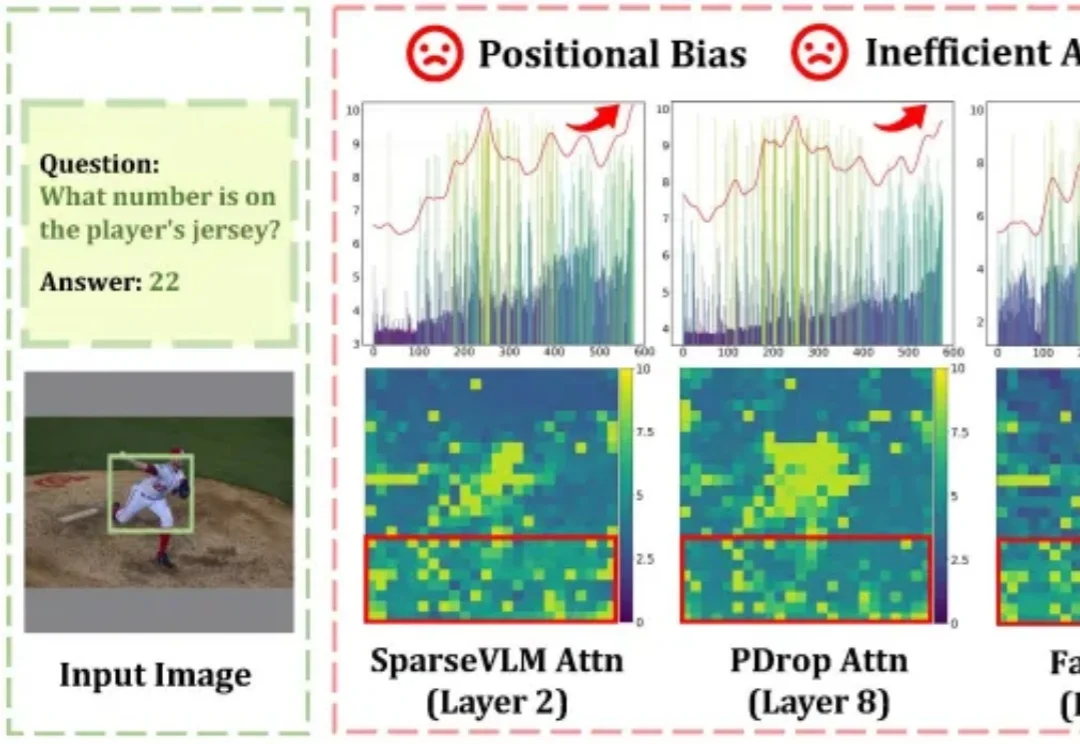
随着高分辨率图像理解与长视频处理需求的爆发式增长,大型视觉语言模型(LVLMs)所需处理的视觉 Token 数量急剧膨胀,推理效率成为落地部署的核心瓶颈。Token 压缩是缩短序列、提升吞吐的直接手段,但现有方法普遍依赖注意力权重来判断 Token 重要性,这一路线暗藏两个致命缺陷:
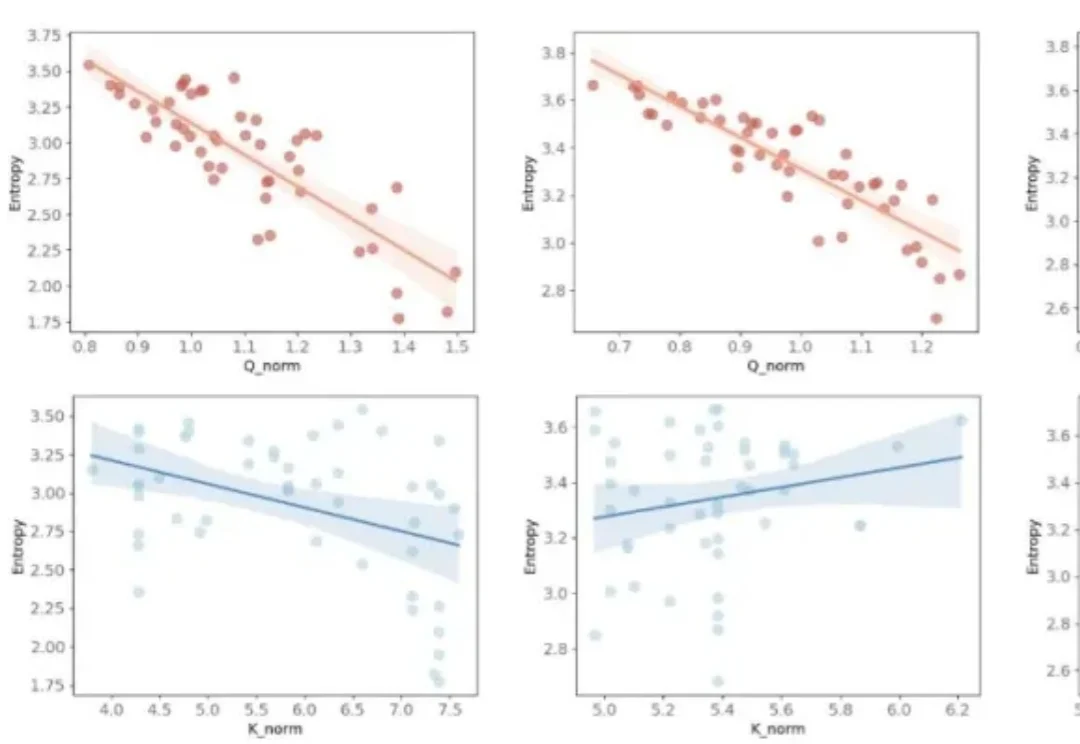
当 Transformer 席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显:标准 Softmax 注意力的二次复杂度,让 70K+token 的超分辨率任务直接显存爆炸,高分辨率图像分割、检测的推理延迟居高不下。

多模态模型代码写得像老司机,却在数手指、量柱子时频频翻车?UniPat AI用五百行代码打造的SWE-Vision,让模型「掏出Python尺子」自我验证,一举拿下五大视觉相关基准SOTA。
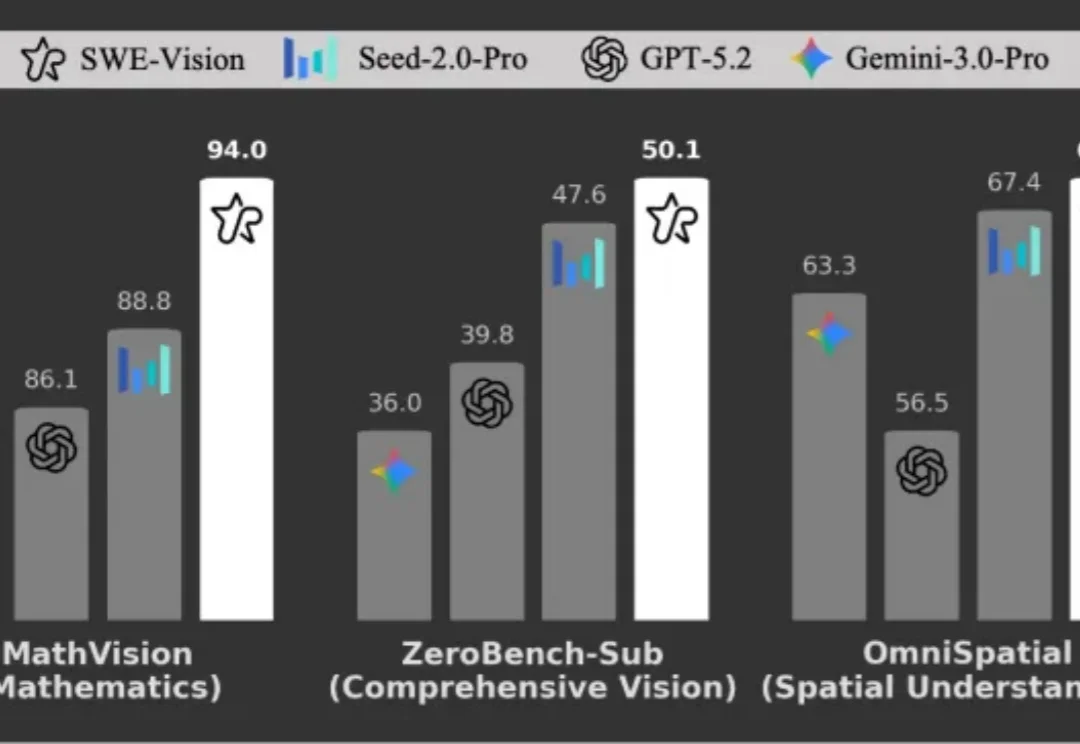
多模态大模型在代码能力上进步惊人,但在基础视觉任务上却频繁失误。UniPat AI 构建了一个极简的视觉智能体框架 ——SWE-Vision,让模型可以编写并执行 Python 代码来处理和验证自己的视觉判断。在五个主流视觉基准测试中,SWE-Vision 均达到了当前最优水平。

在生成式 AI 浪潮中,文生图技术已实现跨越式发展,在视觉呈现上达到了前所未有的高度。然而,在生成图像中准确合成拼写正确、结构规范且风格协调的文字 —— 视觉文本渲染(Visual Text Rendering, VTR),至今仍是该领域尚未攻克的核心难题。
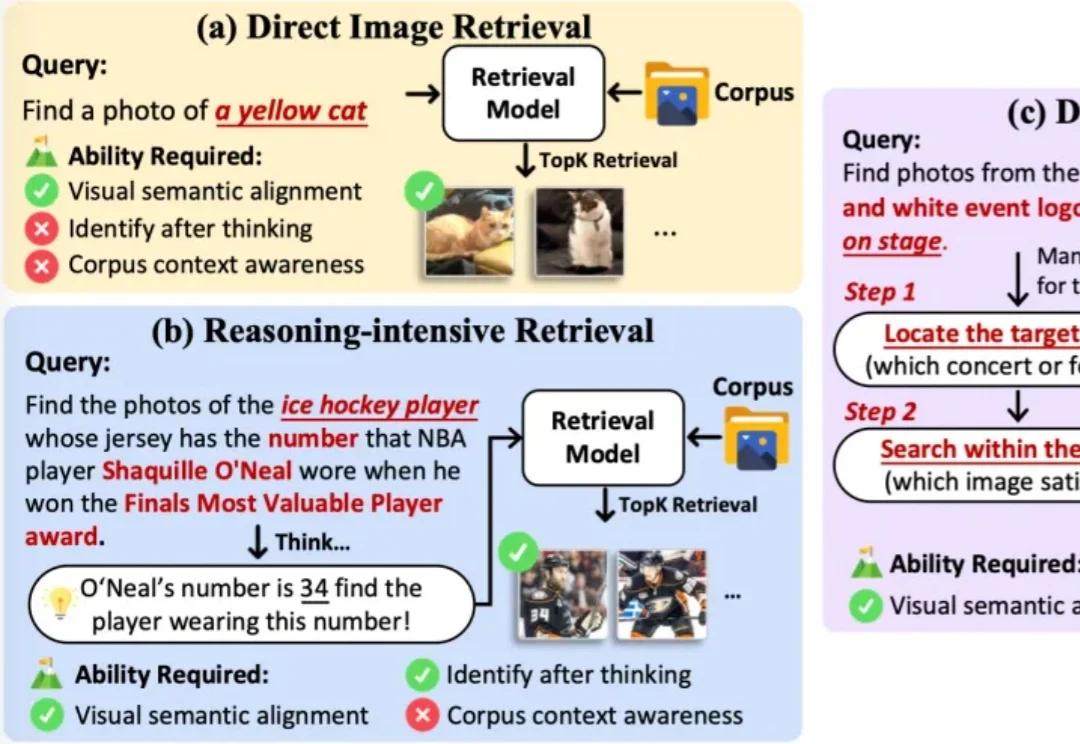
“时光流转,谁还用日记本。往事有底片为证。”—— 许嵩《摄影艺术》
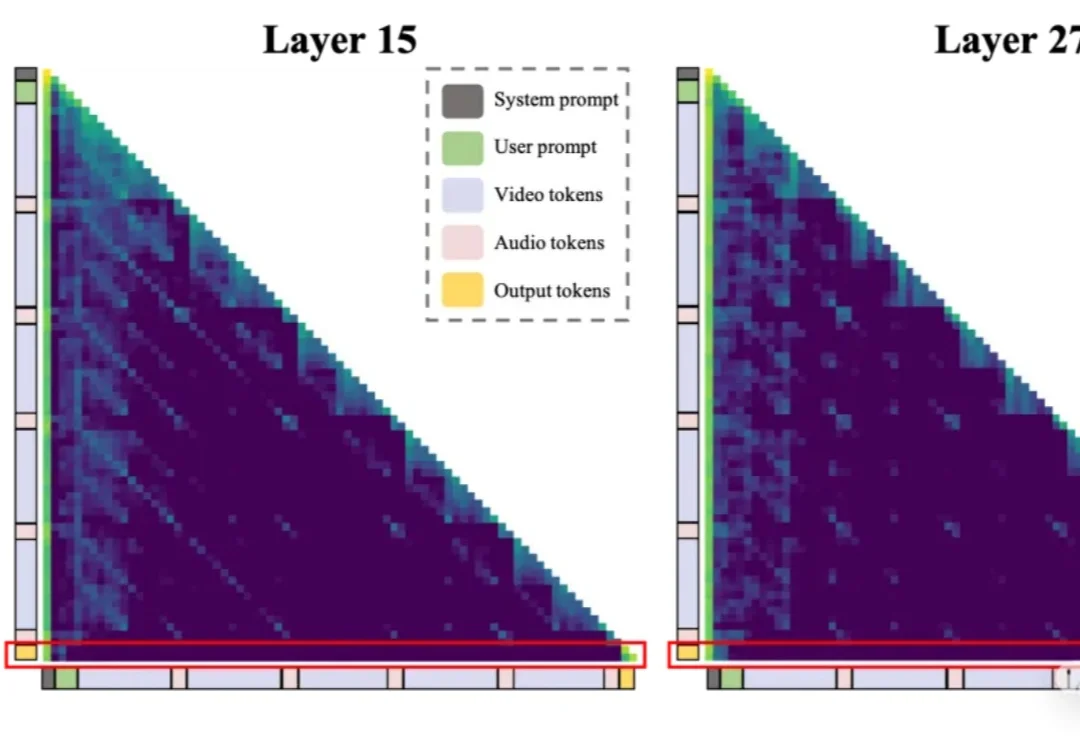
一段几十秒的音视频,上万Token,一半以上是冗余——Omni-LLM的计算浪费,比想象中更严重。