
图灵奖得主Bengio斩获AAAI 2026大奖!5篇杰出论文,华人占3篇
图灵奖得主Bengio斩获AAAI 2026大奖!5篇杰出论文,华人占3篇AAAI 2026「七龙珠」,华人团队强势霸榜!从视觉重建到因果发现,再到知识嵌入传承,新一代AI基石正在新加坡闪耀。
来自主题: AI技术研报
10273 点击 2026-01-23 10:15
 搜索
搜索
AAAI 2026「七龙珠」,华人团队强势霸榜!从视觉重建到因果发现,再到知识嵌入传承,新一代AI基石正在新加坡闪耀。
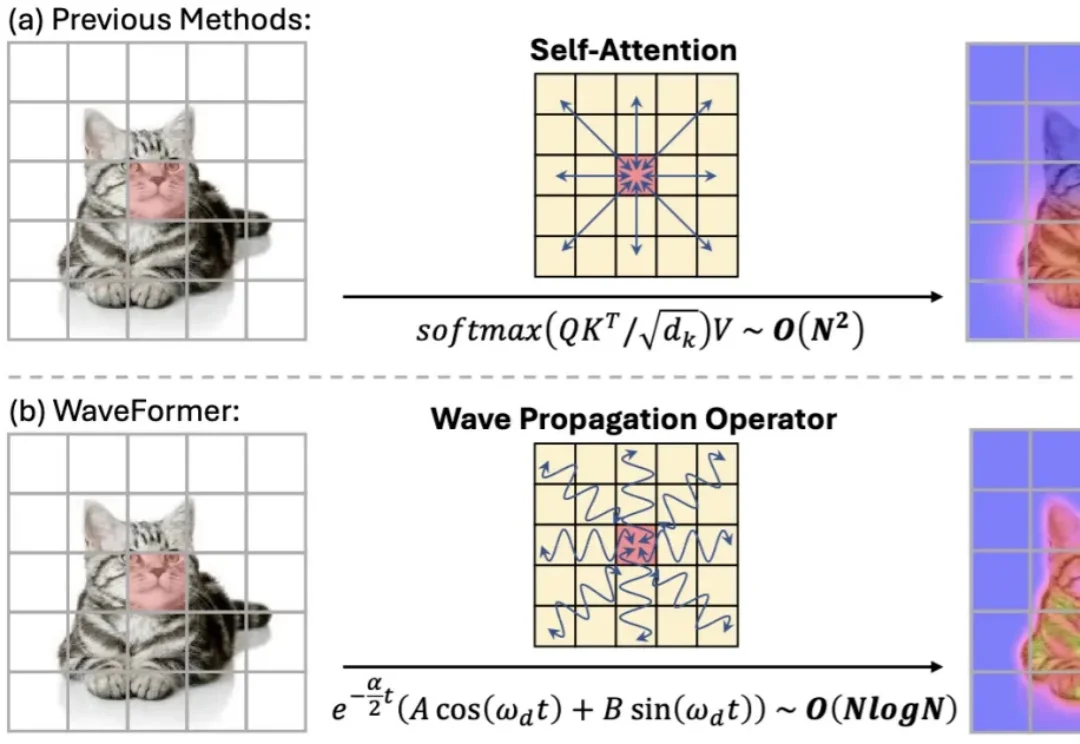
“全局交互” 几乎等同于 self-attention:每个 token 都能和所有 token 对话,效果强,但代价也直观 —— 复杂度随 token 数平方增长,分辨率一高就吃不消。现有方法大多从 “相似度匹配” 出发(attention),或从 “扩散 / 传导” 出发(热方程类方法)。但热方程本质上是一个强低通滤波器:随着传播时间增加,高频细节(边缘、纹理)会迅速消失,导致特征过平滑。
AI视频生成正从“静态输出”迈入“实时交互”阶段,一场内容创作革命即将到来。 近日,中国儒意宣布以1420万美元对爱诗科技进行战略投资,双方将围绕影视、流媒体、游戏等业务展开深度合作。 爱诗科技作为全
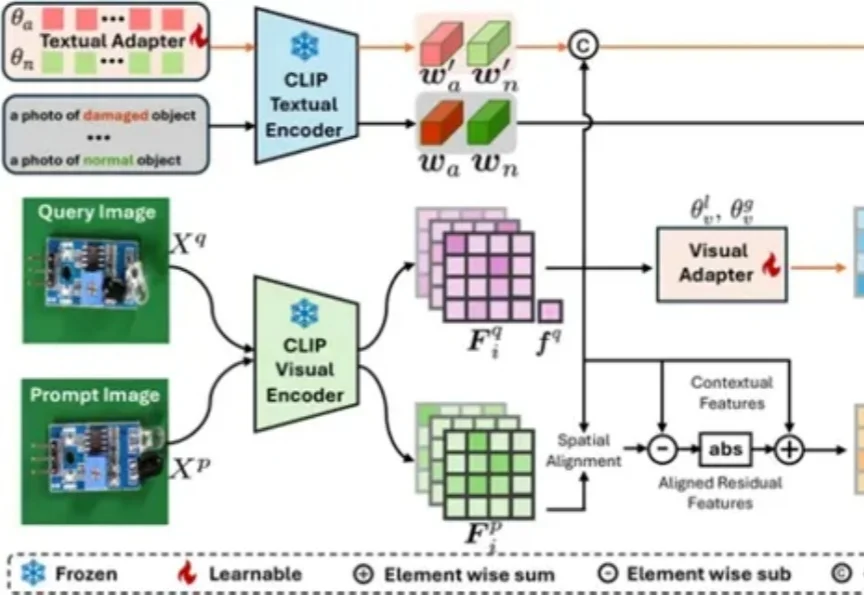
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。
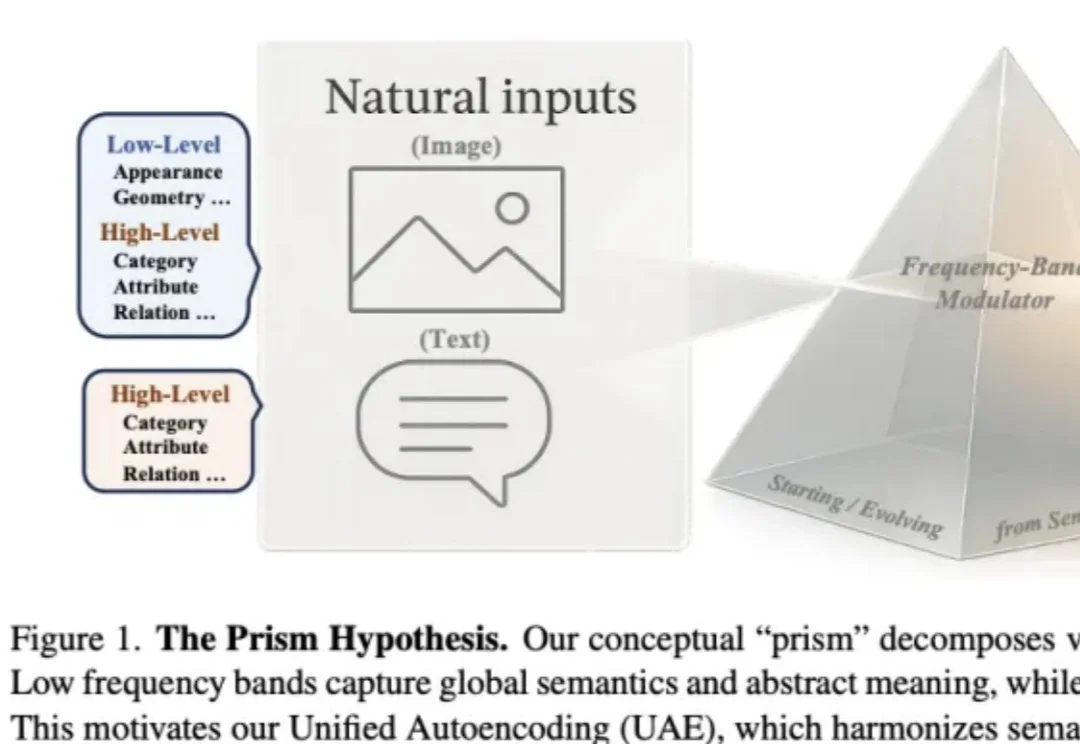
作者来自 Nanyang Technological University(MMLab) 与 SenseTime Research,提出 Prism Hypothesis(棱镜假说) 与 Unified Autoencoding(UAE),尝试用 “频率谱” 的统一视角,把语义编码器与像素编码器的表示冲突真正 “合并解决”。
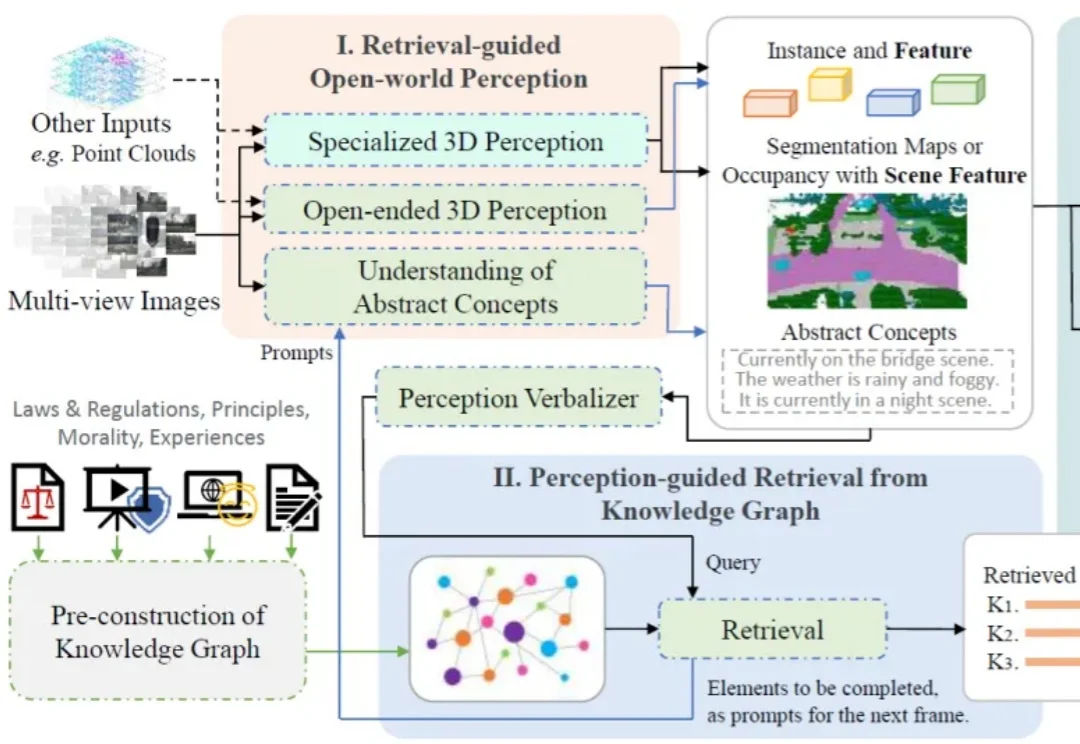
一个智能驾驶系统,在迈向高阶自动驾驶的过程中,应当具备何种能力?除了基础的感知、预测、规划、决策能力,如何对三维空间进行更深入的理解?如何具备包含法律法规、道德原则、防御性驾驶原则等知识?如何进行基本的视觉 - 语言推理?如何让智能系统具备世界观和价值观?
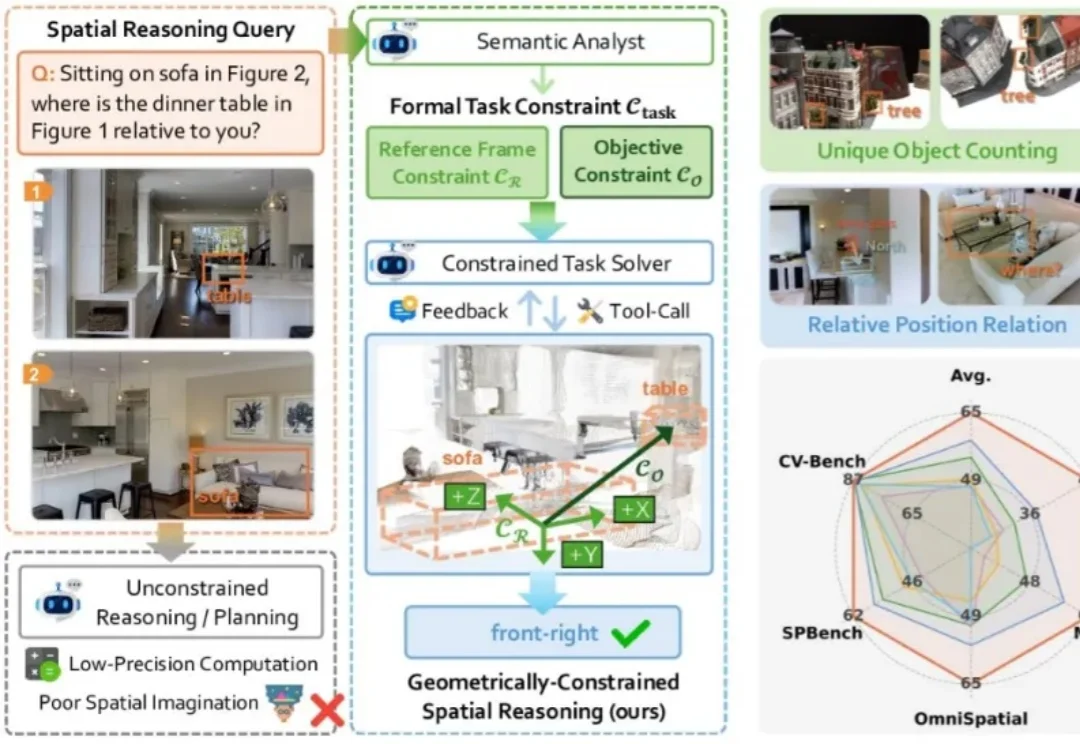
现有的视觉大模型普遍存在「语义-几何鸿沟」(Semantic-to-Geometric Gap),不仅分不清东南西北,更难以处理精确的空间量化任务。例如问「你坐在沙发上时,餐桌在你的哪一侧?」,VLM 常常答错。

谷歌 Gemini 数据联合负责人 Andrew Dai 联手苹果首席研究科学家 Yinfei Yang,隐身创办 AI 新秀 Elorian。首轮将融资 5000 万美元,剑指「视觉推理」这个下一代大模型的核心问题。

大模型能写代码、解奥数,却连幼儿园小班都考不过?简单的连线找垃圾桶、数积木,人类一眼即知,AI却因为无法用语言「描述」视觉信息而集体翻车。大模型到底「懂不懂」,这个评测基准给出答案。
戴明博表示,这家名为 Elorian 的新公司目前正在与投资人洽谈,计划完成一轮约 5000 万美元的种子融资。知情人士透露,由前 CRV 普通合伙人 Max Gazor 于去年 10 月创立的风投机构 Striker Venture Partners 正在洽谈领投该轮融资。