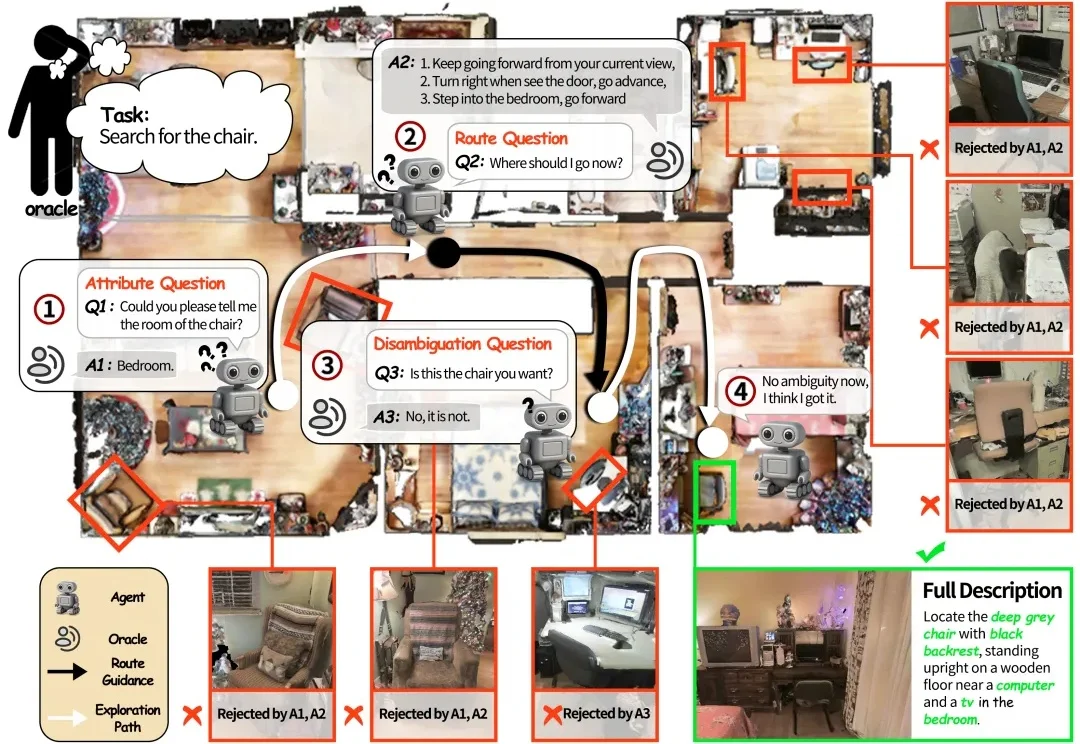
VL-LN Bench:模拟「边走边问找具体目标」的真实导航场景
VL-LN Bench:模拟「边走边问找具体目标」的真实导航场景如果将一台在视觉语言导航(VLN)任务中表现优异的机器人直接搬进家庭场景,往往会遇到不少实际问题。
来自主题: AI技术研报
8321 点击 2026-02-03 08:43
 搜索
搜索
如果将一台在视觉语言导航(VLN)任务中表现优异的机器人直接搬进家庭场景,往往会遇到不少实际问题。
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。
没想到吧,Google DeepMind刚刚为Gemini 3 Flash推出了一个重量级新能力:Agentic Vision(智能体视觉)。(难道是被DeepSeek-OCR2给刺激到了?)

嘿!刚刚,DeepSeek 又更新了!这次是更新了十月份推出的 DeepSeek-OCR 模型。刚刚发布的 DeepSeek-OCR 2 通过引入 DeepEncoder V2 架构,实现了视觉编码从「固定扫描」向「语义推理」的范式转变!

DeepSeek开源DeepSeek-OCR2,引入了全新的DeepEncoder V2视觉编码器。该架构打破了传统模型按固定顺序(从左上到右下)扫描图像的限制,转而模仿人类视觉的「因果流(Causal Flow)」逻辑。

这一框架可用于集成额外文本、语音和视觉等多种模态。

近日,北京大学朱毅鑫教授课题组、北京大学毕彦超教授课题组和山西医科大学第一医院王效春团队通过结合 AI 模型和大脑损伤患者的数据,发现语言其实是一副无形的智能眼镜,时刻在悄悄修饰着我们看到的世界。我们可能以为视觉就是眼睛看到什么就是什么,但是这项成果说明了视觉从来都不是孤立的。事实上,当我们在看图片的时候,其实不只是在看,而是在进行被语言调制过的看。
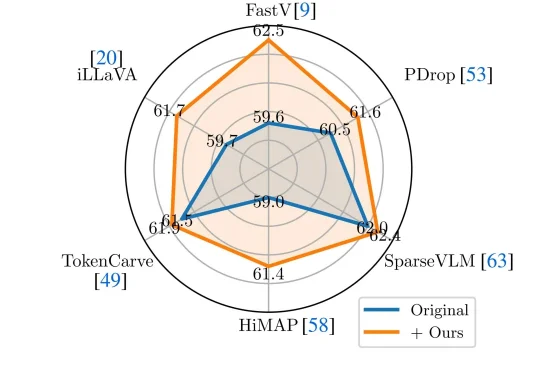
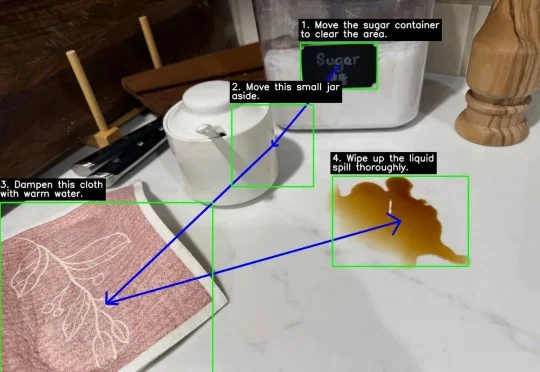
近年来多模态大模型在视觉感知,长视频问答等方面涌现出了强劲的性能,但是这种跨模态融合也带来了巨大的计算成本。高分辨率图像和长视频会产生成千上万个视觉 token ,带来极高的显存占用和延迟,限制了模型的可扩展性和本地部署。
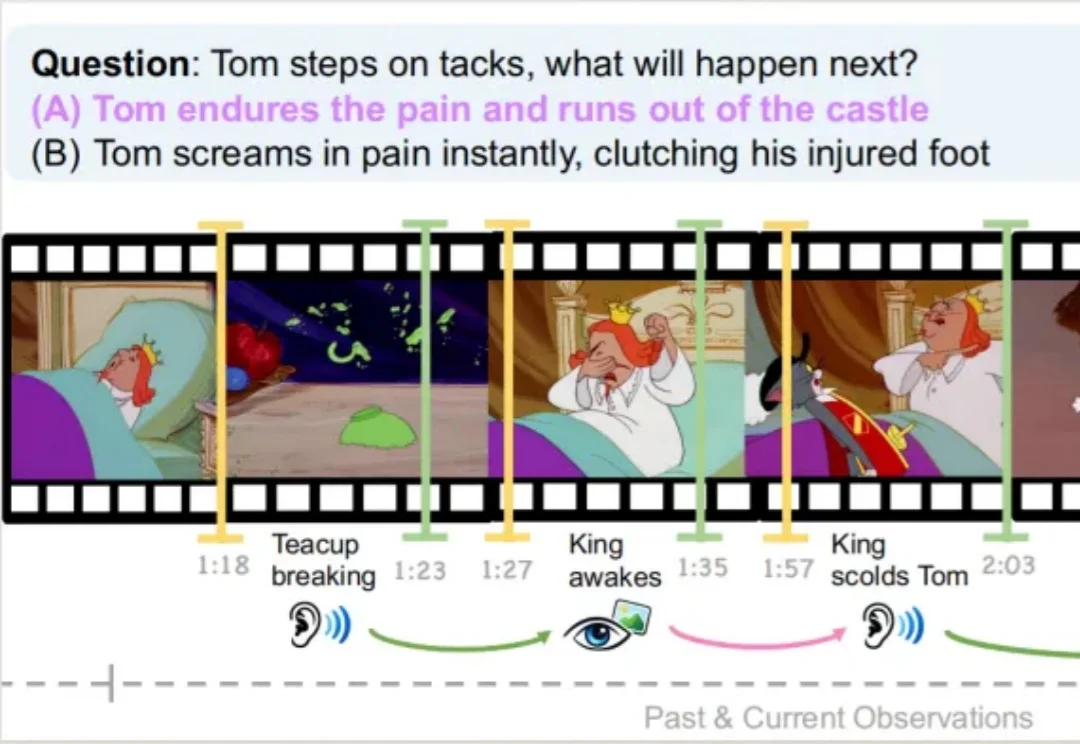
复旦大学、上海创智学院与新加坡国立大学联合推出首个全模态未来预测评测基准 FutureOmni,要求模型从音频 - 视觉线索中预测未来事件,实现跨模态因果和时间推理。

LOOKEE口语侠以无屏陪伴形态,重点切入6-12岁儿童的口语学习场景。无屏化的优势不仅是保护视力,它更通过移除视觉依赖,迫使孩童回归“听”与“说”的语言本质,在纯粹的音频交互中理解问题并给出回应,构建内在的语言逻辑。