
AI视觉创作总差点意思?中科大等综述500+篇文献,系统分析生成一致性
AI视觉创作总差点意思?中科大等综述500+篇文献,系统分析生成一致性扩散模型已经越来越会「画」,却还远没有学会「守住要求」。决定系统是否可靠的,已不再只是画质,而是生成结果能否持续遵守条件、维持状态,并符合人类与现实世界的基本标准。
来自主题: AI技术研报
5644 点击 2026-07-02 11:04
 搜索
搜索
扩散模型已经越来越会「画」,却还远没有学会「守住要求」。决定系统是否可靠的,已不再只是画质,而是生成结果能否持续遵守条件、维持状态,并符合人类与现实世界的基本标准。

AI 视频初创公司 Higgsfield AI 正在与投资者洽谈,筹资 3 亿美元至 5 亿美元,投资前估值为 50 亿美元,据两位知情于此次筹资活动的人士透露。Higgsfield 制作了一个用于 AI 图像和视频生成的平台,允许用户从文本创建视觉内容,并编辑视频的运动控制、音频和其他组件。
最近,清华教授、智谱灵魂人物唐杰聊得有点high。
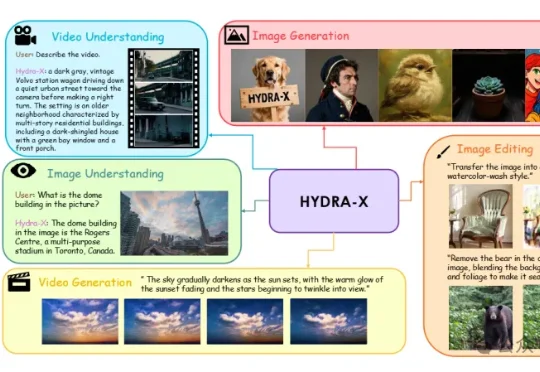
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。

据彭博社记者古尔曼报道,苹果公司负责Vision Pro头显和智能眼镜业务的负责人保罗·米德(Paul Meade)即将离职,转而加入OpenAI。米德在苹果担任视觉产品事业部的硬件工程副总裁。古尔曼称,米德将于下周离开苹果,加入OpenAI的硬件部门,负责OpenAI即将推出的设备系列。
一款没有输入框的AI应用,正在北美高校悄悄走红。

今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6

今天,阿里巴巴发布了其最新一代视频生成模型HappyHorse 1.1(快乐小马1.1)。阿里称,相比HappyHorse 1.1,这代模型在动态表现力、主体一致性、指令遵循、视觉质感和音频能力等维度有了一定提升。
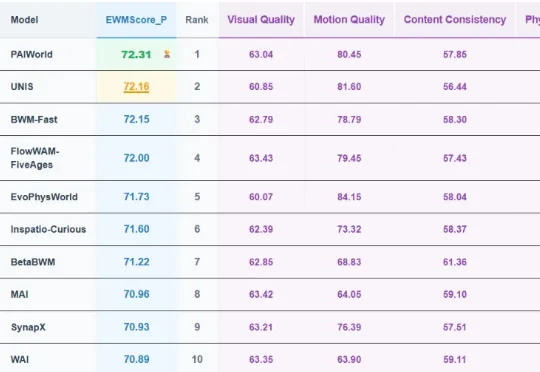
日前,世界模型国际权威榜单 WorldArena 更新排名,中国科学院工业人工智能研究所徐凯研究员带领物理智能团队(The PAI Lab)自研的世界模型 PAIWorld 登顶。WorldArena 作为目前世界模型领域最权威的评测榜单,是针对具身世界模型的全方位评价体系,涵盖视觉质量、运动质量、内容一致性、物理遵循、三维准确性及可控性六大维度