ECCV'26| 看起来会动,还要动得合理:从生成模型中主动寻找物理证据
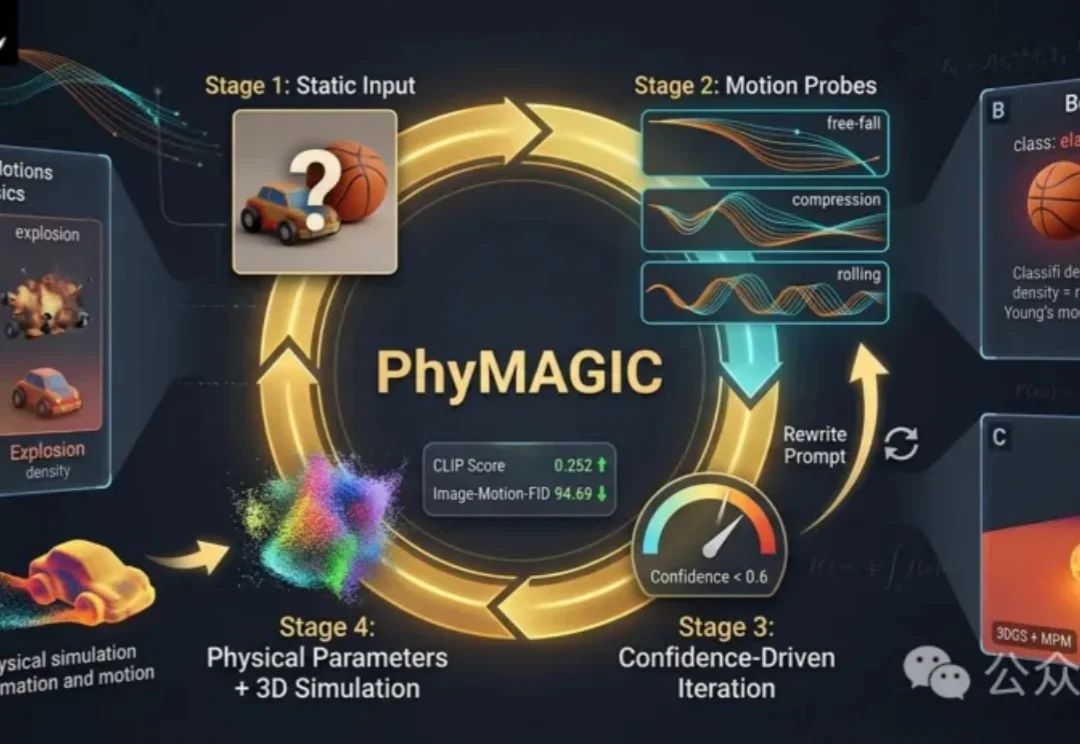
ECCV'26| 看起来会动,还要动得合理:从生成模型中主动寻找物理证据PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。
来自主题: AI技术研报
5109 点击 2026-07-17 10:09
 搜索
搜索
PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。
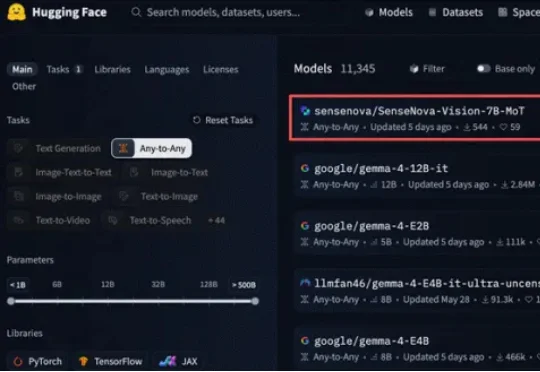
近日,商汤科技发布并全面开源日日新SenseNova-Vision理解生成统一视觉大模型,试图宣告视觉AI“缝合怪”时代的终结。截至当前,该模型综合得分登顶Hugging Face Any-to-Any Leaderboard,位列该全模态任意输入输出开源模型榜单全球第一。
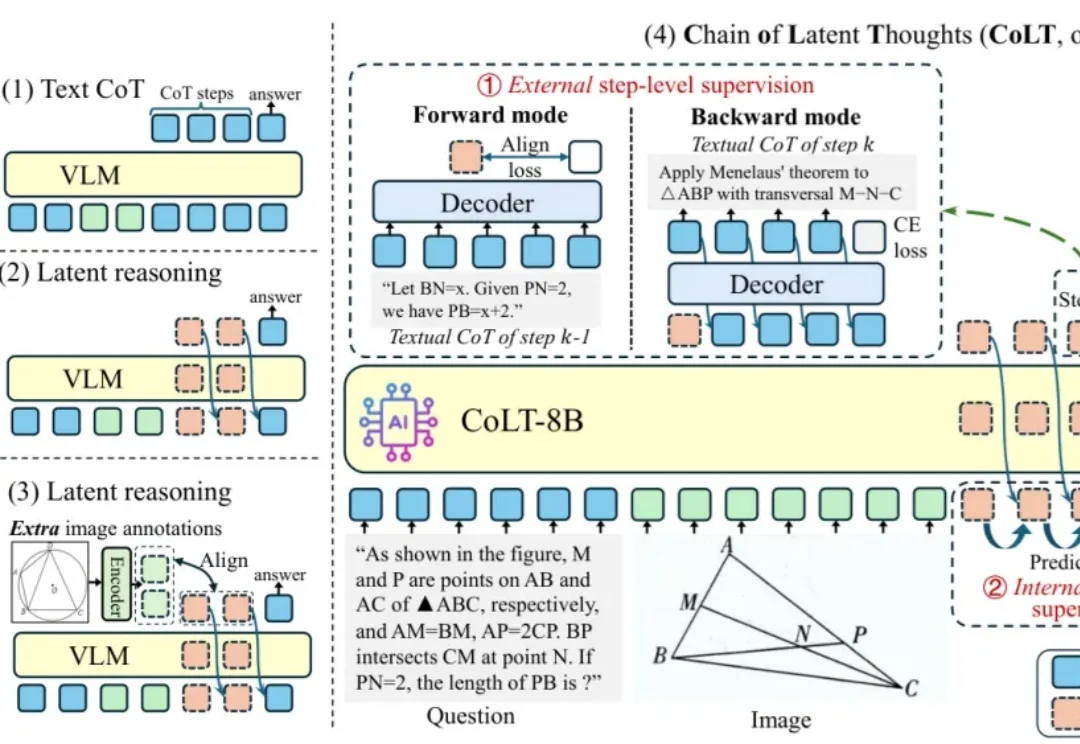
近年来,多模态大语言模型(MLLM)在视觉问答、图表理解、科学推理等任务上取得了令人瞩目的进展。
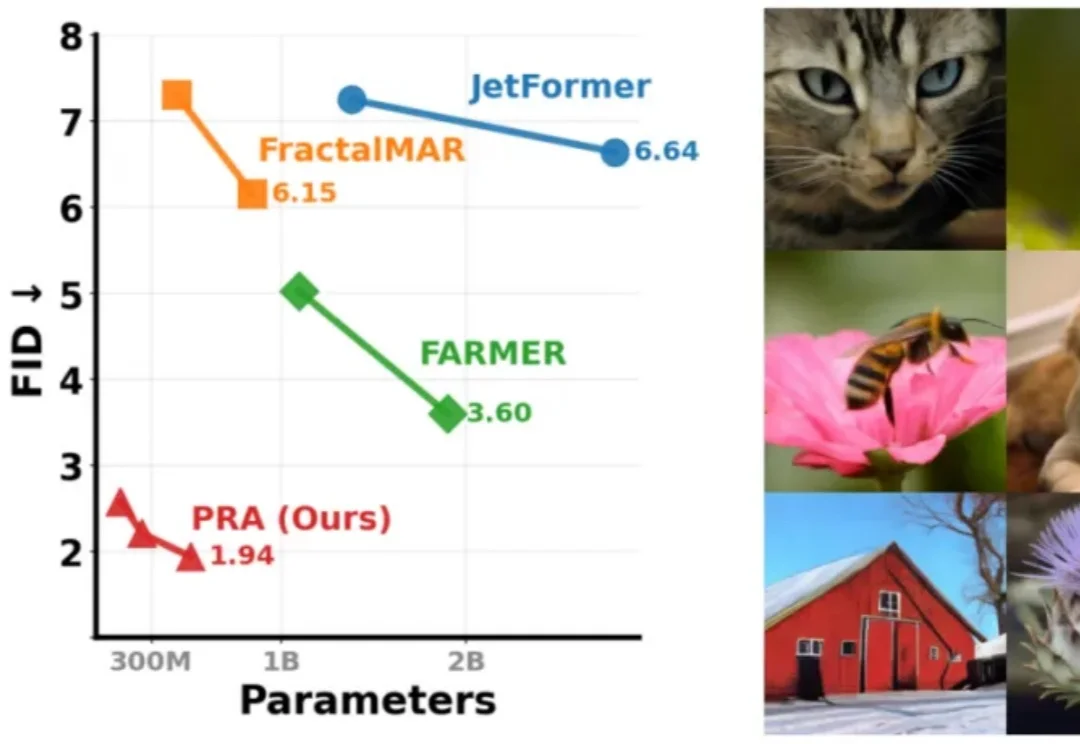
过去几年,扩散模型几乎定义了高质量图像生成:从随机噪声出发,经过多轮迭代,逐步 “雕刻” 出一张图像。但随着大语言模型席卷人工智能领域,另一条路线正迅速走到舞台中央 —— 图像,能否也像语言一样,通过自回归方式逐步生成?

大家好,我是冷逸。 前段时间,我设计了一家民宿「冷同学的院子」,视觉还算有点意思,不少朋友跑来问设计上的事。也有人问我:要是自己网上开店,有没有那种“够简单、说一句就能出设计”的电商工具?

音乐和视频之间那道墙,好像被打破了。 上个月,一个做独立音乐的朋友找我吃饭,聊到新歌宣发的事,愁得不行。 歌写好了,录完了,混音也做了,但到了要发的时候才发现,没有视觉内容。 发网易云?光秃秃一个音频

蚂蚁灵波选择了后一条路:开源 LingBot-Video。这是一个面向具身智能的视频生成基座模型,也是一套专为机器人场景设计的 DiT 视频预训练范式。通用视频模型更多学习画面变化、镜头运动和视觉风格;LingBot-Video 则把重点放在动作、任务、交互和物理环境变化上,面向世界预测、动作理解和机器人训练构建视频生成基座。

乐鑫信息科技 (688018.SH) 推出 ESP-VISION,一款面向 ESP32-P4、ESP32-S31 以及 ESP32-S3 系列芯片的低代码边缘 AI 与机器视觉框架。ESP-VISION 基于 MicroPython 提供统一的 sensor、image、display、espdl 等 Python API,整合摄像头采集、图像处理、视频编解码、
智东西获悉,OpenAI前研究员田永龙(Yonglong Tian)已确认于近期加入腾讯大语言模型部,后续将参与VLM(视觉语言模型)相关研发。在OpenAI期间,田永龙曾参与GPT-5的研发工作。加入OpenAI之前,他在Google Research和DeepMind长期从事视觉表征学习和对比学习等方向研究,对后续视觉模型以及多模态表征学习的发展产生了广泛影响。