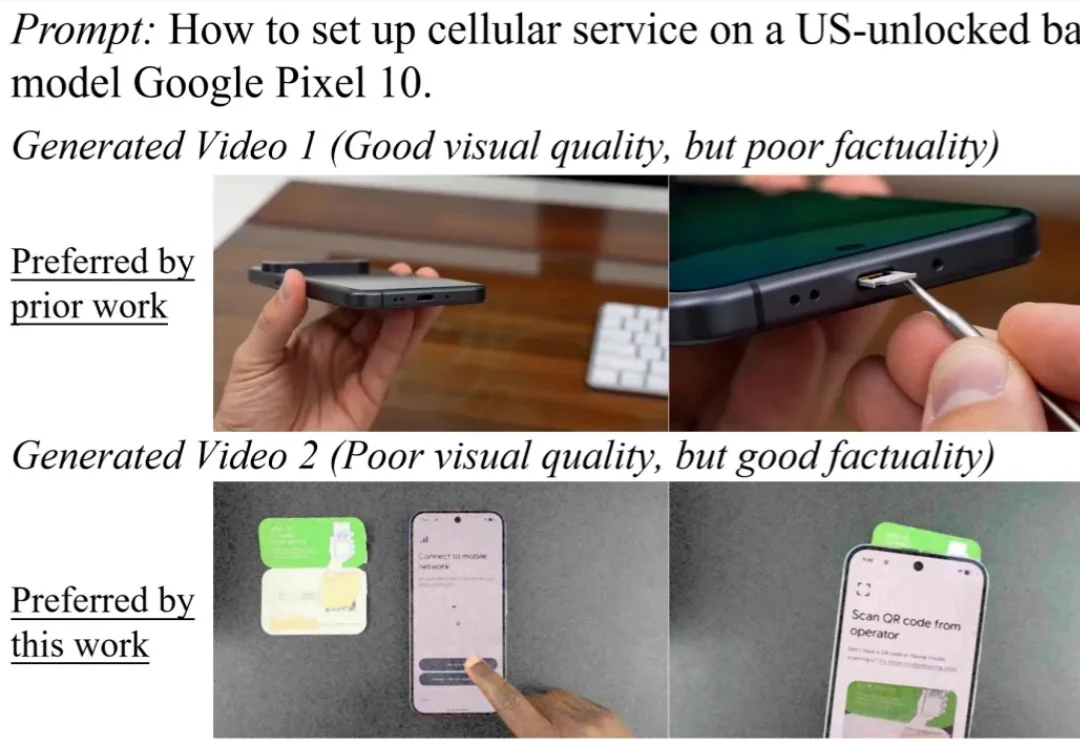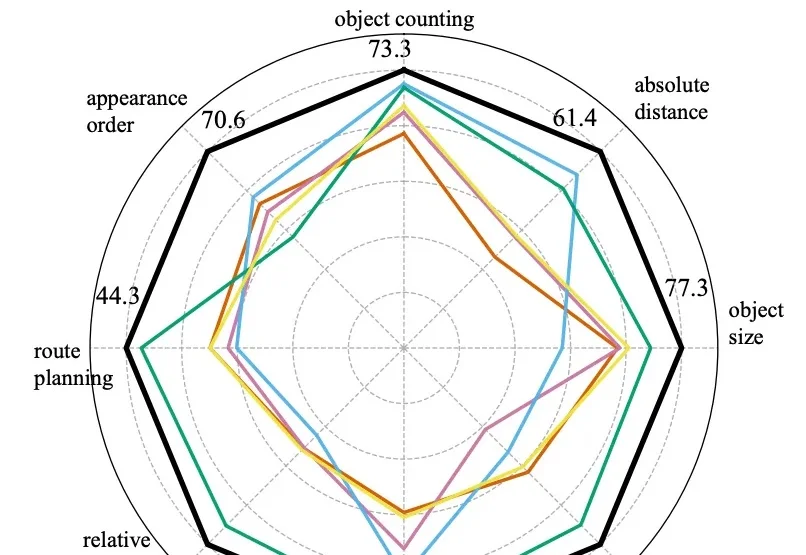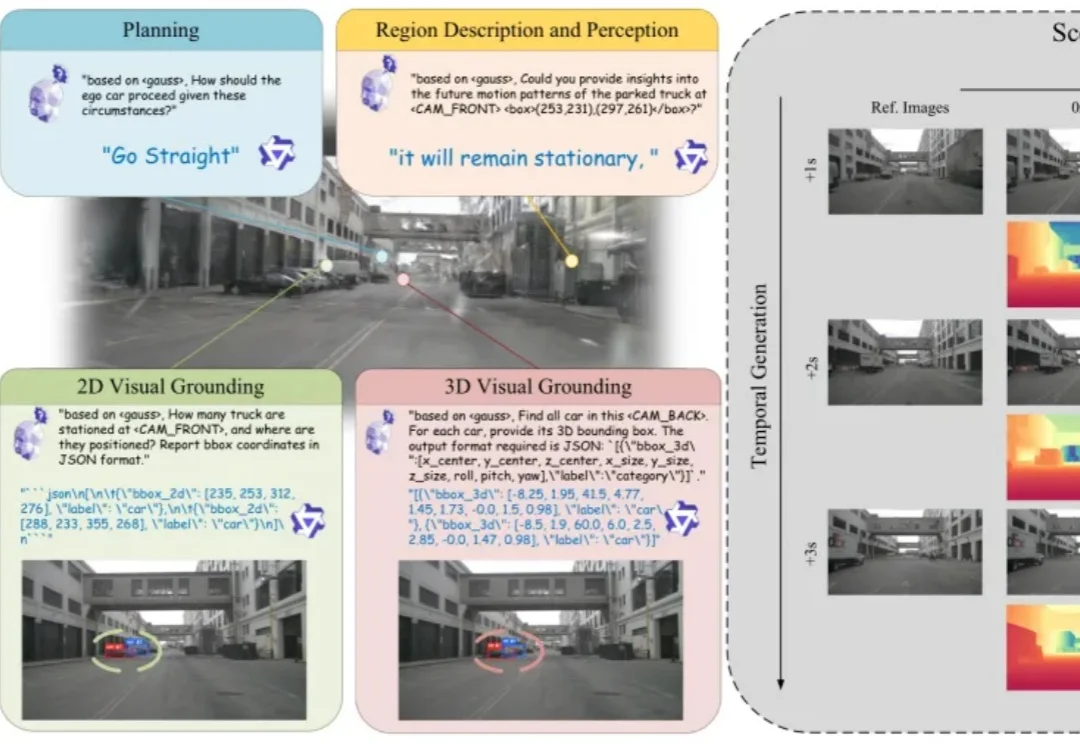
中科院工业人工智能研究所世界模型PAIWorld登顶WorldArena榜单!
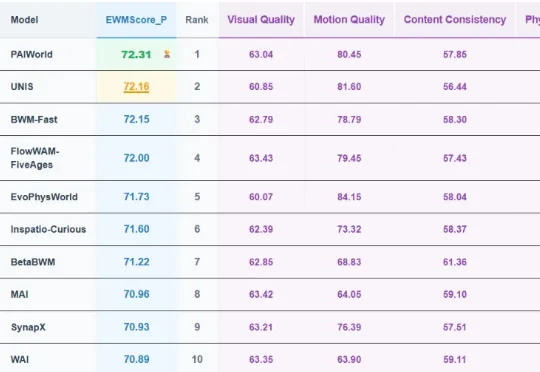
中科院工业人工智能研究所世界模型PAIWorld登顶WorldArena榜单!日前,世界模型国际权威榜单 WorldArena 更新排名,中国科学院工业人工智能研究所徐凯研究员带领物理智能团队(The PAI Lab)自研的世界模型 PAIWorld 登顶。WorldArena 作为目前世界模型领域最权威的评测榜单,是针对具身世界模型的全方位评价体系,涵盖视觉质量、运动质量、内容一致性、物理遵循、三维准确性及可控性六大维度
来自主题: AI资讯
8650 点击 2026-06-22 11:33