
视觉推理模型Top1易主了,智谱GLM-4.6V开源
视觉推理模型Top1易主了,智谱GLM-4.6V开源这一次,AI真的是快要砸掉我的饭碗了。智谱最新升级的新一代视觉推理模型——GLM-4.6V。在深度体验一波之后,我们发现写图文并茂的公众号推文,还只是GLM-4.6V能力的一隅。
来自主题: AI资讯
9529 点击 2025-12-09 00:50
 搜索
搜索
这一次,AI真的是快要砸掉我的饭碗了。智谱最新升级的新一代视觉推理模型——GLM-4.6V。在深度体验一波之后,我们发现写图文并茂的公众号推文,还只是GLM-4.6V能力的一隅。

在具身智能与视频理解飞速发展的今天,如何让 AI 真正 “看懂” 复杂的操作步骤?北京航空航天大学陆峰教授团队联合东京大学,提出视频理解新框架。该工作引入了 “状态(State)” 作为视觉锚点,解决了抽象文本指令与具象视频之间的对齐难题,已被人工智能顶级会议 AAAI 2026 接收。

全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。

大模型总是无法理解空间,就像我们难以想象四维世界。

Vision–Language–Action(VLA)策略正逐渐成为机器人迈向通用操作智能的重要技术路径:这类策略能够在统一模型内同时处理视觉感知、语言指令并生成连续控制信号。

在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。
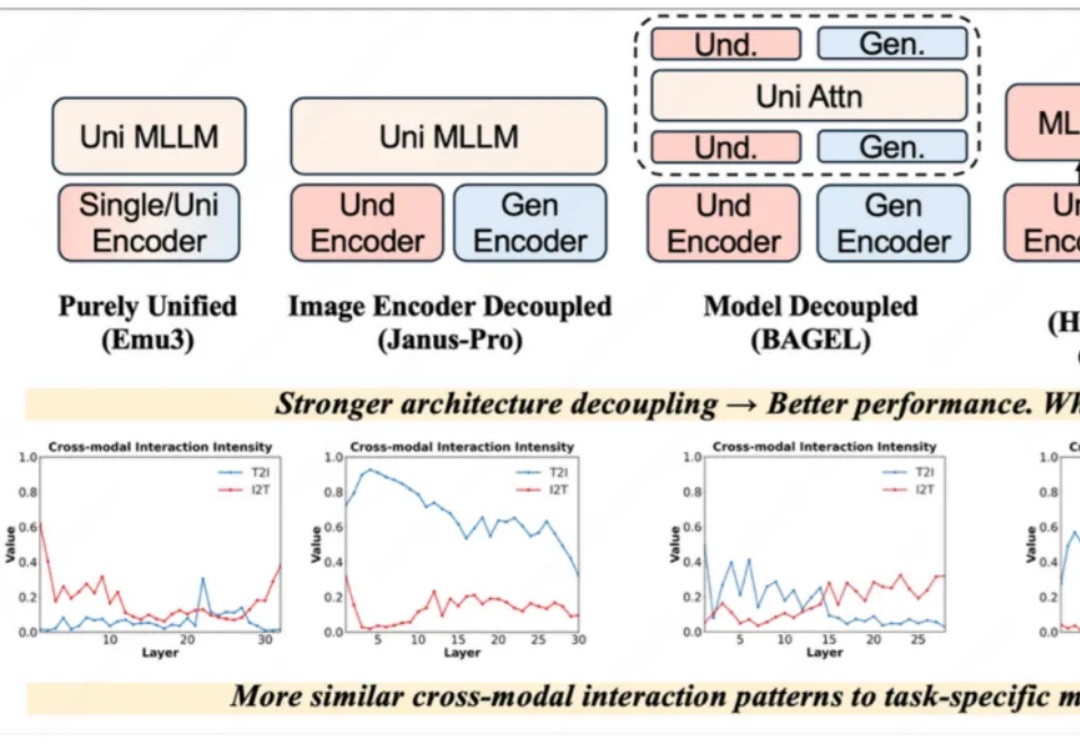
近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。

智东西11月28日报道,刚刚,快手开源其新一代旗舰多模态大模型Keye-VL-671B-A37B。该模型基于DeepSeek-V3-Terminus打造,拥有6710亿个参数,在保持基础模型通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了升级,实现了较强的多模态理解和复杂推理能力。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。