
统一视觉多模态与多任务!快手可灵与港科大团队发布视频生成模型,加速真实世界理解
统一视觉多模态与多任务!快手可灵与港科大团队发布视频生成模型,加速真实世界理解不仅能“听懂”物体的颜色纹理,还能“理解”深度图、人体姿态、运动轨迹……
来自主题: AI技术研报
8645 点击 2025-12-15 10:42
 搜索
搜索
不仅能“听懂”物体的颜色纹理,还能“理解”深度图、人体姿态、运动轨迹……

在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。

实现通用机器人的类人灵巧操作能力,是机器人学领域长期以来的核心挑战之一。近年来,视觉 - 语言 - 动作 (Vision-Language-Action,VLA) 模型在机器人技能学习方面展现出显著潜力,但其发展受制于一个根本性瓶颈:高质量操作数据的获取。

不久前,NeurIPS 2025 顺利举办,作为人工智能学术界的顶级会议之一,其中不乏学术界大佬的工作和演讲。

当AI不再仅仅是渲染队列中的一个工具,而是开始以智能体的身份,深度参与到剧本构思、视觉预览乃至最终剪辑的每一个环节,我们正站在一场影像文明变革的临界点。

外卖大战压力之下,美团正在打一场AI基建的硬仗。 文|邓咏仪 编辑|苏建勋 杨轩 《智能涌现》从多个信息源独家获悉,前闪极AI合伙人、前字节视觉大模型AI平台负责人潘欣,近期已经加入美团。 潘欣曾任谷
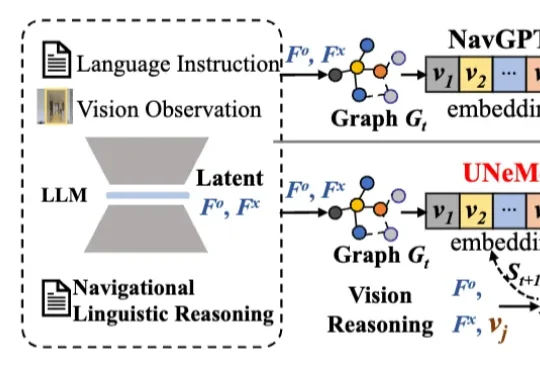
深圳大学李坚强教授团队最近联合北京理工莫斯科大学等机构,提出视觉-语言导航(VLN)新框架——UNeMo。让机器人听懂指令,精准导航再升级!

今天我们正式发布 Jina-VLM,这是一款 2.4B 参数量的视觉语言模型(VLM),在同等规模下达到了多语言视觉问答(Multilingual VQA)任务上的 SOTA 基准。Jina-VLM 对硬件需求较低,可在普通消费级显卡或 Macbook 上流畅运行。
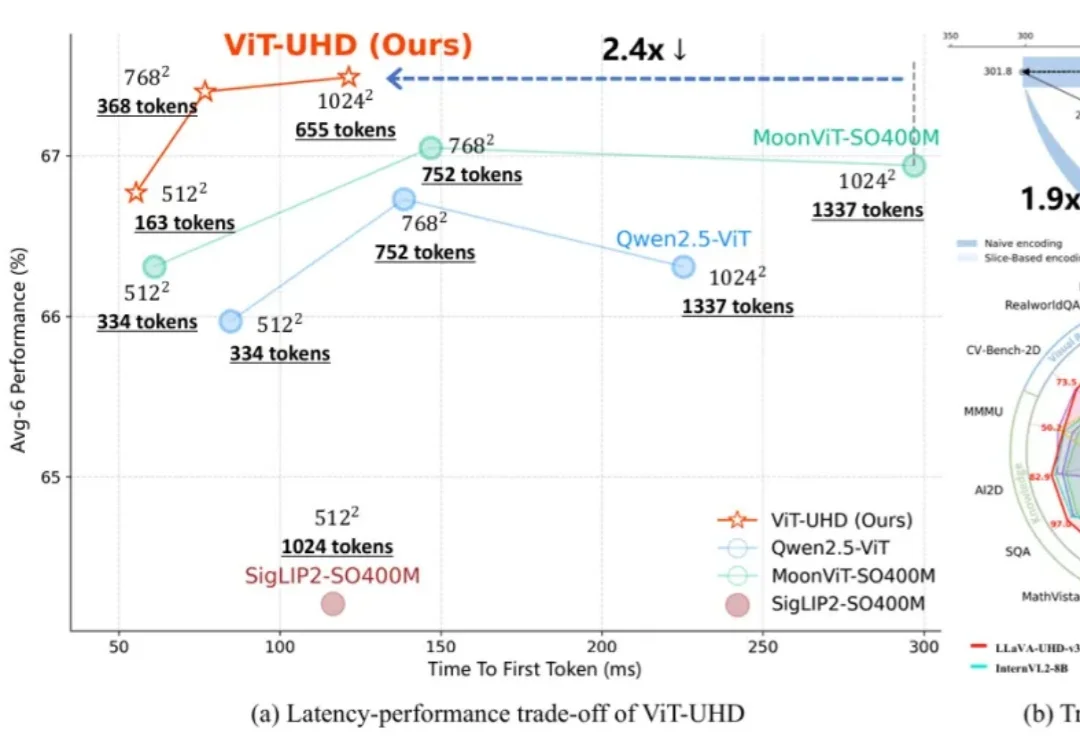
随着多模态大模型(MLLMs)在各类视觉语言任务中展现出强大的理解与交互能力,如何高效地处理原生高分辨率图像以捕捉精细的视觉信息,已成为提升模型性能的关键方向。
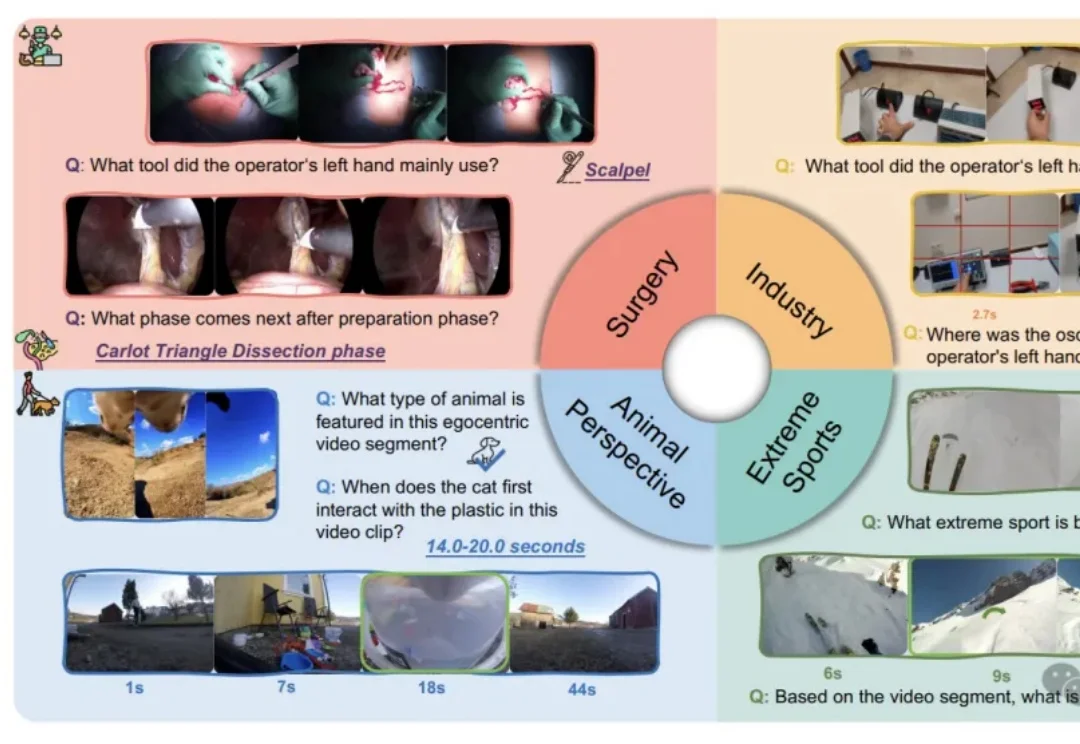
我们习惯了AI在屏幕上侃侃而谈、生成美图,好像它无所不知。但假如把它“扔”进一个真实的手术室,让它用主刀医生的第一视角来判断下一步该用哪把钳子,这位“学霸”很可能当场懵圈。