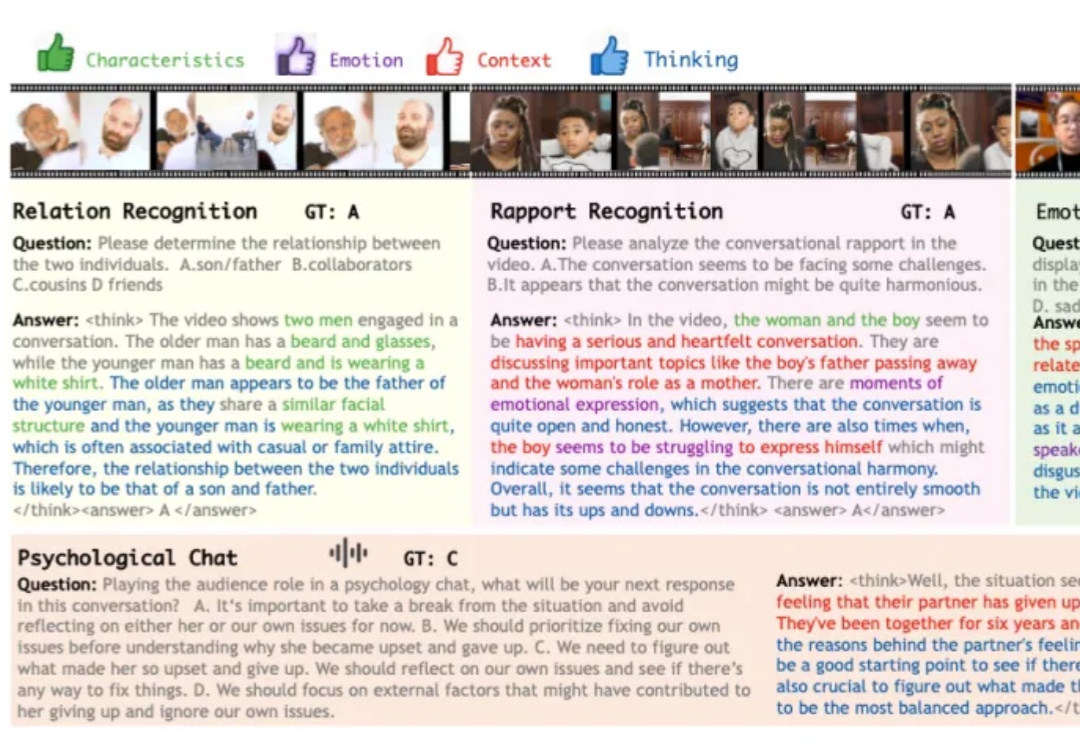
HumanSense:探索多模态推理边界,打造「察言观色会共情」的全模态交互伙伴
HumanSense:探索多模态推理边界,打造「察言观色会共情」的全模态交互伙伴在科幻作品描绘的未来,人工智能不仅仅是完成任务的工具,更是为人类提供情感陪伴与生活支持的伙伴。在实现这一愿景的探索中,多模态大模型已展现出一定潜力,可以接受视觉、语音等多模态的信息输入,结合上下文做出反馈。
来自主题: AI技术研报
8427 点击 2025-10-24 10:51
 搜索
搜索
在科幻作品描绘的未来,人工智能不仅仅是完成任务的工具,更是为人类提供情感陪伴与生活支持的伙伴。在实现这一愿景的探索中,多模态大模型已展现出一定潜力,可以接受视觉、语音等多模态的信息输入,结合上下文做出反馈。

长期以来,扩散模型的训练通常依赖由变分自编码器(VAE)构建的低维潜空间表示。然而,VAE 的潜空间表征能力有限,难以有效支撑感知理解等核心视觉任务,同时「VAE + Diffusion」的范式在训练
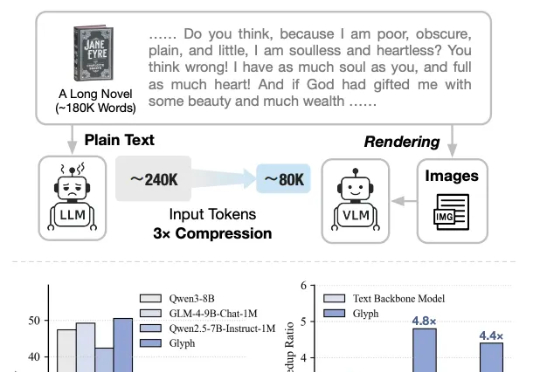
太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下:
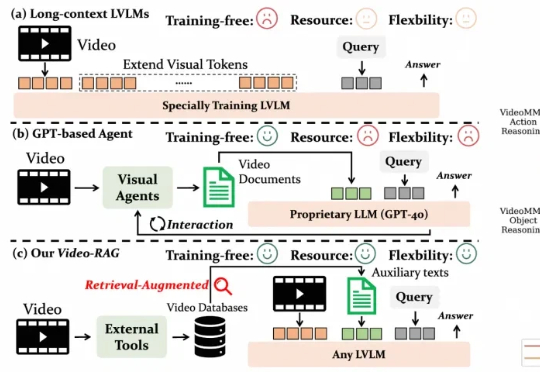
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。

DeepSeek最新开源的模型,已经被硅谷夸疯了!

AI新突破!DeepSeek-OCR以像素处理文本,压缩率小于1/10,基准测试领跑。开源一夜4.4k星,Karpathy技痒难耐,展望视觉输入的通用性。
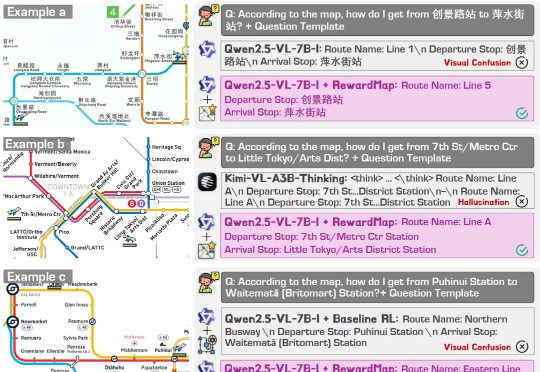
近年来,大语言模型(LLMs)以及多模态大模型(MLLMs)在多种场景理解和复杂推理任务中取得突破性进展。
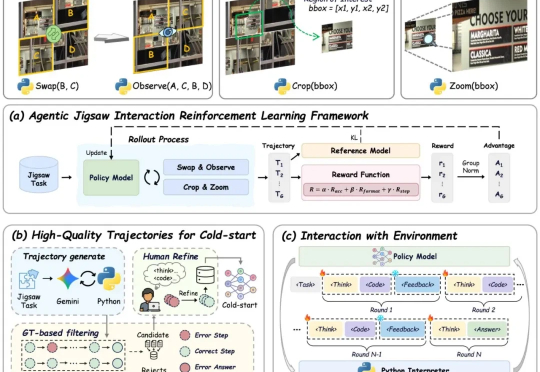
现有视觉语言大模型(VLMs)在多模态感知和推理任务上仍存在明显短板:1. 对图像中的细粒度视觉信息理解有限,视觉感知和推理能力未被充分激发;2. 强化学习虽能带来改进,但缺乏高质量、易扩展的 RL 数据。

复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。

刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。 该模型最大的突破在于极高的压缩效率: 20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。