
AI打通第一/第三人称视觉,跨视角视觉理解新SOTA|ICCV 2025 Highlight
AI打通第一/第三人称视觉,跨视角视觉理解新SOTA|ICCV 2025 Highlight具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!
来自主题: AI技术研报
10349 点击 2025-10-20 12:33
 搜索
搜索
具身智能落地迈出关键一步,AI拥有第一人称与第三人称的“通感”了!
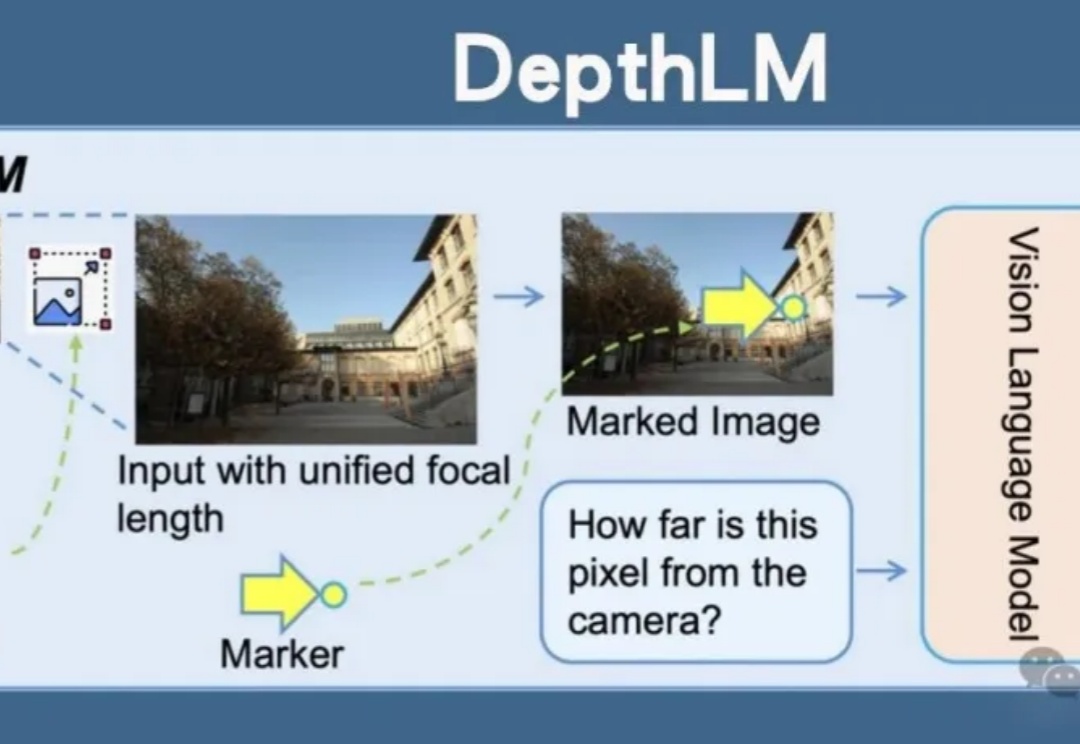
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
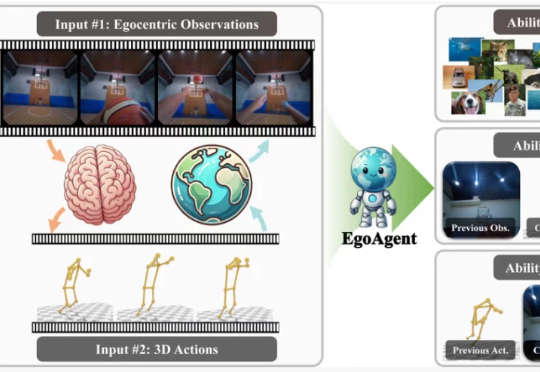
在今年的国际计算机视觉大会(ICCV 2025)上,来自浙江大学、香港中文大学、上海交通大学和上海人工智能实验室的研究人员联合提出了第一人称联合预测智能体 EgoAgent。
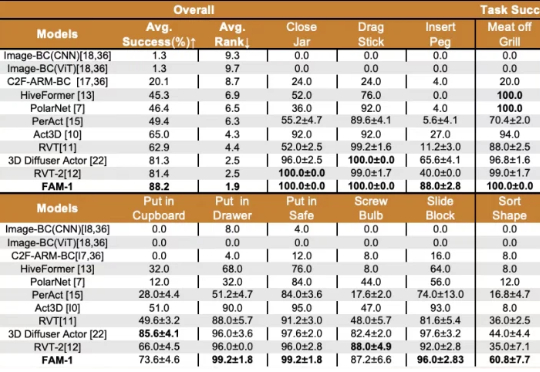
国内首个少样本通用具身操作基础模型发布,跨越视觉语言与机器人操作的鸿沟。
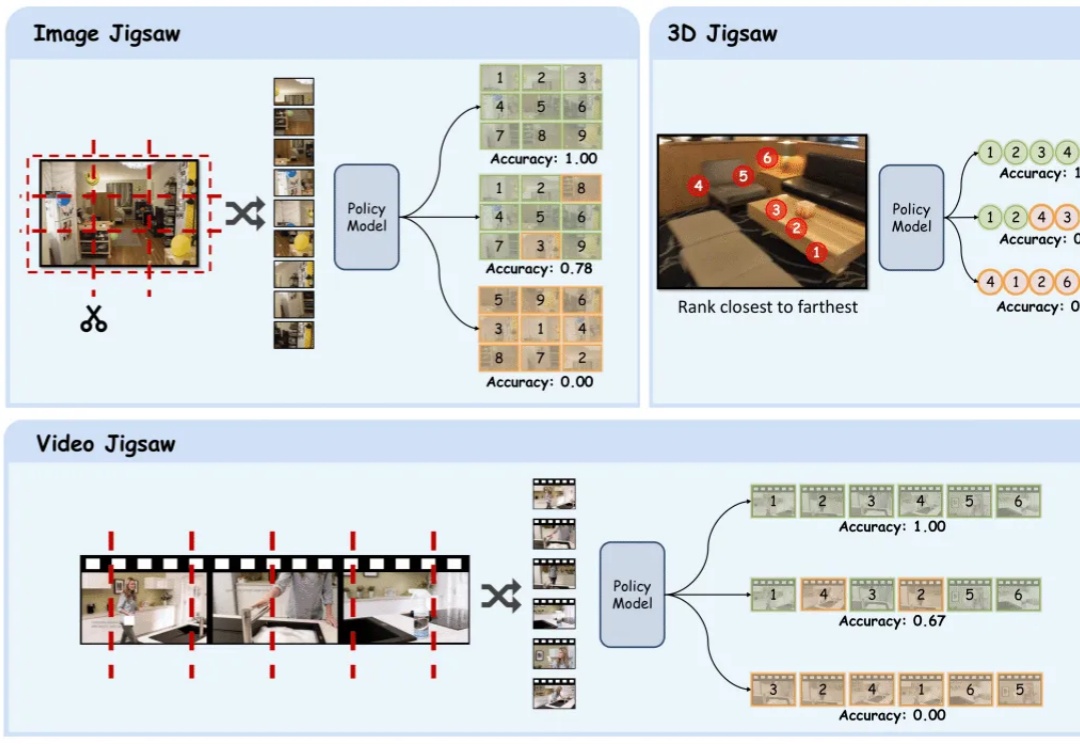
在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。
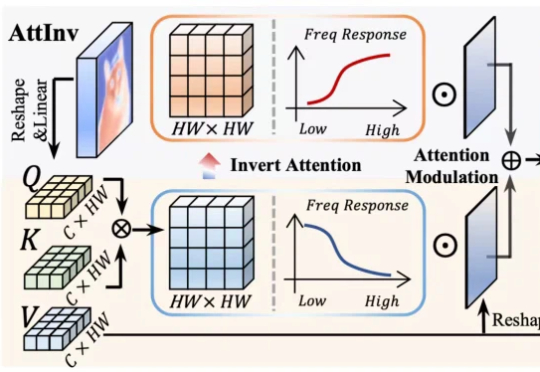
针对视觉 Transformer(ViT)因其固有 “低通滤波” 特性导致深度网络中细节信息丢失的问题,我们提出了一种即插即用、受电路理论启发的 频率动态注意力调制(FDAM)模块。它通过巧妙地 “反转” 注意力以生成高频补偿,并对特征频谱进行动态缩放,最终在几乎不增加计算成本的情况下,大幅提升了模型在分割、检测等密集预测任务上的性能,并取得了 SOTA 效果。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。
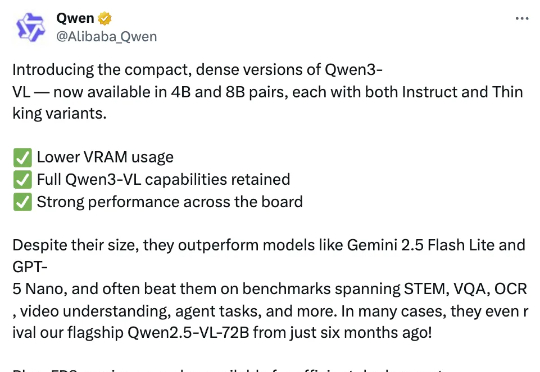
智东西10月15日报道,今日,阿里通义千问团队推出其最强视觉语言模型系列Qwen3-VL的4B与8B版本,两个尺寸均提供Instruct与Thinking版本,在几十项权威基准测评中超越Gemini 2.5 Flash Lite、GPT-5 Nano等同级别顶尖模型。
![苹果盯上Prompt AI, 不是买产品,是要伯克利团队的[视觉大脑]](https://www.aitntnews.com/pictures/2025/10/15/ca7bf835-a97f-11f0-88f9-fa163e47d677.jpg)
根据外媒 CNBC 消息,苹果公司正和计算机视觉领域的初创企业 Prompt AI,推进收购事宜的 “最后阶段谈判”。
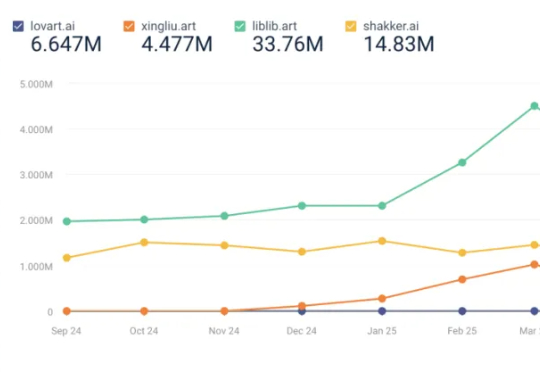
8 月榜单,最值得关注的变化是 Lovart 的访问量上升,8 月访问量上涨了 68.08% 至 323w,进入榜单。Lovart,读者想必已经熟悉,是奇点星宇的另一款 AI 视觉类产品,其产品核心设计为画布+对话框+编辑工具箱,也就是用户指导 AI 干活,