
ICLR神秘论文曝光!SAM3用「概念」看世界,重构视觉AI新范式
ICLR神秘论文曝光!SAM3用「概念」看世界,重构视觉AI新范式2023年Meta推出SAM,随后SAM 2扩展到视频分割,性能再度突破。近日,SAM 3悄悄现身ICLR 2026盲审论文,带来全新范式——「基于概念的分割」(Segment Anything with Concepts),这预示着视觉AI正从「看见」迈向真正的「理解」。
来自主题: AI技术研报
9381 点击 2025-10-15 12:18
 搜索
搜索
2023年Meta推出SAM,随后SAM 2扩展到视频分割,性能再度突破。近日,SAM 3悄悄现身ICLR 2026盲审论文,带来全新范式——「基于概念的分割」(Segment Anything with Concepts),这预示着视觉AI正从「看见」迈向真正的「理解」。

LLaVA 于 2023 年提出,通过低成本对齐高效连接开源视觉编码器与大语言模型,使「看图 — 理解 — 对话」的多模态能力在开放生态中得以普及,明显缩小了与顶级闭源模型的差距,标志着开源多模态范式的重要里程碑。
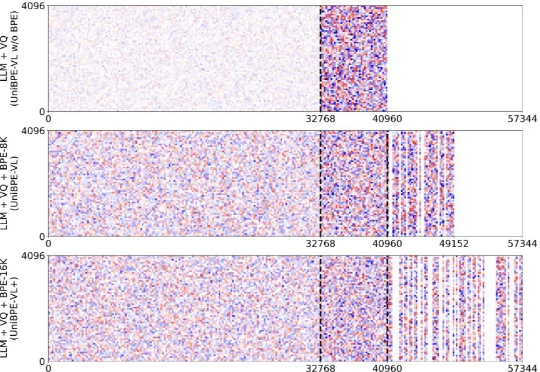
为此,北大、UC San Diego 和 BeingBeyond 联合提出一种新的方法——Being-VL 的视觉 BPE 路线。Being-VL 的出发点是把这一步后置:先在纯自监督、无 language condition 的设定下,把图像离散化并「分词」,再与文本在同一词表、同一序列中由同一 Transformer 统一建模,从源头缩短跨模态链路并保留视觉结构先验。
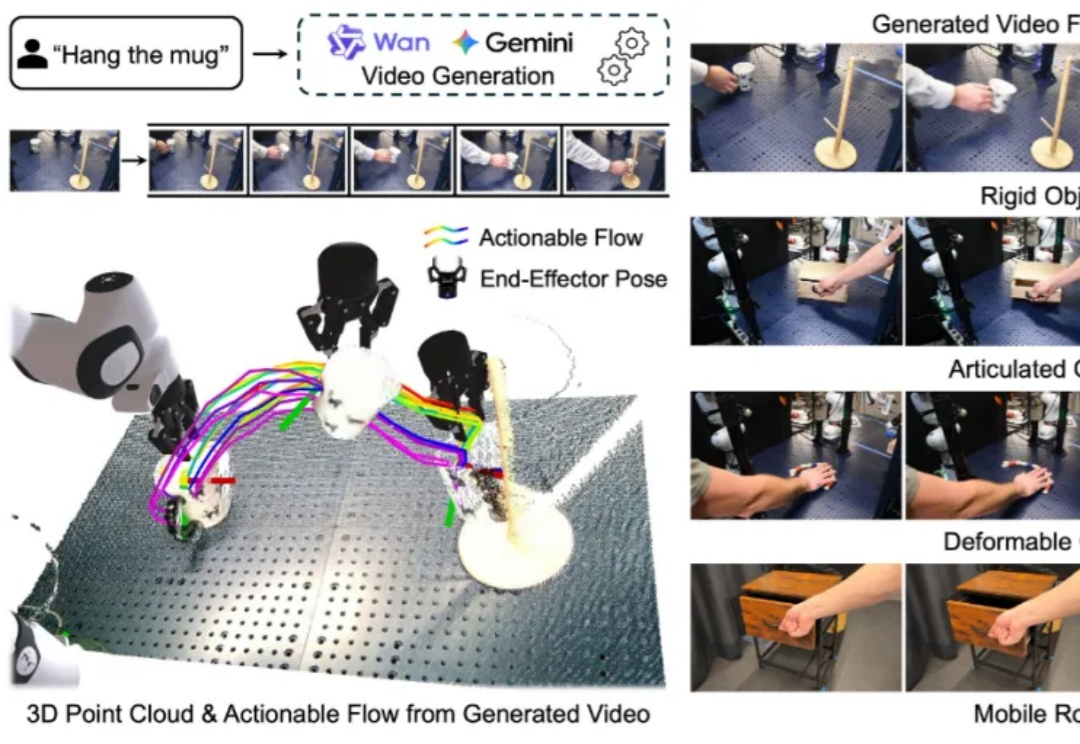
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。

在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化
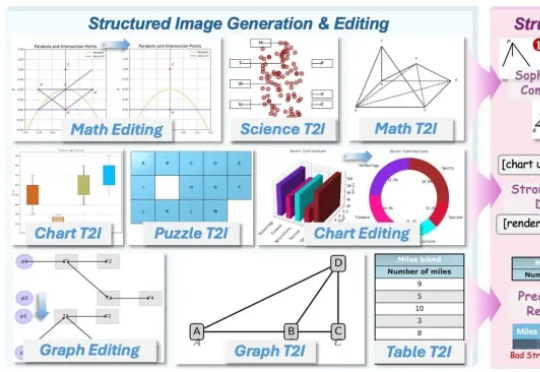
AI竟然画不好一张 “准确” 的图表?AI生图标杆如FLUX.1、GPT-Image,已经能生成媲美摄影大片的自然图像,却在柱状图、函数图这类结构化图像上频频出错,要么逻辑混乱、数据错误,要么就是标签错位。
库克和马斯克都盯上的CV公司!打开Prompt AI官网,上面介绍了这家公司的定位:一家专注于消费应用视觉智能的AI公司。这家总部位于旧金山的初创公司,其核心团队非常UC伯克利范儿:
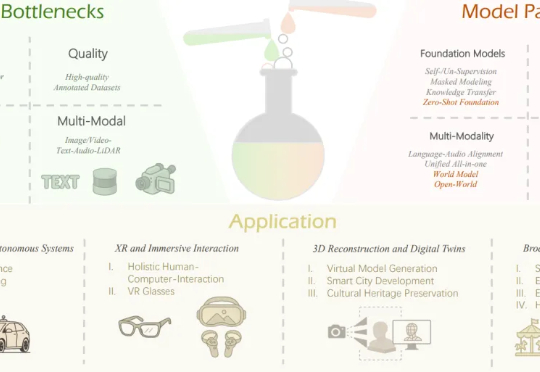
本文作者团队来自 Insta360 影石研究院及其合作高校。目前,Insta360 正在面向世界模型、多模态大模型、生成式模型等前沿方向招聘实习生与全职算法工程师,欢迎有志于前沿 AI 研究与落地的同
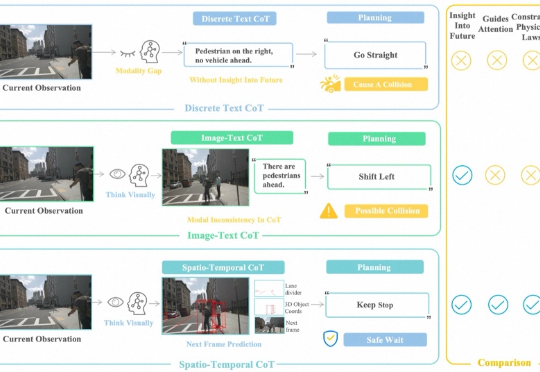
面向自动驾驶的多模态大模型在 “推理链” 上多以文字或符号为中介,易造成空间 - 时间关系模糊与细粒度信息丢失。FSDrive(FutureSightDrive)提出 “时空视觉 CoT”(Spatio-Temporal Chain-of-Thought),让模型直接 “以图思考”,用统一的未来图像帧作为中间推理步骤,联合未来场景与感知结果进行可视化推理。
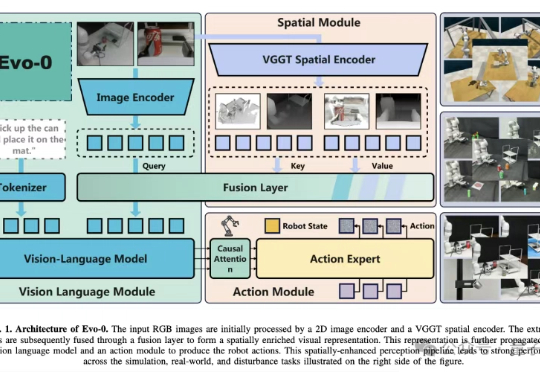
VLA模型通常建立在预训练视觉语言模型(VLM)之上,仅基于2D图像-文本数据训练,缺乏真实世界操作所需的3D空间理解能力。