千寻智能高阳团队最新成果:纯视觉VLA方案从有限数据中学到强大的空间泛化能力
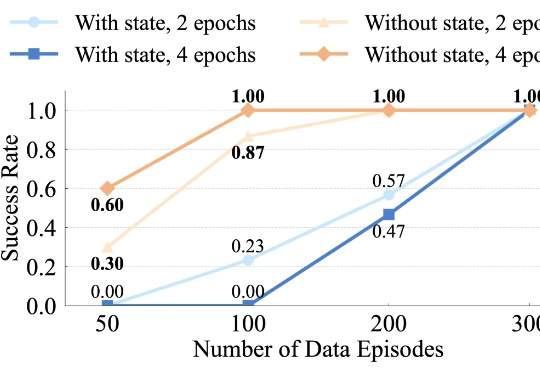
千寻智能高阳团队最新成果:纯视觉VLA方案从有限数据中学到强大的空间泛化能力最近,千寻智能的研究人员注意到,基于模仿学习的视觉运动策略中也存在类似现象,并在论文《Do You Need Proprioceptive States in Visuomotor Policies?》中对此进行了深入探讨。
来自主题: AI技术研报
8942 点击 2025-09-29 14:31
 搜索
搜索
最近,千寻智能的研究人员注意到,基于模仿学习的视觉运动策略中也存在类似现象,并在论文《Do You Need Proprioceptive States in Visuomotor Policies?》中对此进行了深入探讨。
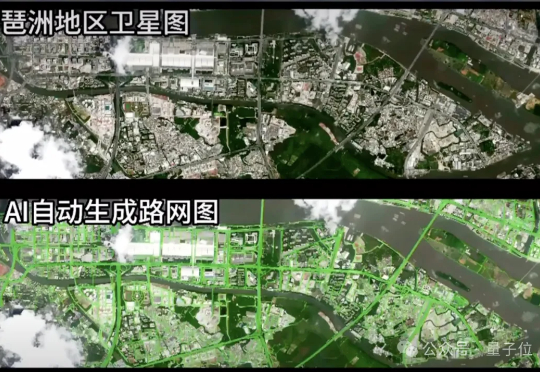
在一场视觉算法挑战中,一组参赛团队将道路识别模型部署至在轨卫星,完成了从图像采集、模型推理到结构化结果回传的全过程。 图像未落地,模型也并未运行在地面,所有计算任务均在轨道上完成,最终仅回传识别结果。
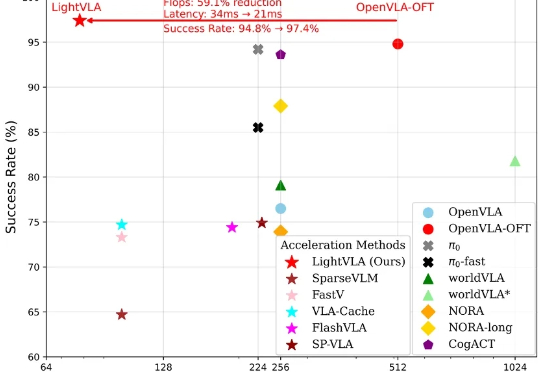
LightVLA 是一个旨在提升 VLA 推理效率且同时提升性能的视觉 token 剪枝框架。当前 VLA 模型在具身智能领域仍面临推理代价大而无法大规模部署的问题,然而大多数免训练剪枝框架依赖于中间注意力输出,并且会面临性能与效率的权衡问题。
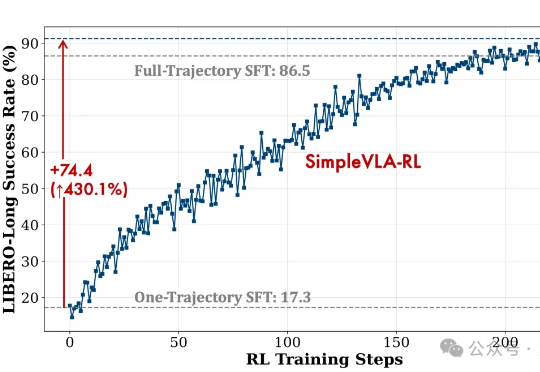
视觉-语言-动作模型是实现机器人在复杂环境中灵活操作的关键因素。然而,现有训练范式存在一些核心瓶颈,比如数据采集成本高、泛化能力不足等。
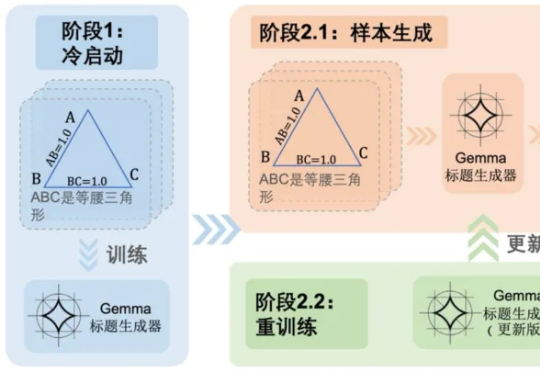
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视
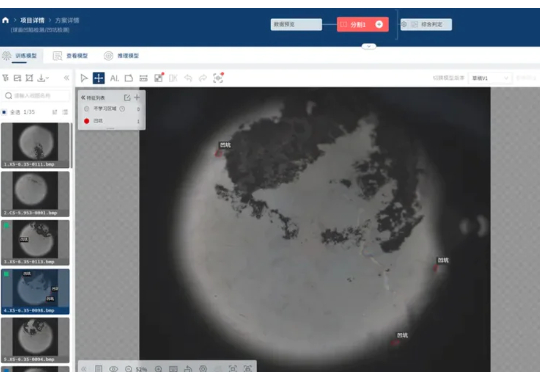
AI技术应用于小钢球质检,解决人工检测难题:通过视觉系统拍摄清晰图像、训练AI识别微米级缺陷、自动判决。实现从抽检到全检,速度提升100倍至5万颗/小时,准确率达95%,人力成本大幅降。老师傅转变为AI教练,方法可推广至其他领域。
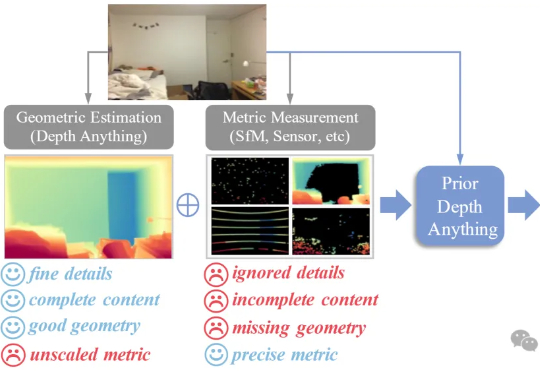
浙江大学与港大团队推出「Prior Depth Anything」,把稀疏的深度传感器数据与AI完整深度图融合,一键补洞、降噪、提分辨率,让手机、车载、AR眼镜都能实时获得精确三维视觉。无需额外训练,就能直接提升VGGT等3D模型的深度质量,零样本刷新多项深度补全、超分、修复纪录。
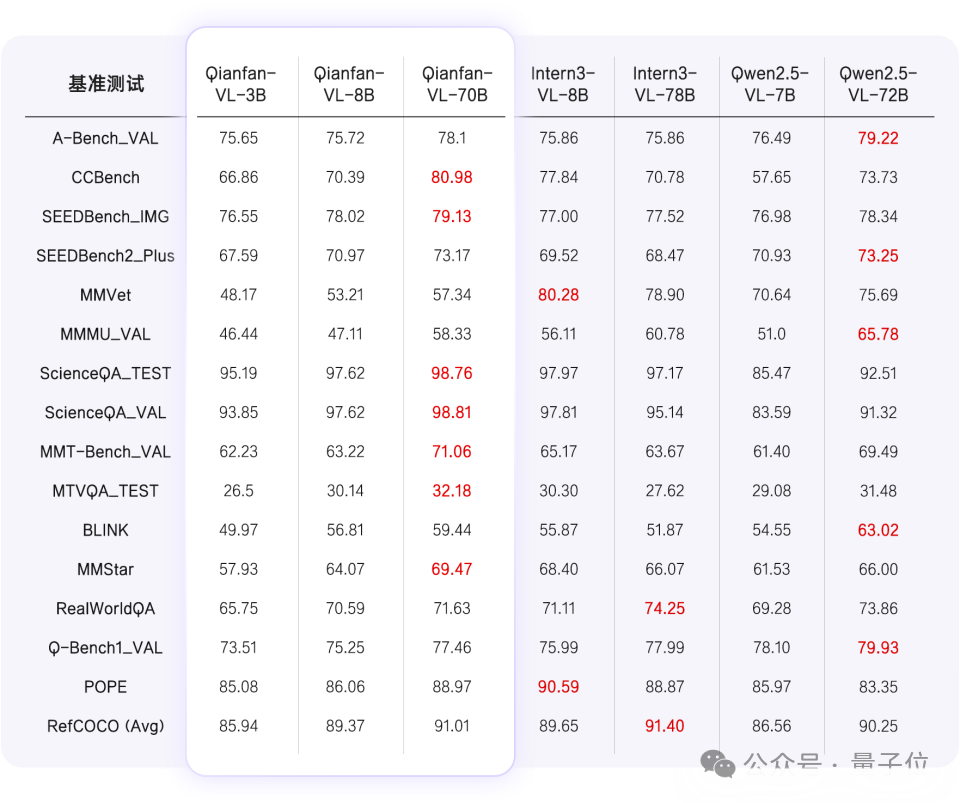
今天,百度智能云千帆正式推出全新视觉理解模型——Qianfan-VL,并全面开源!该系列包含3B、8B和70B三个尺寸版本,是面向企业级多模态应用场景,进行了深度优化的视觉理解大模型。

AI视频又进化了! Luma AI 发布全球首个推理视频模型,也是首个能够生成工作室级 HDR 的模型。 Ray3 是一款专为讲述故事而设计的 AI 视频模型。 它能够对视觉内容进行思考和推理,并提
近来,由AI生成的视频片段以前所未有的视觉冲击力席卷了整个互联网,视频生成模型创造出了许多令人惊叹的、几乎与现实无异的动态画面。