a16z投了两个华人560万美金,让AI成为每个人的专属摄影师
a16z投了两个华人560万美金,让AI成为每个人的专属摄影师这听起来像科幻电影,但Phota Labs正在让这一切成为现实。这家由前Adobe AI研究员创立的公司刚刚获得了由Andreessen Horowitz领投的560万美元种子轮融资,他们正在用个性化的视觉AI技术彻底重新定义摄影的边界。
来自主题: AI资讯
9079 点击 2025-09-18 14:30
 搜索
搜索
这听起来像科幻电影,但Phota Labs正在让这一切成为现实。这家由前Adobe AI研究员创立的公司刚刚获得了由Andreessen Horowitz领投的560万美元种子轮融资,他们正在用个性化的视觉AI技术彻底重新定义摄影的边界。
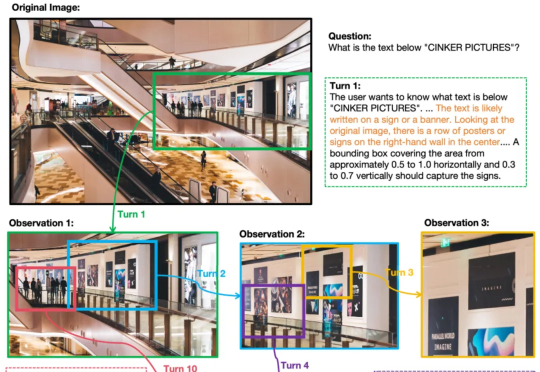
OpenAI o3的多轮视觉推理,有开源平替版了。并且,与先前局限于1-2轮对话的视觉语言模型(VLM)不同,它在训练限制轮数只有6轮的情况下,测试阶段能将思考轮数扩展到数十轮。

自动化修复真实世界的软件缺陷问题是自动化程序修复研究社区的长期目标。然而,如何自动化解决视觉软件缺陷仍然是一个尚未充分探索的领域。最近,随着 SWE-bench 团队发布最新的多模态 Issue 修复
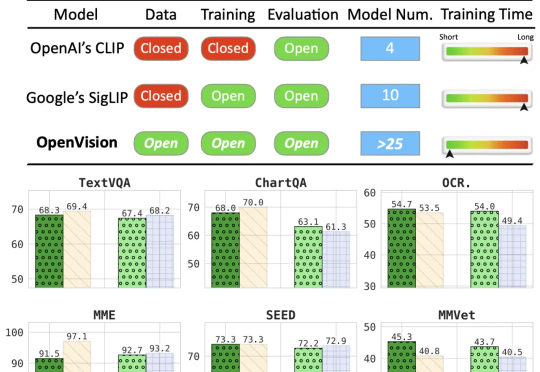
本文来自加州大学圣克鲁兹分校(UCSC)、苹果公司(Apple)与加州大学伯克利分校(UCB)的合作研究。第一作者刘彦青,本科毕业于浙江大学,现为UCSC博士生,研究方向包括多模态理解、视觉-语言预训

当我了解到一群平均年龄只有21岁的年轻创业者,在短短几天内就从Y Combinator、General Catalyst等顶级投资机构手中拿到500万美元融资时,我意识到他们可能找到了一个真正的痛点。这家叫Human Behavior的公司,正试图用AI彻底改变企业理解用户行为的方式。他们的方法听起来简单得令人怀疑:让AI直接"观看"用户使用产品的录像,然后自动分析出用户的真实意图和行为模式。

一般人准确率89.1%,AI最好只有13.3%。在新视觉基准ClockBench上,读模拟时钟这道「小学题」,把11个大模型难住了。为什么AI还是读不准表?是测试有问题还是AI真不行?
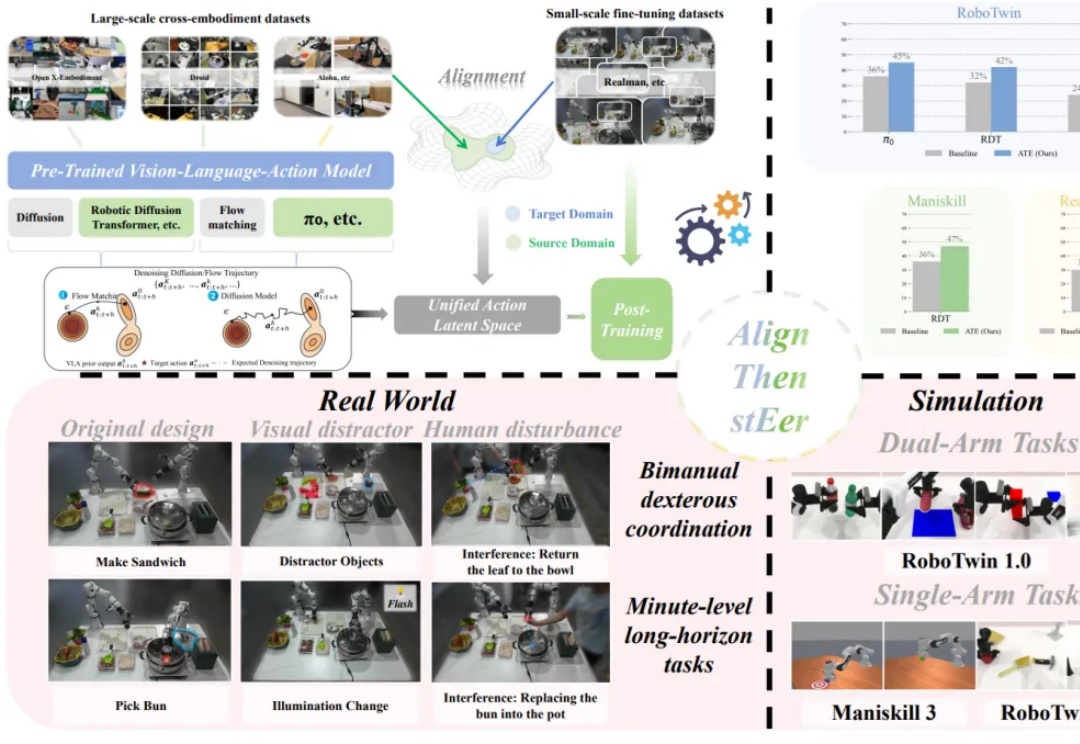
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。
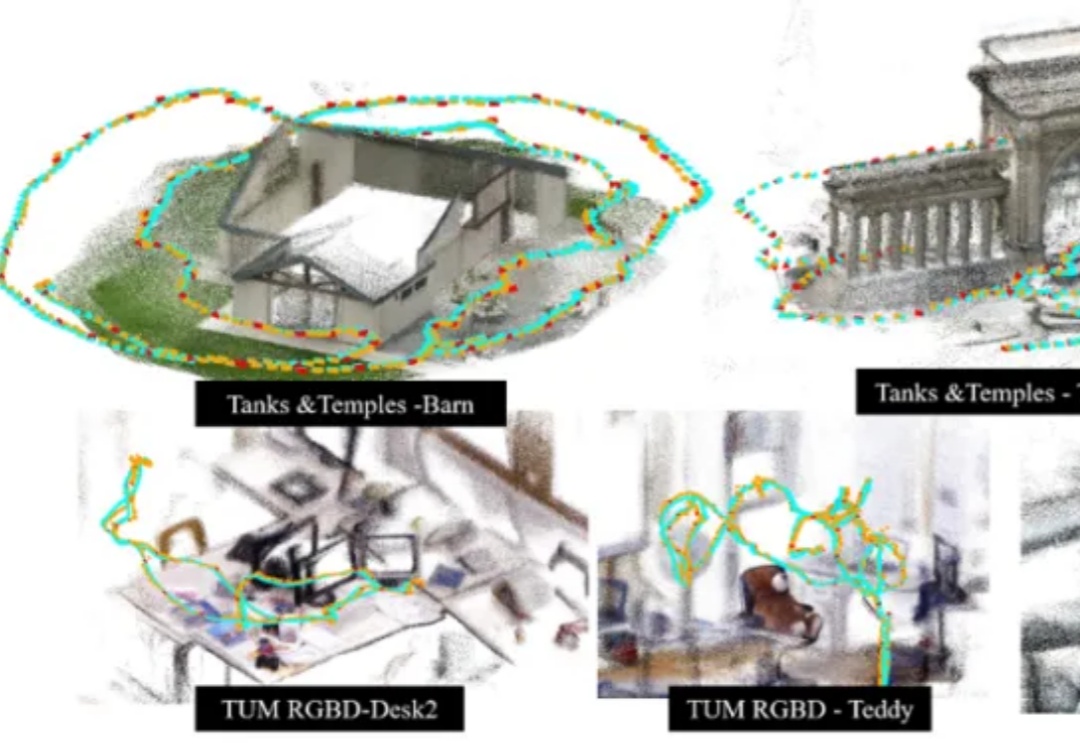
香港科技大学谭平教授团队与地平线(Horizon Robotics)团队最新发布了一项 3D 场景表征与大规模重建新方法 SAIL-Recon,通过锚点图建立构建场景全局隐式表征,突破现有 VGGT 基础模型对于大规模视觉定位与 3D 重建的处理能力瓶颈,实现万帧级的场景表征抽取与定位重建,将空间智能「3D 表征与建模」前沿推向一个新的高度。
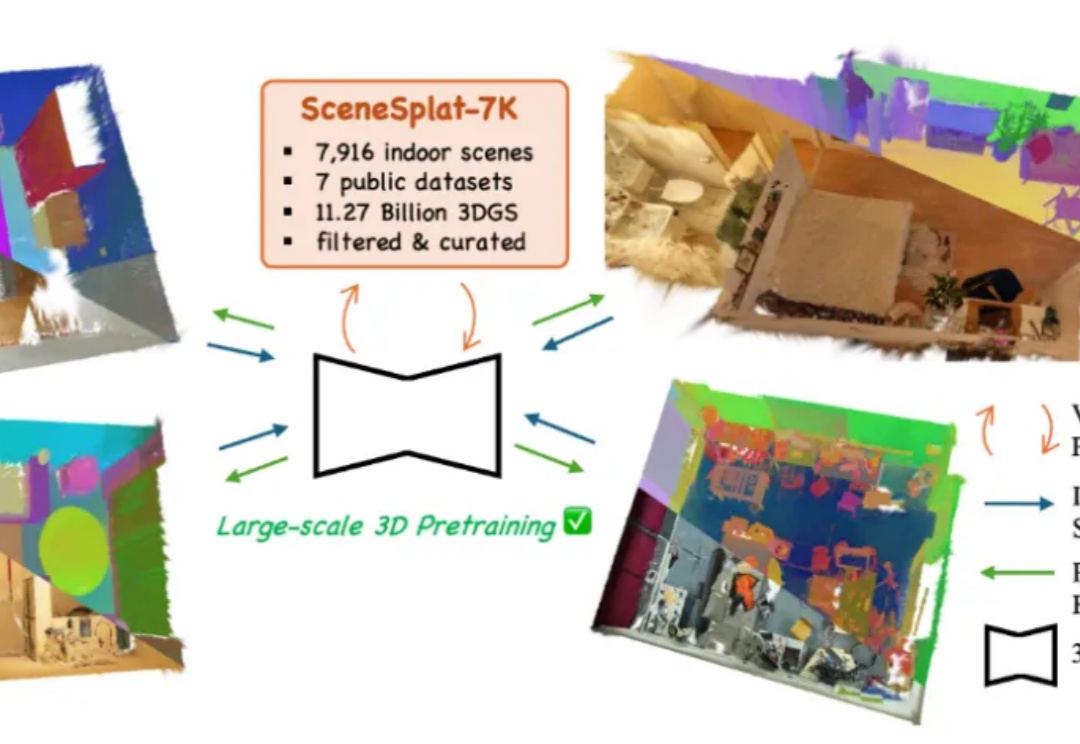
开放词汇识别与分类对于全面理解现实世界的 3D 场景至关重要。目前,所有现有方法在训练或推理过程中都依赖于 2D 或文本模态。这凸显出缺乏能够单独处理 3D 数据以进行端到端语义学习的模型,以及训练此类模型所需的数据。与此同时,3DGS 已成为各种视觉任务中 3D 场景表达的重要标准之一。

机器人终于不用散装大脑了! 字节Seed一个模型就能搞定机器人推理、任务规划和自然语言交互。