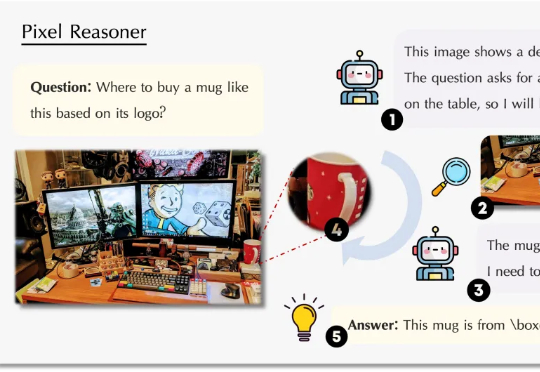
首创像素空间推理,7B模型领先GPT-4o,让VLM能像人类一样「眼脑并用」
首创像素空间推理,7B模型领先GPT-4o,让VLM能像人类一样「眼脑并用」视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。
来自主题: AI技术研报
8743 点击 2025-06-10 14:45
 搜索
搜索
视觉语言模型(VLM)正经历从「感知」到「认知」的关键跃迁。 当OpenAI的o3系列通过「图像思维」(Thinking with Images)让模型学会缩放、标记视觉区域时,我们看到了多模态交互的全新可能。

因为眼睛受伤暂时失去立体视觉,李飞飞更加坚定了做世界模型的决心。

刚发布就全网刷屏的 Kontext 靠“一致性”和“多模态理解”硬刚 OpenAI,在视觉生成界引发了一波震动。

图像生成、视频创作、照片精修需要找不同的模型完成也太太太太太麻烦了。 有没有这样一个“AI创作大师”,你只需要用一句话描述脑海中的灵感,它就能自动为你搭建流程、选择工具、反复修改,最终交付高质量的视觉作品呢?
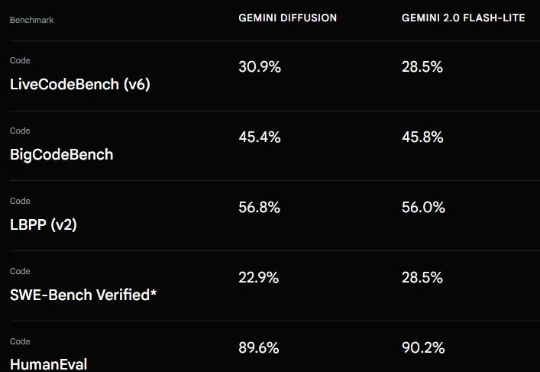
上个月 21 号,Google I/O 2025 开发者大会可说是吸睛无数,各种 AI 模型、技术、工具、服务、应用让人目不暇接。在这其中,Gemini Diffusion 绝对算是最让人兴奋的进步之一。从名字看得出来,这是一个采用了扩散模型的 AI 模型,而这个模型却并非我们通常看到的扩散式视觉生成模型,而是一个地地道道的语言模型!
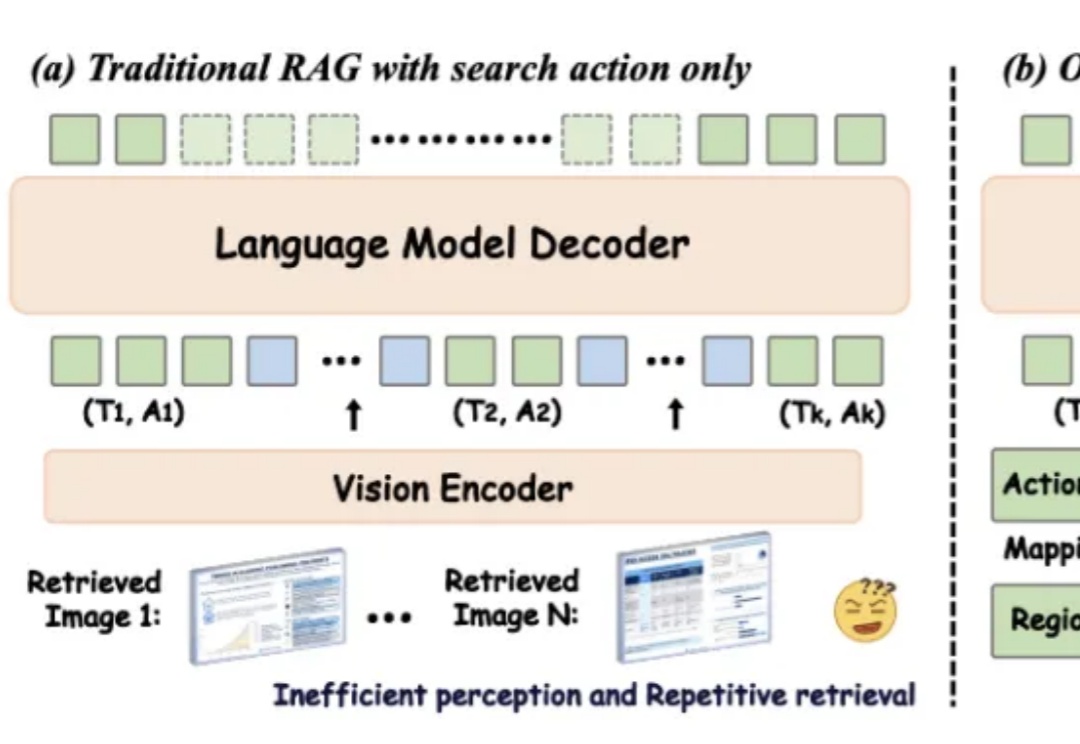
在数字化时代,视觉信息在知识传递和决策支持中的重要性日益凸显。然而,传统的检索增强型生成(RAG)方法在处理视觉丰富信息时面临着诸多挑战。一方面,传统的基于文本的方法无法处理视觉相关数据;另一方面,现有的视觉 RAG 方法受限于定义的固定流程,难以有效激活模型的推理能力。

在机器人抓香蕉这个事情上,它们依赖的是手眼协调,靠视觉学习如何抓取香蕉。它们最有独创性的地方在于它不是因为我们教了它上千次如何抓香蕉,而是它从 Gemini 那里获得了关于“如何抓取物体”的知识,然后将这些知识应用到现实世界的动作中。

如何让CLIP模型更关注细粒度特征学习,避免“近视”?360人工智能研究团队提出了FG-CLIP,可以明显缓解CLIP的“视觉近视”问题。让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。
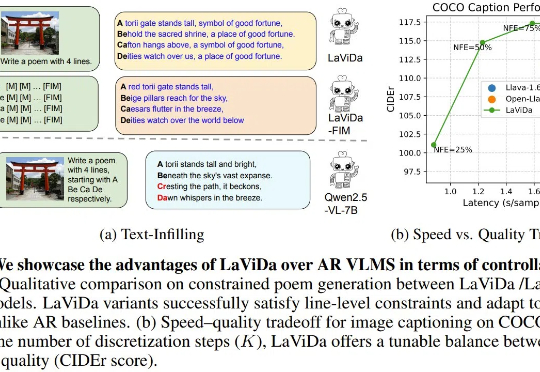
近段时间,已经出现了不少基于扩散模型的语言模型,而现在,基于扩散模型的视觉-语言模型(VLM)也来了,即能够联合处理视觉和文本信息的模型。今天我们介绍的这个名叫 LaViDa,继承了扩散语言模型高速且可控的优点,并在实验中取得了相当不错的表现。
在建筑行业中,管理人员很容易与现场实际情况脱节。他们需要同时处理多项任务,包括掌握成本动态、与所有利益相关方沟通,以及评估与承包商账单和绩效等方面相关的风险。