
机器狗能当羽毛球搭子了!仅靠强化学习从0自学,还涌现出类人回位行为 | Science子刊
机器狗能当羽毛球搭子了!仅靠强化学习从0自学,还涌现出类人回位行为 | Science子刊来和机器狗一起运动不?你的羽毛球搭子来了!无需人工协助,仅靠强化学习,机器狗子就学会了羽毛球哐哐对打。基于强化学习,研究人员开发了机器狗的全身视觉运动控制策略,同步控制腿部(18个自由度)移动,和手臂挥拍动作。
来自主题: AI技术研报
10636 点击 2025-05-30 17:08
 搜索
搜索
来和机器狗一起运动不?你的羽毛球搭子来了!无需人工协助,仅靠强化学习,机器狗子就学会了羽毛球哐哐对打。基于强化学习,研究人员开发了机器狗的全身视觉运动控制策略,同步控制腿部(18个自由度)移动,和手臂挥拍动作。

在人类的认知过程中,视觉思维(Visual Thinking)扮演着不可替代的核心角色,这一现象贯穿于各个专业领域和日常生活的方方面面。
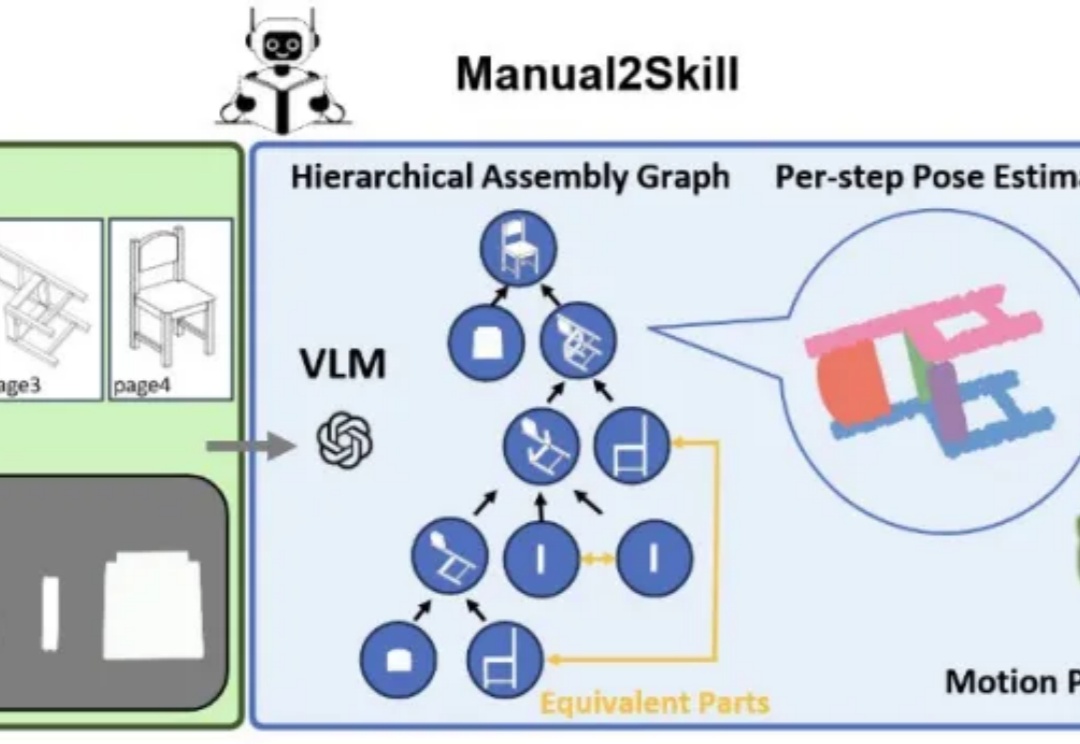
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。

最近“AI ✖像素风”的搭配突然变得很热门,创作者们用粗颗粒感、低分辨率、强符号化这种带着复古游戏风格的视觉语言进行表达,加上轻松、幽默的气质,很容易在信息流中抓人眼球。
仅需一个强化学习(RL)框架,就能实现视觉任务大统一?
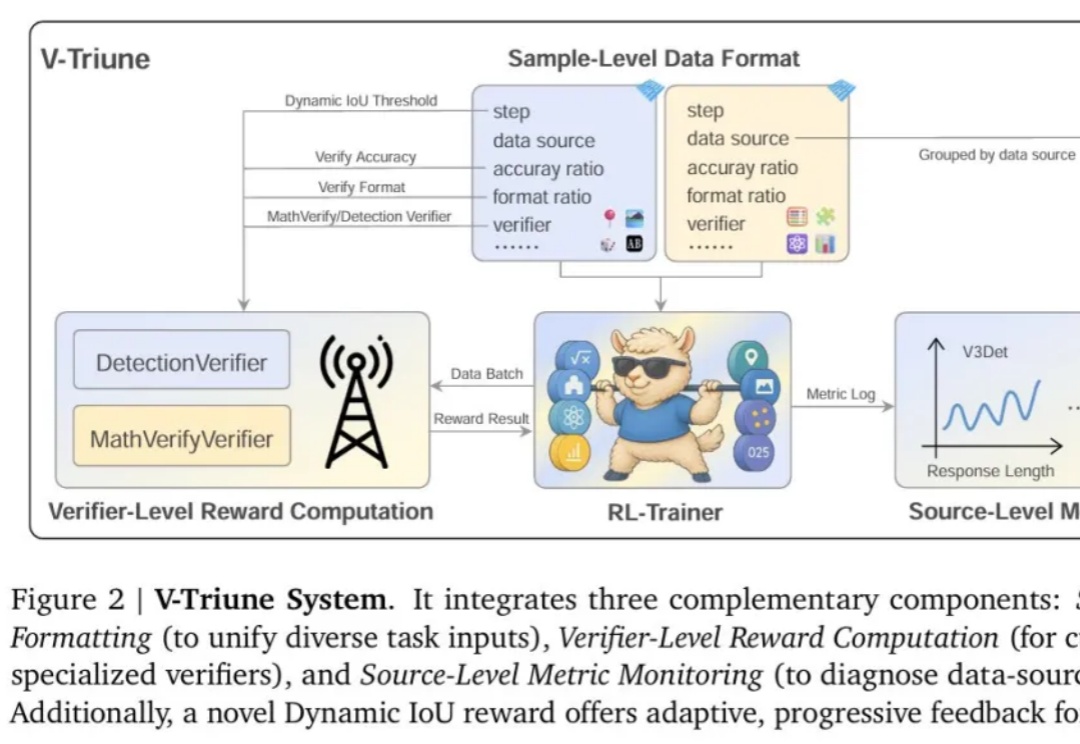
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。然而,RL 在推理任务之外的应用,尤其是在目标检测 和目标定位等感知密集型任务中的应用,仍有待深入探索。

在大型推理模型(例如 OpenAI-o3)中,一个关键的发展趋势是让模型具备原生的智能体能力。具体来说,就是让模型能够调用外部工具(如网页浏览器)进行搜索,或编写/执行代码以操控图像,从而实现「图像中的思考」。
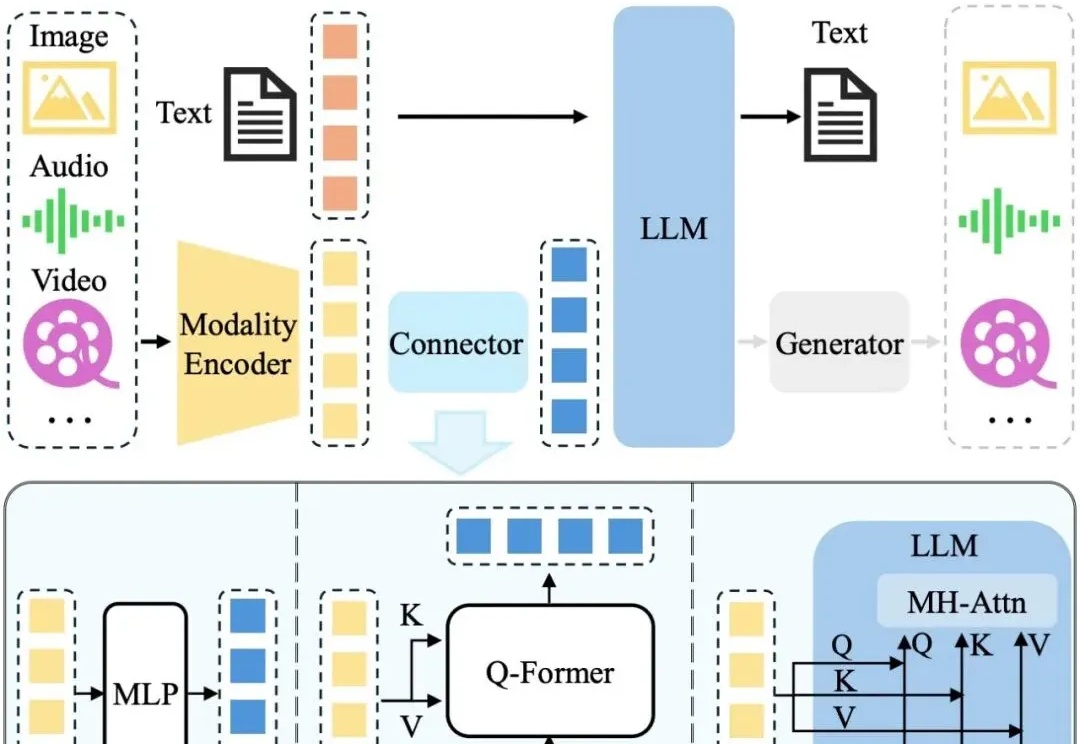
近年来,LLM 及其多模态扩展(MLLM)在多种任务上的推理能力不断提升。然而, 现有 MLLM 主要依赖文本作为表达和构建推理过程的媒介,即便是在处理视觉信息时也是如此 。

而马毅是那类觉得不够的人,他于无声处开始提问:智能的本质是什么?自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算与数据科学学院院长。他和团队提出的压缩感知技术,到现在还在影响计算机视觉中模式识别领域的发展。
咱就是说啊,视觉基础模型这块儿,国产AI真就是上了个大分——Glint-MVT,来自格灵深瞳的最新成果。Glint-MVT,来自格灵深瞳的最新成果先来看下成绩——线性探测(LinearProbing):