CVPR 25 |全面提升视觉感知鲁棒性,生成模型快速赋能三维检测
CVPR 25 |全面提升视觉感知鲁棒性,生成模型快速赋能三维检测来自香港中文大学(深圳)等单位的学者们提出了一种名为 DriveGEN 的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。
来自主题: AI技术研报
9474 点击 2025-05-23 14:09
 搜索
搜索
来自香港中文大学(深圳)等单位的学者们提出了一种名为 DriveGEN 的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。

在机器人操作中,物体运动往往涉及摩擦、碰撞等复杂物理机制。准确的物理属性描述可以实现对物体运动结果更准确的预测,并提升机器人在操作技能学习中的表现。

不再依赖语言,仅凭图像就能完成模型推理?

手绘草图一键变身专业游戏形象:
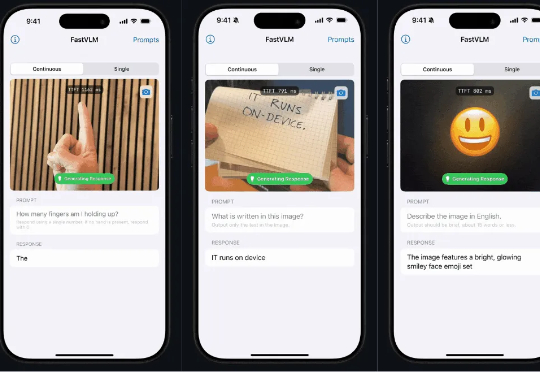
FastVLM—— 让苹果手机拥有极速视觉理解能力
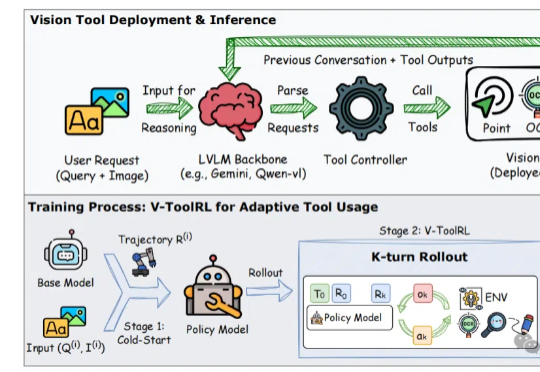
教AI学会使用工具,带图推理就能变得更强?!
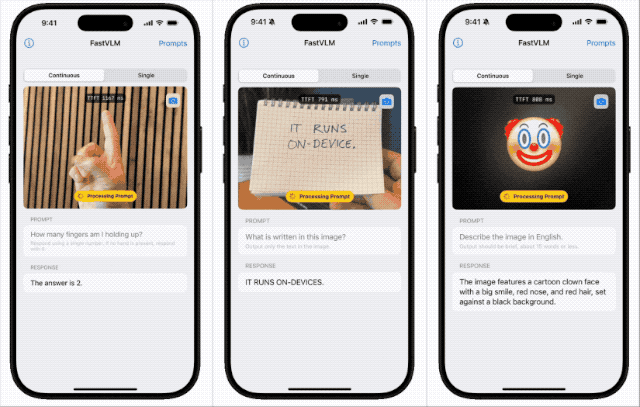
苹果近期开源本地端侧视觉语言模型FastVLM,支持iPhone等设备本地运行,具备快速响应、低延迟和多设备适配特性。该模型依托自研框架MLX和视觉架构FastViT-HD,通过算法优化实现高效推理,或为未来智能眼镜等新硬件铺路,体现苹果将AI深度嵌入系统底层的战略布局。

在电商世界,没有人会忽视视觉的力量。
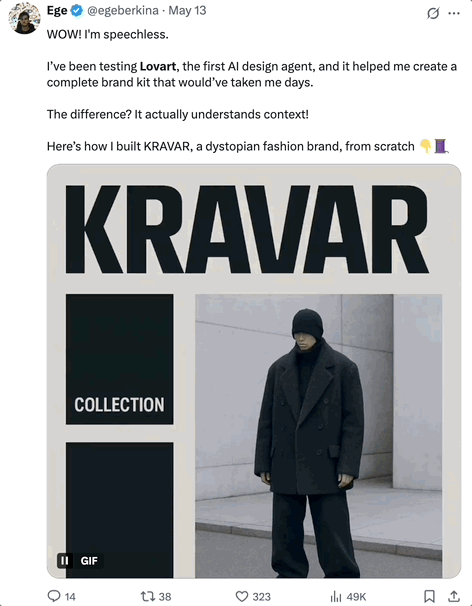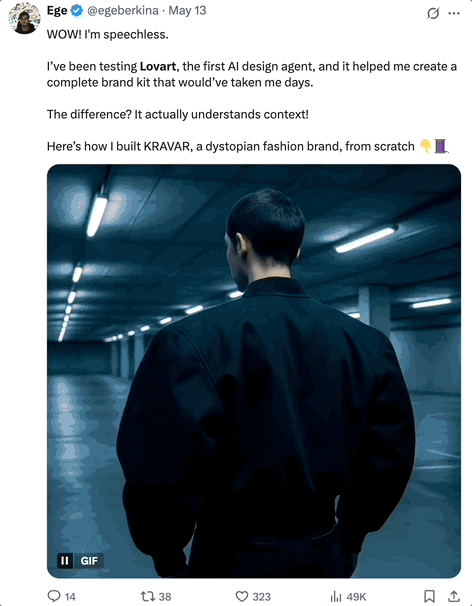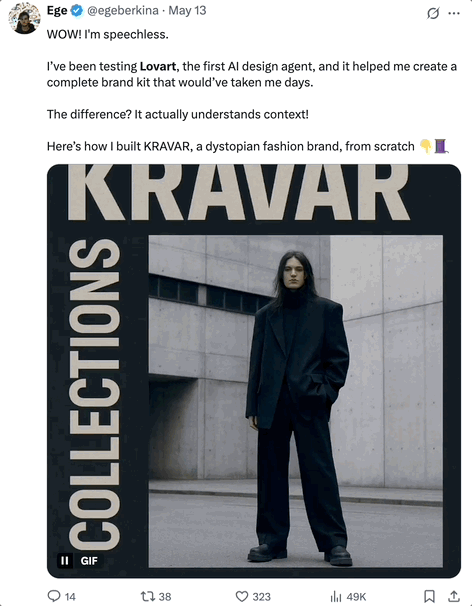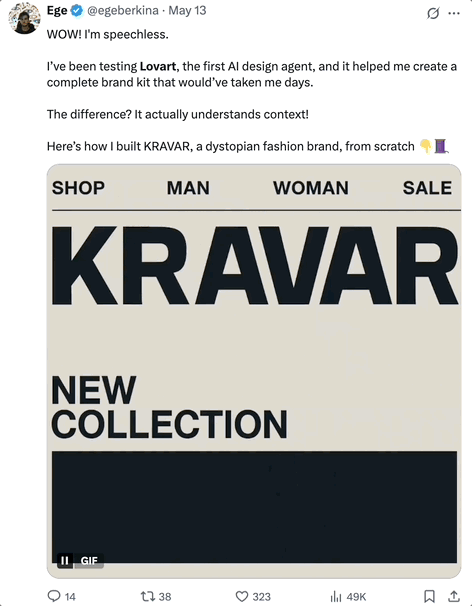
又一个Agent火爆全网—— 一句话搞定专业视觉设计,就连专业设计师大V都在疯狂安利!

R1 横空出世,带火了 GRPO 算法,RL 也随之成为 2025 年的热门技术探索方向,近期,字节 Seed 团队就在图像生成方向进行了相关探索。