
字节最强多模态模型登陆火山引擎!Seed1.5-VL靠20B激活参数狂揽38项SOTA
字节最强多模态模型登陆火山引擎!Seed1.5-VL靠20B激活参数狂揽38项SOTA字节拿出了国际顶尖水平的视觉–语言多模态大模型。
来自主题: AI资讯
12498 点击 2025-05-14 16:23
 搜索
搜索
字节拿出了国际顶尖水平的视觉–语言多模态大模型。
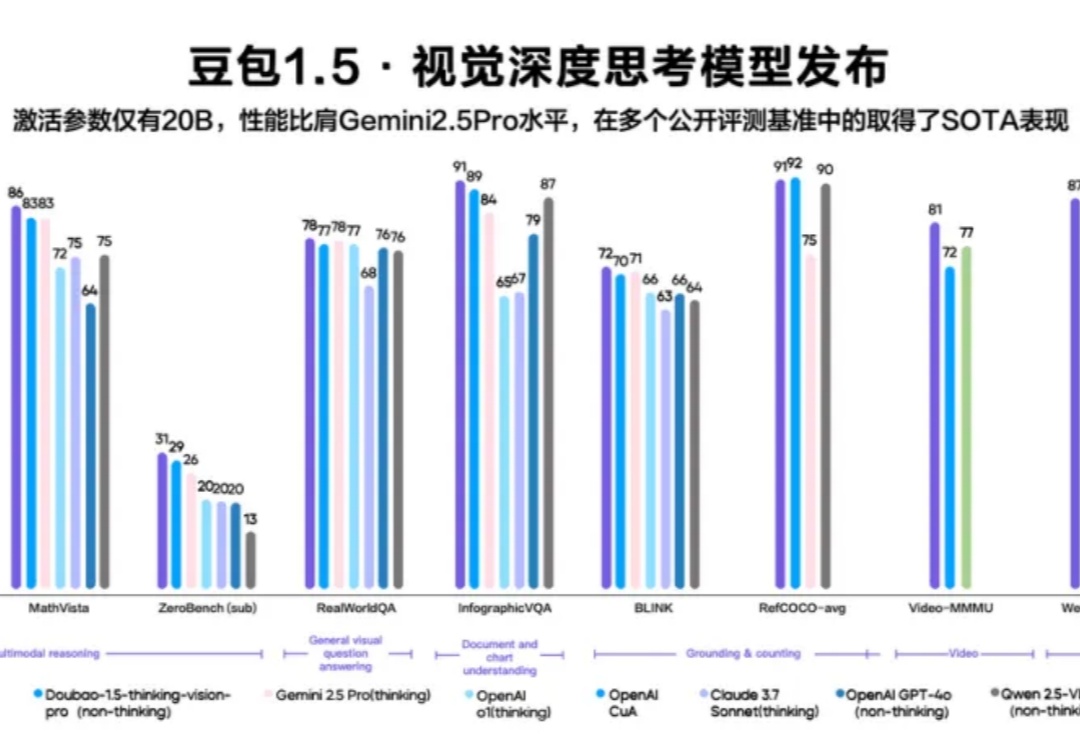
5月13日,在 FORCE LINK AI 创新巡展·上海站,火山引擎发布豆包·视频生成模型 Seedance 1.0 lite、豆包1.5·视觉深度思考模型,升级豆包·音乐模型。同时,Data Agent 正式亮相、Trae 接入豆包深度思考模型并全新升级。火山引擎正在以更强大的模型矩阵、更丰富的智能体工具,帮助企业打通从业务到智能体的应用链路。
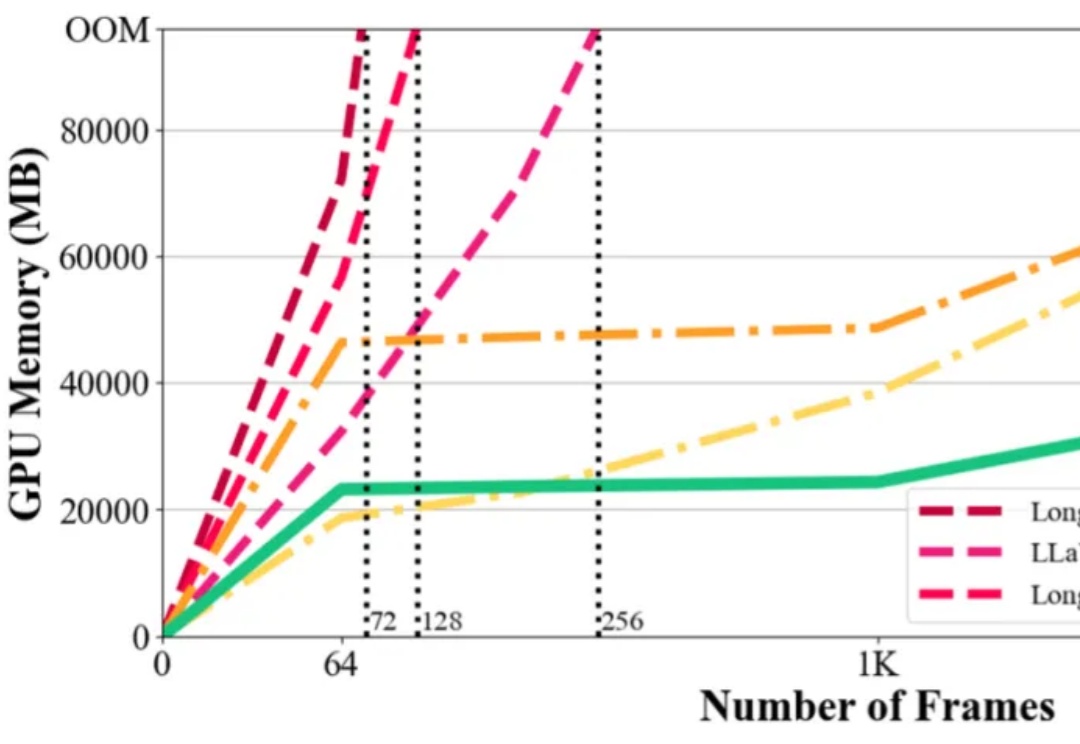
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。

最近我们AI爱好者的群里玩的全都是豆包和即梦生成的海报图片,大家评价做图片和海报效果真的很不错,豆包进步了,即梦也进步了。真的进步太大了!下面是我的朋友们尝试过的一些趣味玩法:

最近阿里通义实验室应用视觉团队负责人薄列峰被曝离职,引起了一轮热议。而这已是继2月语音团队负责人鄢志杰、2024年8月大模型技术负责人周畅之后,阿里AI核心部门第三次失去关键人物了。
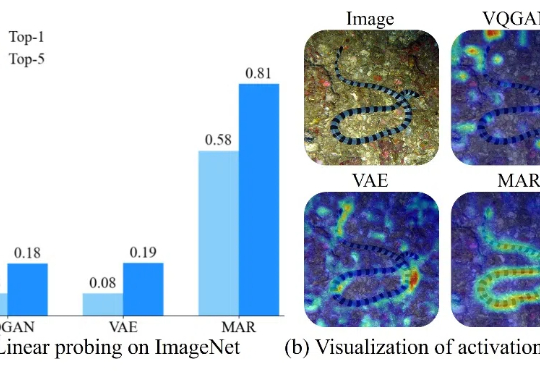
GPT-4o 生图功能的出现揭示了统一理解与生成模型的巨大潜力,然而如何在同一个框架内协调图像理解与生成这两种不同粒度的任务,是一个巨大的挑战。

谷歌Gemini 2.5 Pro(I/O版)横空出世,强势登顶LMAreana,斩获文本、视觉、编码三连冠,甚至编程能力全面碾压Claude 3.7,地表最强编码模型诞生。

在复杂、未知的现实环境中,传统导航方法往往依赖闭集语义或事先构建的地图,难以实现真正的“按需探索”。为打破这一瓶颈,本文提出了 FindAnything ——一套融合视觉语言模型的对象为中心、开放词汇三维建图与探索系统。

从单张低分辨率(LR)图像恢复出高分辨率(HR)图像 —— 即 “超分辨率”(SR)—— 已成为计算机视觉领域的重要挑战。

Hi,我想先请你只看下面这张照片,推测它的拍摄城市: