CVPR 2025 | CV 微调卷出天际,Mona:我小、我强、我省资源
CVPR 2025 | CV 微调卷出天际,Mona:我小、我强、我省资源Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。
来自主题: AI技术研报
9578 点击 2025-05-02 14:17
 搜索
搜索
Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。
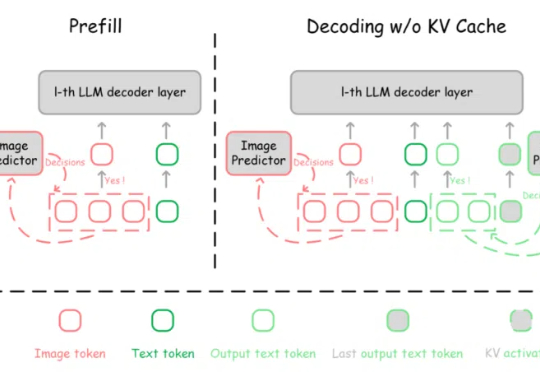
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。
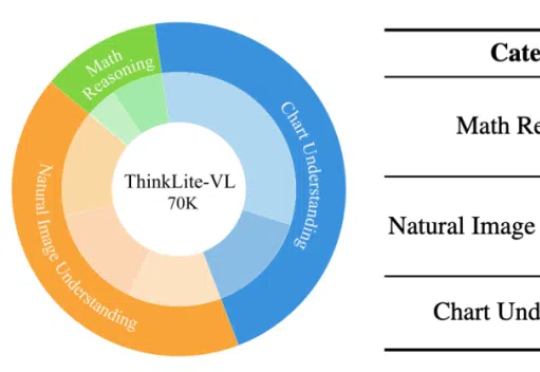
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
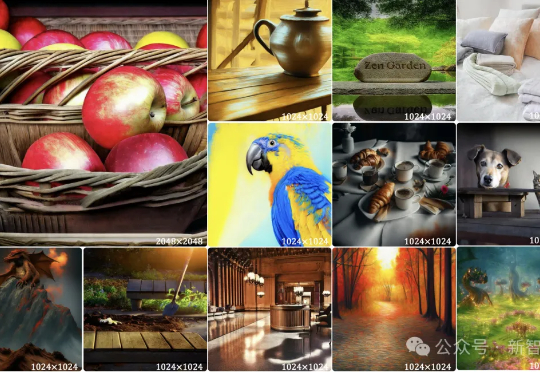
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。

视觉AI终极突破来了!英伟达等机构推出超强多模态模型DAM,仅3B参数,就能精准描述图像和视频中的任何细节。刚刚,英伟达联手UC伯克利、UCSF团队祭出首个神级多模态模型——Describe Anything Model(DAM),仅3B参数。
这里介绍一下Vidu,Vidu是由生数科技联合清华大学正式发布的中国首个长时长、高一致性、高动态性视频大模型。Vidu在语义理解、推理速度、动态幅度等方面具备领先优势,并上线了全球首个“多主体参考”功能,突破视频模型一致性生成难题,开启了视觉上下文时代。最近上线了 Vidu Q1 的高质量视频大模型,不仅视频效果质感更高,而且性价比很不错。
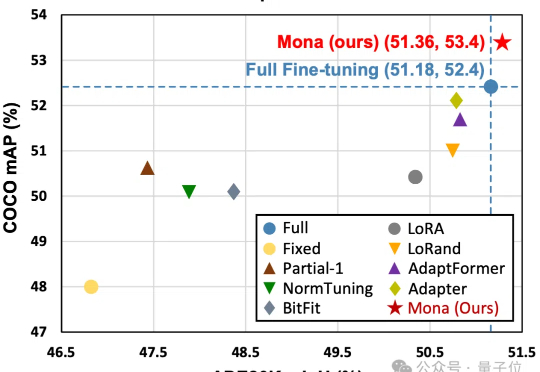
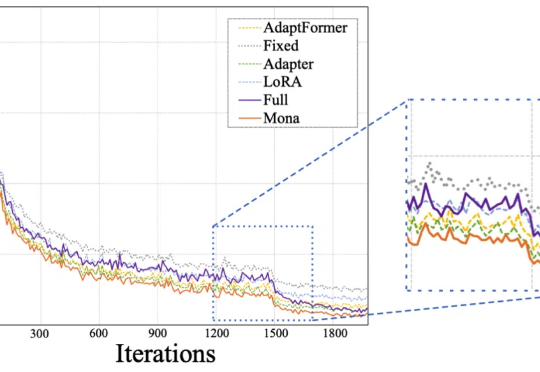
仅调整5%的骨干网络参数,就能超越全参数微调效果?!

算力砍半,视觉生成任务依然SOTA!

复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。
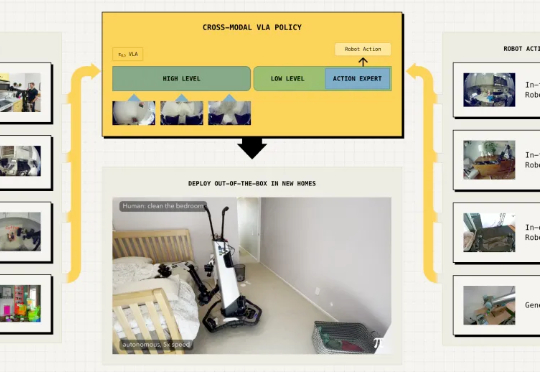
今天,美国具身智能公司 Physical Intelligence 推出了一个基于 π0 的视觉-语言-动作(VLA)模型 π0.5,其利用异构任务的协同训练来实现广泛的泛化,可以在全新的家中执行各种任务。